A ComfyUI custom node that loads and applies B-LoRA models.
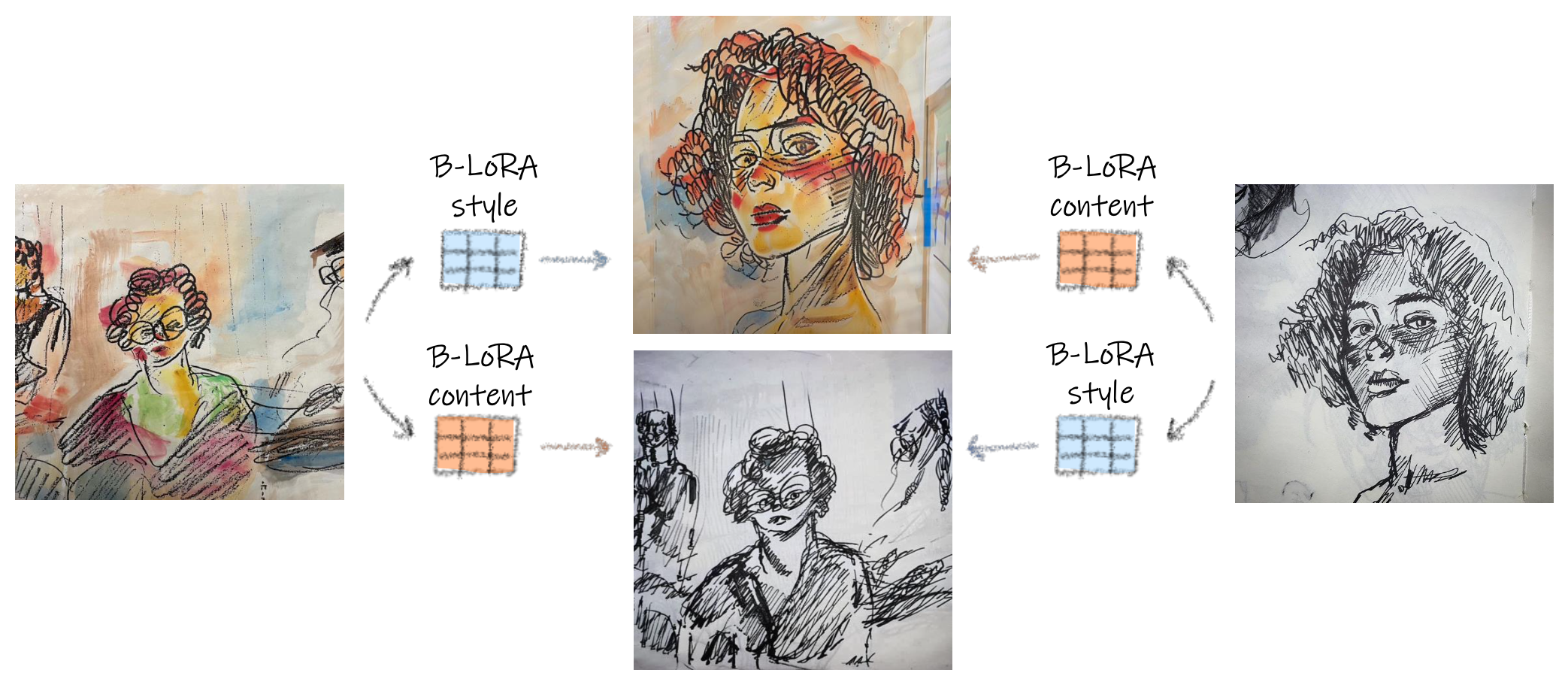

B-LoRA: By implicitly decomposing a single image into its style and content representation captured by B-LoRA, we can perform high quality style-content mixing and even swapping the style and content between two stylized images.
-
🌐 Website: https://b-lora.github.io/B-LoRA/
-
Currently B-LoRA models only works with SDXL (
sdxl_base_1.0). (Compatible but not guaranteed with SDXL-based fine-tuned models.)
-
Can apply
StyleorContent, or both. -
Much smaller model files. (~100M for SDXL B-LoRAs)
-
One B-LoRA only needs one image as training dataset and 15 minutes to train. (on a single RTX 4090)
Please share your B-LoRA models on Civit.ai or HuggingFace!

-
lora_name: Choose the B-LoRA model you want to load. By default, it'll searches in themodels/loras/folder for available models. -
load_style: Do you want the style of that B-LoRA? -
load_content: Do you want to content of that B-LoRA? -
strength: How strong do you want that B-LoRA to affect the model?
 🌟
🌟 <s> is the training prompt for one B-Lora colorful-squirrel
 🌟
🌟 <s> is the training prompt for one B-Lora colorful-squirrel, and <p> is the training prompt for the other pencil-boy.
https://huggingface.co/sida/B-LoRA-examples/tree/main
https://huggingface.co/lora-library?sort_models=downloads#models
I'm building a docker image for training. Please check train to see current progress.
If you use B-LoRA in your research, please cite the authors' paper:
@misc{frenkel2024implicit,
title={Implicit Style-Content Separation using B-LoRA},
author={Yarden Frenkel and Yael Vinker and Ariel Shamir and Daniel Cohen-Or},
year={2024},
eprint={2403.14572},
archivePrefix={arXiv},
primaryClass={cs.CV}
}