NeurIPS 2024
Linhui Xiao
·
Xiaoshan Yang
·
Fang Peng
·
Yaowei Wang
·
Changsheng Xu
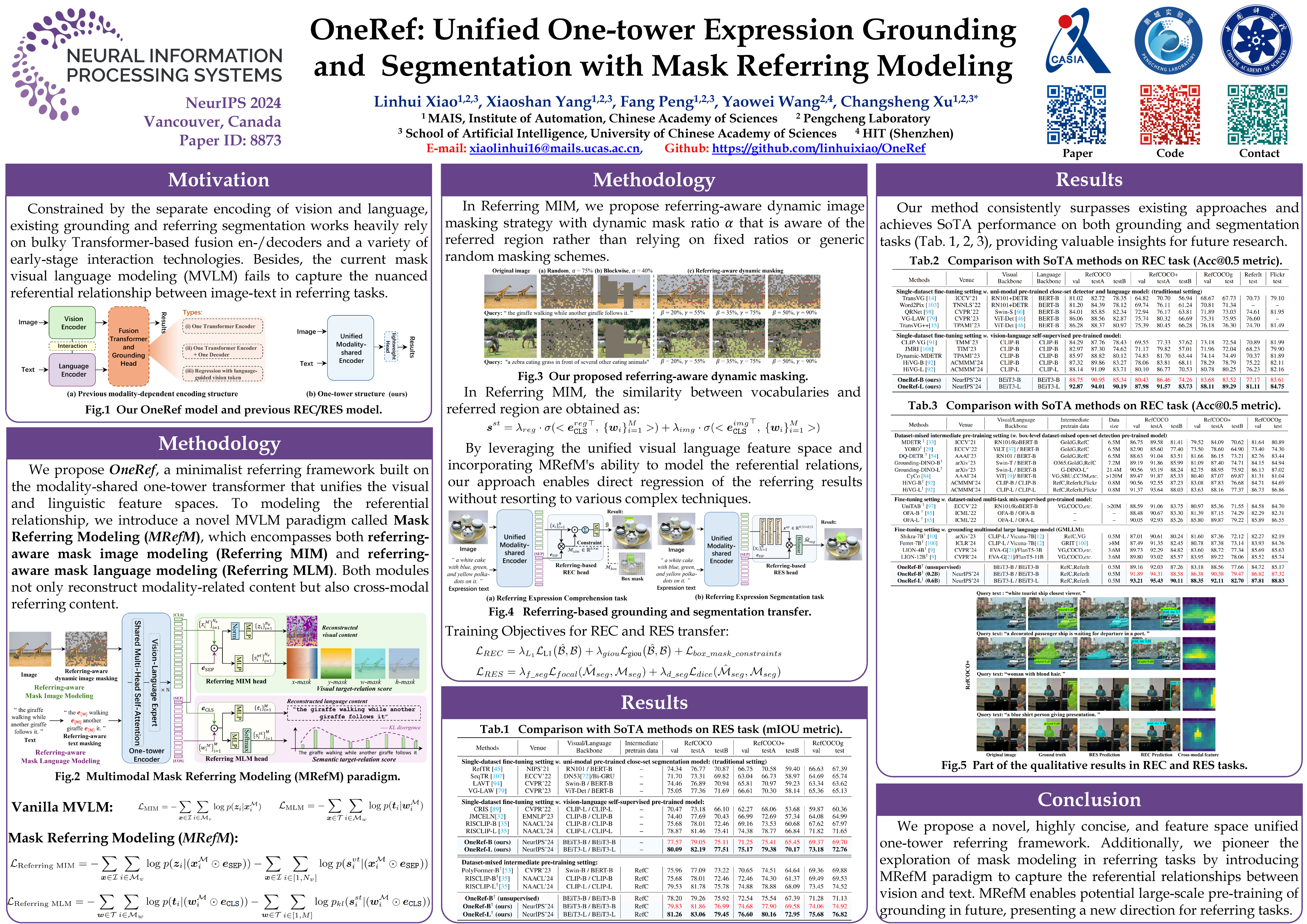

A Comparison between OneRef model and the mainstream REC/RES architectures.
This repository is the official Pytorch implementation for the paper OneRef: Unified One-tower Expression Grounding and Segmentation with Mask Referring Modeling, which is an advanced version of our preliminary work HiVG (Publication, Paper, Code) and CLIP-VG (Publication, Paper, Code).
If you have any questions, please feel free to open an issue or contact me with emails: [email protected]. Any kind discussions are welcomed!
Please leave a STAR ⭐ if you like this project!
- All of the code and models will be released soon!
- 🔥 Update on 2024/12/28: We conducted a survey of Visual Grounding over the past decade, entitled "Towards Visual Grounding: A Survey" (Paper, Project), Comments are welcome !!!
- 🔥 Update on 2024/10/10: Our new work OneRef has been accepted by the top conference NeurIPS 2024 ! (paper, github)
- Update on 2024/07/16: Our grounding work HiVG (Publication, Paper, Code) has been accepted by the top conference ACM MM 2024 !
- Update on 2023/9/25: Our grounding work CLIP-VG has been accepted by the top journal IEEE Transaction on Multimedia (2023)! (paper, github)
If you find our work helpful for your research, please consider citing the following BibTeX entry.
@inproceedings{xiao2024oneref,
title={OneRef: Unified One-tower Expression Grounding and Segmentation with Mask Referring Modeling},
author={Xiao, Linhui and Yang, Xiaoshan and Peng, Fang and Wang, Yaowei and Xu, Changsheng},
booktitle={Proceedings of the 38th International Conference on Neural Information Processing Systems},
year={2024}
}Links: ArXiv, NeurIPS 2024
The code is currently being tidied up, and both the code and model will be made publicly available soon!
- Release all the checkpoints.
- Release the full model code, training and inference code.
- (i) We pioneer the application of mask modeling to referring tasks by introducing a novel paradigm called mask referring modeling. This paradigm effectively models the referential relation between visual and language.
- (ii) Diverging from previous works, we propose a remarkably concise one-tower framework for grounding and referring segmentation in a unified modality-shared feature space. Our model eliminates the commonly used modality interaction modules, modality fusion en-/decoders, and special grounding tokens.
- (iii) We extensively validate the effectiveness of OneRef in three referring tasks on five datasets. Our method consistently surpasses existing approaches and achieves SoTA performance across several settings, providing a valuable new insights for future grounding and referring segmentation research.
Constrained by the separate encoding of vision and language, existing grounding and referring segmentation works heavily rely on bulky Transformer-based fusion en-/decoders and a variety of early-stage interaction technologies. Simultaneously, the current mask visual language modeling (MVLM) fails to capture the nuanced referential relationship between image-text in referring tasks. In this paper, we propose OneRef, a minimalist referring framework built on the modality-shared one-tower transformer that unifies the visual and linguistic feature spaces. To modeling the referential relationship, we introduce a novel MVLM paradigm called Mask Referring Modeling (MRefM), which encompasses both referring-aware mask image modeling and referring-aware mask language modeling. Both modules not only reconstruct modality-related content but also cross-modal referring content. Within MRefM, we propose a referring-aware dynamic image masking strategy that is aware of the referred region rather than relying on fixed ratios or generic random masking schemes. By leveraging the unified visual language feature space and incorporating MRefM’s ability to model the referential relations, our approach enables direct regression of the referring results without resorting to various complex techniques. Our method consistently surpasses existing approaches and achieves SoTA performance on both grounding and segmentation tasks, providing valuable insights for future research.
For more details, please refer to our paper.
- Python 3.9.10
- PyTorch 1.9.0 + cu111 + cp39
- Check requirements.txt for other dependencies.
Our model is easy to deploy in a variety of environments and has been successfully tested on multiple pytorch versions.
1.You can download the images from the original source and place them in your disk folder, such as $/path_to_image_data:
-
MS COCO 2014 (for RefCOCO, RefCOCO+, RefCOCOg dataset, almost 13.0GB)
-
We provide a script to download the mscoco2014 dataset, you just need to run the script in terminal with the following command:
bash download_mscoco2014.shOr you can also follow the data preparation of TransVG, which can be found in GETTING_STARTED.md.
Only the image data in these datasets is used, and these image data is easily find in similar repositories of visual grounding work, such as TransVG etc.
Finally, the $/path_to_image_data folder will have the following structure:
|-- image_data
|-- Flickr30k
|-- flickr30k-images
|-- other
|-- images
|-- mscoco
|-- images
|-- train2014
|-- referit
|-- images
$/path_to_image_data/image_data/Flickr30k/flickr30k-images/: Image data for the Flickr30K dataset, please download from this link. Fill the form and download the images.$/path_to_image_data/image_data/other/images/: Image data for RefCOCO/RefCOCO+/RefCOCOg, i.e., mscoco2014.$/path_to_image_data/image_data/referit/images/: Image data for ReferItGame.
The labels in the fully supervised scenario is consistent with previous works such as TransVG.
| Datasets | RefCOCO | RefCOCO+ | RefCOCOg-g | RefCOCOg-u | ReferIt | Flickr | Mixup1 | Mixup2 |
|---|---|---|---|---|---|---|---|---|
| url, size | All of six datasets, 89.0MB | |||||||
* The mixup1 denotes the mixup of the training data from RefCOCO/+/g-umd (without use gref), which used in RES task. The mixup2 denotes the mixup of the training data from RefCOCO/+/g (without use gref) and ReferIt Game, which used in REC task. The val and test split of both Mixup1 and Mixup2 are used the val and testA file from RefCOCOg. The training data in RefCOCOg-g (i.e., gref) exist data leakage.
Download the above annotations to a disk directory such as $/path_to_split; then will have the following similar directory structure:
|-- /full_sup_data
├── flickr
│ ├── flickr_test.pth
│ ├── flickr_train.pth
│ └── flickr_val.pth
├── gref
│ ├── gref_train.pth
│ └── gref_val.pth
├── gref_umd
│ ├── gref_umd_test.pth
│ ├── gref_umd_train.pth
│ └── gref_umd_val.pth
├── mixup1
│ ├── mixup1_test.pth
│ ├── mixup1_train.pth
│ └── mixup1_val.pth
├── mixup2
│ ├── mixup2_test.pth
│ ├── mixup2_train.pth
│ └── mixup2_val.pth
├── referit
│ ├── referit_test.pth
│ ├── referit_train.pth
│ └── referit_val.pth
├── unc
│ ├── unc_testA.pth
│ ├── unc_testB.pth
│ ├── unc_train.pth
│ └── unc_val.pth
└── unc+
├── unc+_testA.pth
├── unc+_testB.pth
├── unc+_train.pth
└── unc+_val.pth
| Datasets | RefCOCO | RefCOCO+ | RefCOCOg-g | RefCOCOg-u | ReferIt | Flickr |
|---|---|---|---|---|---|---|
| separate | model | model | model | model | model | model |
| url, size | All of six models (All have not ready) | |||||
The checkpoints include the Base model and Large mode under the fine-tuning setting and dataset-mixed pretraining setting.
You just only need to change $/path_to_split, $/path_to_image_data, $/path_to_output to your own file directory to execute the following command.
The first time we run the command below, it will take some time for the repository to download the CLIP model.
-
Training on RefCOCO with fully supervised setting. The only difference is an additional control flag:
--sup_type fullCUDA_VISIBLE_DEVICES=3,4,5,6,7 python -m torch.distributed.launch --nproc_per_node=5 --master_port 28887 --use_env train_clip_vg.py --num_workers 32 --epochs 120 --batch_size 64 --lr 0.00025 --lr_scheduler cosine --aug_crop --aug_scale --aug_translate --imsize 224 --max_query_len 77 --sup_type full --dataset unc --data_root $/path_to_image_data --split_root $/path_to_split --output_dir $/path_to_output/output_v01/unc;Please refer to train_and_eval_script/train_and_eval_full_sup.sh for training commands on other datasets.
-
Evaluation on RefCOCO. The instructions are the same for the fully supervised Settings.
CUDA_VISIBLE_DEVICES=2,3,4,5,6,7 python -m torch.distributed.launch --nproc_per_node=6 --master_port 28888 --use_env eval.py --num_workers 2 --batch_size 128 --dataset unc --imsize 224 --max_query_len 77 --data_root $/path_to_image_data --split_root $/path_to_split --eval_model $/path_to_output/output_v01/unc/best_checkpoint.pth --eval_set val --output_dir $/path_to_output/output_v01/unc;Please refer to train_and_eval_script/train_and_eval_unsup.sh for evaluation commands on other splits or datasets.
-
We strongly recommend to use the following commands to training or testing with different datasets and splits, which will significant reduce the training workforce.
bash train_and_eval_script/train_and_eval_full_sup.sh
REC Single-dataset Fine-tuning SoTA Result Table

REC Dataset-mixed Pretraining SoTA Result Table

RES Single-dataset Fine-tuning and Dataset-mixed Pretraining SoTA Result Table (mIoU)

RES Single-dataset Fine-tuning and Dataset-mixed Pretraining SoTA Result Table (oIoU)

Comparison of the computational cost in REC task.


An Illustration of our multimodal Mask Referring Modeling (MRefM) paradigm, which includes Referring-aware mask image modeling and Referring-aware mask language modeling.

An Illustration of the referring-based grounding and segmentation transfer.

Illustrations of random masking (MAE) [27], block-wise masking (BEiT) [4], and our referring-aware dynamic masking. α denotes the entire masking ratio, while β and γ denote the masking ratio beyond and within the referred region.

Qualitative results on the RefCOCO-val dataset.

Qualitative results on the RefCOCO+-val dataset.

Qualitative results on the RefCOCOg-val dataset.
Each example shows two different query texts. From left to right: the original input image, the ground truth with box and segmentation mask (in green), the RES prediction of OneRef (in cyan), the REC prediction of OneRef (in cyan), and the cross-modal feature.
Email: [email protected]. Any kind discussions are welcomed!
Our model is related to BEiT-3 and MAE. Thanks for their great work!
We also thank the great previous work including TransVG, DETR, CLIP, CLIP-VG, etc.
Thanks Microsoft for their awesome models.