Add Topology Manager proposal. #1680
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,281 @@ | ||
| # NUMA Manager | ||
|
|
||
| _Authors:_ | ||
|
|
||
| * @ConnorDoyle - Connor Doyle <[email protected]> | ||
| * @balajismaniam - Balaji Subramaniam <[email protected]> | ||
| * @lmdaly - Louise M. Daly <[email protected]> | ||
|
|
||
| **Contents:** | ||
|
|
||
| * [Overview](#overview) | ||
| * [Motivation](#motivation) | ||
| * [Goals](#goals) | ||
| * [Non-Goals](#non-goals) | ||
| * [User Stories](#user-stories) | ||
| * [Proposal](#proposal) | ||
| * [User Stories](#user-stories) | ||
| * [Proposed Changes](#proposed-changes) | ||
| * [New Component: NUMA Manager](#new-component-numa-manager) | ||
| * [Computing Preferred Affinity](#computing-preferred-affinity) | ||
| * [New Interfaces](#new-interfaces) | ||
| * [Changes to Existing Components](#changes-to-existing-components) | ||
| * [Graduation Criteria](#graduation-criteria) | ||
| * [alpha (target v1.11)](#alpha-target-v1.11) | ||
| * [beta](#beta) | ||
| * [GA (stable)](#ga-stable) | ||
| * [Challenges](#challenges) | ||
| * [Limitations](#limitations) | ||
| * [Alternatives](#alternatives) | ||
| * [Reference](#reference) | ||
|
|
||
| # Overview | ||
|
|
||
| An increasing number of systems leverage a combination of CPUs and | ||
| hardware accelerators to support latency-critical execution and | ||
| high-throughput parallel computation. These include workloads in fields | ||
| such as telecommunications, scientific computing, machine learning, | ||
| financial services and data analytics. Such hybrid systems comprise a | ||
| high performance environment. | ||
|
|
||
| In order to extract the best performance, optimizations related to CPU | ||
| isolation and memory and device locality are required. However, in | ||
| Kubernetes, these optimizations are handled by a disjoint set of | ||
| components. | ||
|
|
||
| This proposal provides a mechanism to coordinate fine-grained hardware | ||
| resource assignments for different components in Kubernetes. | ||
|
|
||
|
|
||
| # Motivation | ||
|
|
||
| Multiple components in the Kubelet make decisions about system | ||
| topology-related assignments: | ||
|
|
||
| - CPU manager | ||
| - The CPU manager makes decisions about the set of CPUs a container is | ||
| allowed to run on. The only implemented policy as of v1.8 is the static | ||
| one, which does not change assignments for the lifetime of a container. | ||
| - Device manager | ||
| - The device manager makes concrete device assignments to satisfy | ||
| container resource requirements. Generally devices are attached to one | ||
| peripheral interconnect. If the device manager and the CPU manager are | ||
| misaligned, all communication between the CPU and the device can incur | ||
| an additional hop over the processor interconnect fabric. | ||
| - Container Network Interface (CNI) | ||
| - NICs including SR-IOV Virtual Functions have affinity to one NUMA node, | ||
| with measurable performance ramifications. | ||
|
|
||
| *Related Issues:* | ||
|
|
||
| - [Hardware topology awareness at node level (including NUMA)][k8s-issue-49964] | ||
| - [Discover nodes with NUMA architecture][nfd-issue-84] | ||
| - [Support VF interrupt binding to specified CPU][sriov-issue-10] | ||
| - [Proposal: CPU Affinity and NUMA Topology Awareness][proposal-affinity] | ||
|
|
||
| Note that all of these concerns pertain only to multi-socket systems. | ||
|
There was a problem hiding this comment. Correct behavior requires that the kernel receive accurate topology information from the underlying hardware (typically via the SLIT table). See section 5.2.16 and 5.2.17 of the ACPI Specification http://www.acpi.info/DOWNLOADS/ACPIspec50.pdf for more information. |
||
|
|
||
| ## Goals | ||
|
|
||
| - Allow CPU manager and Device Manager to agree on preferred | ||
| NUMA node affinity for containers. | ||
ConnorDoyle marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| - Provide an internal interface and pattern to integrate additional | ||
| topology-aware Kubelet components. | ||
|
|
||
| ## Non-Goals | ||
|
|
||
| - _Inter-device connectivity:_ Decide device assignments based on direct | ||
| device interconnects. This issue can be separated from NUMA node | ||
| locality. Inter-device topology can be considered entirely within the | ||
| scope of the Device Manager, after which it can emit possible | ||
| NUMA affinities. The policy to reach that decision can start simple | ||
| and iterate to include support for arbitrary inter-device graphs. | ||
| - _HugePages:_ This proposal assumes that pre-allocated HugePages are | ||
| spread among the available NUMA nodes in the system. We further assume | ||
| the operating system provides best-effort local page allocation for | ||
| containers (as long as sufficient HugePages are free on the local NUMA | ||
| node. | ||
|
There was a problem hiding this comment. Future addition could be to extend cAdvisor to advertise huge pages available per NUMA node, enabling NUMA Manager to take huge pages available on each node into account when calculating NUMA node affinity There was a problem hiding this comment. Hm, good point! Want to add that as something we can do for beta? Just send a PR against my branch. There was a problem hiding this comment. I think I would prefer to start simple on hugepages behavior. For roadmap, I don’t think anything special would be needed for alpha or even beta. There was a problem hiding this comment. Added hugepages alignnment to the beta graduation criteria. If it's the case that no action is required (per performance test results) then it can be marked done via proper documentation of that fact. There was a problem hiding this comment. Considering that my colleagues already tested their DPDK based workload on vanilla(ish) kubernetes with CPUs and SRIOV VFs manually aligned, then observed that their unaligned hugepages caused additional packet processing delays in the 100ms range, I think we don't need to worry about extra documentation :) There was a problem hiding this comment. in our lab, with our 4G "Cloudified" BTS application. exact test setup, and measurements probably I can get, the test probably I cannot reproduce within the community for obvious (SW licence :) ) reasons but I'm fairly sure the same can be easily reproduced with testPMD too (I didn't put effort into it though, so it is just an assumption from my side) |
||
| - _CNI:_ Changing the Container Networking Interface is out of scope for | ||
|
There was a problem hiding this comment. if I may chime-in from Nokia, representing the often-quoted "NFVI use-cases" :) To put the question into context: in a performance sensitive VNF one of the main requirement is to 1: have isolated (what this means exactly is a topic of another discussion), exclusive CPU(s) allocated to a Pod 2: said CPU(s) shall belong to the same NUMA node as the network devices used by the Pod Most of these management tasks are handled by CNI plugins, namely SRIOV (either huscat's or Intel's DPDK capable fork), vhostuser plugin, or any other proprietary CNI implementation. The way how the Device Manager proposal shares devices (through their Unix socket) does not necessarily make it compatible with NFVI requirements, which in turn raises the question that how can be the current NUMA manager proposal enhanced to satisfy above requirements if the DeviceManager does not, or cannot play a role in these use-cases? So, trying to distill this train of thought into two short questions, or even additional requirements:
|
||
| this proposal. However, this design should be extensible enough to | ||
| accommodate network interface locality if the CNI adds support in the | ||
| future. This limitation is potentially mitigated by the possiblity to | ||
ConnorDoyle marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| use the device plugin API as a stopgap solution for specialized | ||
| networking requirements. | ||
|
|
||
| ## User Stories | ||
|
|
||
| *Story 1: Fast virtualized network functions* | ||
|
|
||
| A user asks for a "fast network" and automatically gets all the various | ||
| pieces coordinated (hugepages, cpusets, network device) co-located on a | ||
| NUMA node. | ||
|
|
||
| *Story 2: Accelerated neural network training* | ||
|
|
||
| A user asks for an accelerator device and some number of exclusive CPUs | ||
| in order to get the best training performance, due to NUMA-alignment of | ||
| the assigned CPUs and devices. | ||
|
|
||
| # Proposal | ||
|
|
||
| *Main idea: Two Phase NUMA coherence protocol* | ||
|
|
||
| NUMA affinity is tracked at the container level, similar to devices and | ||
| CPU affinity. At pod admission time, a new component called the NUMA Manager | ||
| collects possible NUMA configurations from the Device Manager and the | ||
| CPU Manager. The NUMA manager acts as an oracle for NUMA node affinity by | ||
| those same components when they make concrete resource allocations. We | ||
| expect the consulted components to use the inferred QoS class of each | ||
| pod in order to prioritize the importance of fulfilling optimal NUMA | ||
| affinity. | ||
ConnorDoyle marked this conversation as resolved.
Show resolved
Hide resolved
|
||
|
|
||
| ## Proposed Changes | ||
|
|
||
| ### New Component: NUMA Manager | ||
|
|
||
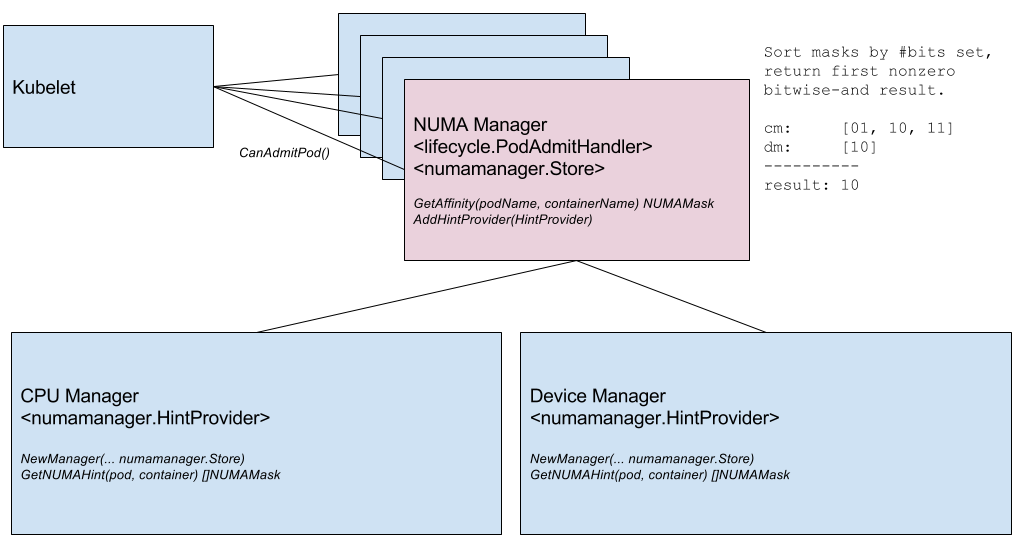
| This proposal is focused on a new component in the Kubelet called the | ||
| NUMA Manager. The NUMA Manager implements the pod admit handler | ||
| interface and participates in Kubelet pod admission. When the `Admit()` | ||
| function is called, the NUMA manager collects NUMA hints from from other | ||
ConnorDoyle marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| Kubelet components. | ||
|
|
||
| If the NUMA hints are not compatible, the NUMA manager could choose to | ||
| reject the pod. The details of what to do in this situation needs more | ||
ConnorDoyle marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| discussion. For example, the NUMA manager could enforce strict NUMA | ||
| alignment for Guaranteed QoS pods. Alternatively, the NUMA manager could | ||
ConnorDoyle marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| simply provide best-effort NUMA alignment for all pods. | ||
|
|
||
| The NUMA Manager component will be disabled behind a feature gate until | ||
|
There was a problem hiding this comment. Is the NUMA manager only relevant in its first iteration if static cpu policy is enabled? There was a problem hiding this comment. Practically speaking, yes.
We wanted to start with this narrow use case, but at the same time define a lightweight internal API for other NUMA concerns. There was a problem hiding this comment. It might seem narrow. But this opens up use of Kubernetes to a chunk of use-cases that are already in production on other platforms. |
||
| graduation from alpha to beta. | ||
|
|
||
| #### Computing Preferred Affinity | ||
|
|
||
| A NUMA hint is a list of possible NUMA node masks. After collecting hints | ||
| from all providers, the NUMA Manager must choose some mask that is | ||
| present in all lists. Here is a sketch: | ||
|
|
||
| 1. Apply a partial order on each list: number of bits set in the | ||
| mask, ascending. This biases the result to be more precise if | ||
| possible. | ||
| 1. Iterate over the permutations of preference lists and compute | ||
| bitwise-and over the masks in each permutation. | ||
| 1. Store the first non-empty result and break out early. | ||
| 1. If no non-empty result exists, return an error. | ||
|
There was a problem hiding this comment. Should an error be returned in the case of non-strict numa assignment? There was a problem hiding this comment. In my opinion non-strict assignment is still non-erroneous operation unless user indicates that strict assignment is required. There was a problem hiding this comment. Where's the note that users can select strict vs preferred? I didn't see it. There was a problem hiding this comment. I don't think it's called out specifically - but I think a Kubelet flag for strict/preferred NUMA alignment could be useful. Some users may want to fail guaranteed pods if they cannot get NUMA affinity across resources, whereas some may want the pod to run regardless - with a preference for NUMA affinity where possible. There was a problem hiding this comment. Maybe a new pod annotation like kubernetes.io/RequireStrictNUMAAlignment ? The NUMA manager rejects a pod only when the pod has the annotation and NUMA manager cannot find a strict NUMA assignment for it. There was a problem hiding this comment. Added a note on opting in to strict mode. |
||
|
|
||
| #### New Interfaces | ||
|
|
||
| ```go | ||
| package numamanager | ||
|
|
||
| // NUMAManager helps to coordinate NUMA-related resource assignments | ||
| // within the Kubelet. | ||
| type Manager interface { | ||
| lifecycle.PodAdmitHandler | ||
| Store | ||
| AddHintProvider(HintProvider) | ||
| RemovePod(podName string) | ||
| } | ||
|
|
||
| // NUMAMask is a bitmask-like type denoting a subset of available NUMA nodes. | ||
| type NUMAMask struct{} // TBD | ||
|
|
||
| // NUMAStore manages state related to the NUMA manager. | ||
| type Store interface { | ||
| // GetAffinity returns the preferred NUMA affinity for the supplied | ||
| // pod and container. | ||
| GetAffinity(podName string, containerName string) NUMAMask | ||
| } | ||
|
|
||
| // HintProvider is implemented by Kubelet components that make | ||
| // NUMA-related resource assignments. The NUMA manager consults each | ||
| // hint provider at pod admission time. | ||
| type HintProvider interface { | ||
| GetNUMAHints(pod v1.Pod, containerName string) []NUMAMask | ||
|
There was a problem hiding this comment. When There was a problem hiding this comment. Perhaps: GetNUMAHints(pod v1.Pod, containerName string) []NUMAMask, boolThere was a problem hiding this comment. So, you'd return There was a problem hiding this comment. We were just having a discussion about it with @ppalucki and we believe that there are following options:
Making a good choice here is about developer experience, I think - we should make the interface as straightforward to implement as possible. |
||
| } | ||
| ``` | ||
|
|
||
| _NUMA Manager and related interfaces (sketch)._ | ||
|
|
||
|  | ||
|
|
||
| _NUMA Manager components._ | ||
|
|
||
|  | ||
|
|
||
| _NUMA Manager instantiation and inclusion in pod admit lifecycle._ | ||
|
|
||
| ### Changes to Existing Components | ||
|
|
||
| 1. Kubelet consults NUMA Manager for pod admission (discussed above.) | ||
| 1. Add two implementations of NUMA Manager interface and a feature gate. | ||
| 1. As much NUMA Manager functionality as possible is stubbed when the | ||
| feature gate is disabled. | ||
| 1. Add a functional NUMA manager that queries hint providers in order | ||
| to compute a preferred NUMA node mask for each container. | ||
| 1. Add `GetNUMAHints()` method to CPU Manager. | ||
| 1. CPU Manager static policy calls `GetAffinity()` method of NUMA | ||
| manager when deciding CPU affinity. | ||
| 1. Add `GetNUMAHints()` method to Device Manager. | ||
| 1. Add NUMA Node ID to Device structure in the device plugin | ||
ConnorDoyle marked this conversation as resolved.
Show resolved
Hide resolved
There was a problem hiding this comment. What does NUMA Manager do if there is only one NUMA node? There was a problem hiding this comment. Two options for this could be:
|
||
| interface. Plugins should be able to determine the NUMA node | ||
| easily when enumerating supported devices. For example, Linux | ||
| exposes the node ID in sysfs for PCI devices: | ||
| `/sys/devices/pci*/*/numa_node`. | ||
ConnorDoyle marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| 1. Device Manager calls `GetAffinity()` method of NUMA manager when | ||
|
There was a problem hiding this comment. Not sure if this is out of scope: For Device Manager, if available NUMA hints returned here, it means we have enough devices for the container, and preparatory work has already been completed. Thus, we may need to consider the relationship between things we do here and that of There was a problem hiding this comment. Great point. Here are two options:
|
||
| deciding device allocation. | ||
|
|
||
|  | ||
|
|
||
| _NUMA Manager hint provider registration._ | ||
|
|
||
|  | ||
|
|
||
| _NUMA Manager fetches affinity from hint providers._ | ||
|
|
||
| # Graduation Criteria | ||
|
|
||
| ## Alpha (target v1.11) | ||
|
|
||
| * Feature gate is disabled by default. | ||
| * Alpha-level documentation. | ||
| * Unit test coverage. | ||
| * CPU Manager allocation policy takes NUMA hints into account. | ||
| * Device plugin interface includes NUMA node ID. | ||
| * Device Manager allocation policy takes NUMA hints into account. | ||
|
|
||
| ## Beta | ||
|
|
||
| * Feature gate is enabled by default. | ||
| * Alpha-level documentation. | ||
| * Node e2e tests. | ||
| * User feedback. | ||
|
|
||
| ## GA (stable) | ||
|
|
||
| * *TBD* | ||
|
|
||
| # Challenges | ||
|
|
||
| * Testing the NUMA Manager in a continuous integration environment | ||
| depends on cloud infrastructure to expose multi-node NUMA topologies | ||
| to guest virtual machines. | ||
| * Implementing the `GetNUMAHints()` interface may prove challenging. | ||
|
|
||
| # Limitations | ||
|
|
||
| * *TBD* | ||
ConnorDoyle marked this conversation as resolved.
Show resolved
Hide resolved
|
||
|
|
||
| # Alternatives | ||
|
|
||
| * [AutoNUMA][numa-challenges]: This kernel feature affects memory | ||
|
There was a problem hiding this comment. I'd like to see the performance of autonuma with CPU affinity before adding support for explicit NUMA node pinning. There was a problem hiding this comment. Hello @vishh ! I looked a bit into autonuma as I wasn't aware of it, from what I understand of it:
It seems to me that what it is trying to solve is maximizing locality of CPU node and Memory, which might be a good thing for certain use cases of this design but wouldn't solve the problem for devices as they are "sending" memory from the NUMA node to the device. Please correct me if I misunderstood something :) There was a problem hiding this comment. as soon as a process is launched with sched_setaffinity, autonuma no longer pays attention to those pids. IOW cpumanager disables autonuma for the pids in that cgroup. There was a problem hiding this comment.
We don't yet have a way to know what NUMA node devices live on, or align that with CPU affinity. I agree with the above, but the precondition is what this proposal tries to address. We're still not suggesting to configure |
||
| allocation and thread scheduling, but does not address device locality. | ||
|
|
||
ConnorDoyle marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| # References | ||
|
|
||
| * *TBD* | ||
|
|
||
| [k8s-issue-49964]: https://github.com/kubernetes/kubernetes/issues/49964 | ||
| [nfd-issue-84]: https://github.com/kubernetes-incubator/node-feature-discovery/issues/84 | ||
| [sriov-issue-10]: https://github.com/hustcat/sriov-cni/issues/10 | ||
| [proposal-affinity]: https://github.com/kubernetes/community/pull/171 | ||
| [numa-challenges]: https://queue.acm.org/detail.cfm?id=2852078 | ||
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
okay, so as a result of our offline discussion I was asked to post the streamlined NFVI requirements to the proposal
Following RQs should be added to the proposal for it to be able to serve NFVI needs (mainly mobile networks radio VNFs which need these high-performance optimizations)
RQ1: NUMA manager shall gather hints from (selected) CNI plugins before/during admission
Use-case: must have for DPDK user-space networking Pods, using e.g. SRIOV, vhostuser etc. CNI to setup their networks. Otherwise application will experience serious performance drop.
Note, that reaching certain performance thresholds is a mandatory, functional requirement for such NFVI applications
Comment: a possible, Device Plugin / Device Manager based "workaround" solution was discussed regarding the SRIOV CNI plugin. This generic proposal should at least outline how this interaction is imagined to be implemented in Kubernetes, showing an exact example (it can be the SRIOV CNI).
Implementation shall consider this requirement as mandatory right from the beginning (in case community considers running NFVI workloads as high-priority), otherwise NFVI radio applications can't use Kubernetes in production (or cluster admin needs to implement non-Kubernetes based workarounds for this situation)
RQ2: Hugepages shall be allocated from the same NUMA node as NICs and exclusive CPUs
Use-case: also a must have for DPDK user-space networking Pods. Such application experience serious performance drop today due to this missing feature (scenario is real-life tested).
Note, that reaching certain performance thresholds is a mandatory, functional requirement for such NFVI applications
Comment: some discussions happened in the comment section regarding this feature, bit it needs to be included in the proposal as a functional requirements. The implementation plan realizing this requirements should be crisply outlined, and follow-up design plans formulated (if needed, for example about the creation of a MemoryManager component)
Implementation shall consider this requirement as mandatory right from the beginning (in case community considers running NFVI workloads as high-priority), otherwise NFVI radio applications can't use Kubernetes in production (or cluster admin needs to implement non-Kubernetes based workarounds for this situation)
+1: other offline identified NFVI requirements regarding CPU manager (e.g. CPU pooling etc.), and networking (e.g. true multi-interfaces support etc.) will be posted / discussed separately
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Added hugepages alignment to graduation criteria for beta.