CPU and memory usage of k3s #2278
Comments
|
Duplicate #294 ...This is a known issue for some people |
|
Thanks for the duplicate, I didn't see it. They are more looking at CPU usage than memory usage whereas both are important on low power embedded computers. And what seems important to me is why this consumption of resources when k3s is idle without any running pod? |
|
From my point of view it is valid to have a new issue because the old one is closed without any solution. Especially if you think about the primary use case which is a low powered edge case computing setup. Fixing or even responding to this issue should be a top priority for the k3s team. |
|
500MB of RAM and 5% cpu is about as good as you are going to get for an entire Kubernetes cluster + infrastructure pods running on a single node. What about this would you like to see fixed? Do you have an example of another Kubernetes distribution that offers similar features in a smaller footprint? |
|
500MB of RAM and 5% cpu looks fine for me. My own experience is more like this: |
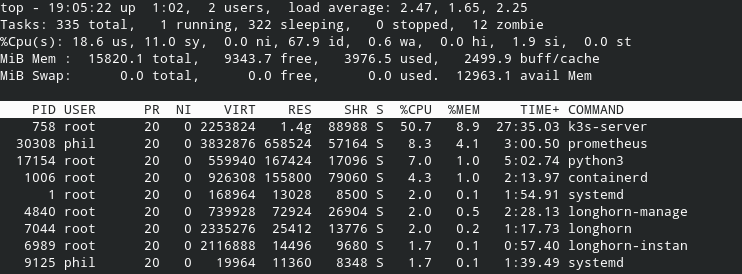
|
Here's a pretty much idle master with no workers and no deployments:
Compared to my master that has 5 workers and about 50 deployments: You can see the active master is jumping from 20%-150%+ sometimes greater than 300% CPU usage on k3s. Something seems off to me, but it's working /shrug |

|
@onedr0p and @runningman84, can you provide the CPU reference of the system? It's looking like you have both system with 16GB memory. In my case, I have only 2GB of memory! |
|
My CPU is |
|
Note that unless your explicitly restrict it, golang will make use of additional memory to avoid having to do garbage collection too frequently. You can reduce the memory utilization at the cost of more aggressive GC cleanup by setting a MemoryLimit in the systemd unit: Other users have similarly put CPU limits on the k3s service, although I personally think that this might have more negative effects (apiserver throttling, etc) than a memory limit. |
That's my mindset too. I do think there is an issue on k3s CPU usage, however, it isn't really affecting me much. Everything seems to be running fine. |
|
I am running an intel n5000 cpu in a msi cubi system. |
|
@runningman84: your k3s is running some pods? 50% CPU usage with Intel N5000 seems a lot when idle if really nothing is running. |
|
I have three nodes running about 100 pods total. The other two nodes with k3s agents have lower cpu usage because my actual workload is not very resource heavy. (Home assistant, mqtt and other small services) If you look at the total cpu time is is strange that value of prometheus is way lower than k3s server. |
|
@runningman84 that's already a nice deployment! When I was thinking at idle, it was also without any deployment! |
|
I would like at least to understand how the CPU and memory resources are used by the k3s-server process as this process is running multiple threads and for me this isn't easy to understand which thread are consuming resources for which task. |
|
I have the exact same issue, My processor is and the main Attaching to it with and it doesn't output anything, which is weird since it's definitely doing something. |
|
Even when kubernetes isn't "doing anything" it is still constantly running control loops to query the state of the system, compare that to the desired state, and determine if anything needs to be changed. It is also constantly health checking endpoints, collecting metrics, renewing locks, etc. It is never truly idle, which is why you will see a baseline amount of CPU usage even without a workload. |
|
@brandond seems like quite a high baseline, no? This isn't a raspberry Pi, It's a decent laptop which runs Java IDEs, etc effortlessly, 10% baseline in "idle" seems high to me. |
|
I'm trying to search where the CPU cycles are going. I have done some tests with the perf tool, running perf tool can provide detailed information, but I'm lacking some symbol information to identify the stack trace in the k3s process. Anyone know how to get symbols? |

|
I'm seeing this behaviour too on my Pi4. Fresh installation with mariadb as external database. Log of a couple of seconds: |
|
Interesting, I know the control loop is checking state to keep it as wanted, but there is maybe some optimization where on low-end systems the intervals can be longer? |
|
These requests are happening all the time, you're seeing them logged because the request latency is over 100ms. This usually means that your database is on slow storage or does not have sufficient cpu. |
|
@brandond: @tim-brand wrote that he has enabled verbose logging, so maybe all the requests are logged even if there are under 100ms response time. |
|
Yes, that's correct, they only get logged when I enable the verbose logging, using |
|
I installed Ubuntu Server with Microk8s, and it's also having a high idle load. From what I can see now the load is a bit lower than with k3s, but still about 1.60 average. |
|
No k3s maintainer can help us on understanding these consumed resources? |
|
Here's what my pi4b looks like with an external MariaDB database backend; I don't have one running with sqlite at the moment. |
That's a good load. I've runned k3s with mariadb myself, but with a much higher idle load. |
|
Also, I've installed "plain" kubernetes on Ubuntu 20.04 at my Pi4b, where I notice also and idle load of about 1.40 resulted by the |
|
I've updated to add some details. I tweaked the fstab mount options and journald settings to reduce writes to the SD card, as well as disabling apparmor and cpu vulnerability mitigations. Not sure how much of a difference that makes, but you might give it a try. |
|
@sraillard This is exactly what surprises me when I read about people using k8s and k3s for IoT/edge projects. The computers we're using at the edge are much less powerful than my laptop. |
I suspect something like this would be the solution |
|
We've added some resource profiling figures to our documentation, feel free to take a look: FWIW, when we talk about edge we usually mean things like cell towers, stores, restaurants, forward operating bases, etc. While K3s has been designed to optimize CPU and memory utilization compared to other Kubernetes distributions, there will probably continue to be many extreme low-end use cases (including mobile, battery-backed operation) in which the overhead of a complex control plane is not desirable. |
|
Excellent documentation @brandond thanks for sharing! |
|
@brandond thank you for sharing your tests and I agree that |
|
Thank you for sharing the excellent analysis @brandond . But still, if k3s had a way of modifying the default periods of control loops (I suspect it will be health checks, node updates, etc...) that load could drastically go lower, at the expense of slower response times. Those are parameters which are configurable on all the subsystems k3s embeds. For example, here [1], but there are others like kubelet, kubeproxy, etc.. it's all tunable. Is it possible to access those settings from k3s? [1] https://kubernetes.io/docs/reference/command-line-tools-reference/kube-controller-manager/ |
|
@mangelajo you can play with those via the flags here: But I don't think it'll change as much as you're hoping. |
Hey @brandond. Your product page says:
If this isn't an environment where K3s is expected to run then I'd suggest updating the marketing material. Otherwise people like me end up wasting a lot of time trying to figure out why installing this on their home lightweight IoT setups brings the server to a complete halt. Also if this isn't the environment being targeted would you have any suggestions for a similar product that would work? |
|
@KenMacD The binary has grown a bit since that description was last updated, the repo itself currently states:
We do target IoT appliances and the network edge, as I described in the statement you quoted. Note that an IoT appliance is NOT the same thing as an IoT device - an IoT appliance is a device that acts as a hub for IoT devices. Think NVIDIA Jetson, Google Coral, and the like. Lower-power but still capable systems designed to put processing and storage close to the devices generating data, capable of operating in a semi-detached state. With regards to running on a Pi - I have three of them in my basement right now running k3s without issue. I'm not sure why anyone's surprised that k3s takes more than 25% of a 1.5Ghz embedded processor vs 10% of a 3.0Ghz enterprise datacenter chip. They do less work per cycle, so it takes more cycles to get the job done. If you do find something that scales as well as k3s while using less CPU and memory, please let me know! I'd love to take notes. I apologize if you feel like you've wasted your time with our product. I generally take the view that any time spent learning or trying something new, is time well spent. |
|
I honestly think Rancher is doing a great job to provide/certify/maintain k3s and k3s is a really nice tool. Edge computing and resource-constrained appliances are broad definitions, different people may have different opinions. It's like unattended where I would think that we can leave the system in the wild untouched, but it's recommended to upgrade it and restart it for renewing the one year certificates issued (see #2342). k3s is providing a Lightweight Kubernetes, clearly a lighter Kubernetes, but not something we may think is light. Kubernetes is providing a lot of services at a cost. Resources usage optimization don't look like a top priority for the Kubernetes development team certainly more focused on scalability and robustness. I'm not speaking of storage as it isn't a real issue even on resources constrained servers, but detailing that few hundreds MB of files are downloaded will be more transparent that only writing the binary is less than 100 MB (because it's looking like everything is packaged in the binary file). My final opinion is k3s can work on resources constrained servers at the expense of a significant amount of their resources used to provide the Kubernetes services. Once understood, I think it can be dealt with. More than 2 months ago, when I opened this ticket, I was looking for some ways to optimize CPU and memory resources usage when deploying k3s. For now, I didn't find anything really working (I have tried to tune some kubelet and controller settings without luck). If someone think there are some interesting tuning options, I can leave the ticket open, otherwise I can close it. |
|
My two cents, I tried tuning those settings Without a slight change (36% -> 25%) but the cluster was having issues with leader elections so I commented them back. I also tried using --docker to see if the management of pods was lightened, but no noticeable change either. I will keep using k3s in a rpi4 (another one coming) as I'm going to replace a couple of x86_64 server I have at the office, which consume x10 the electricity. I believe k3s does an outstanding job getting where other k8s distros can't, I wish I was able to trace that 20-30% (of a core) but I understand it's a very complex system. |
|
@mangelajo if you're still experimenting, you might take a look at increasing the cadvisor stats collection interval - I think it's 10 seconds by default? |
|
@brandond hence my suggestion that maybe it's just marketing material that needs updating. The <40M and RPi sounds like it would be usable on an RPi1, which is doubtful. I tried on a board running an Allwinner A20 (Cubieboard 2). It's running the board as what I'd consider an 'IoT Appliance'. It's receiving per-second temperature data that's being stored in influxedb with a Grafana dashboard from a IoT mesh network. It's also running a minidlna server, telegraf to pull weather data, multiple docker containers to control devices through the mesh network. My thoughts were that I could use k3s to make things more reliable. Unfortunately I'm thinking it's the disk usage that killed it. The board keeps most data on a usb2 external disk. I spent a bit of time trying to get some type of ramfs before I found this ticket. I understand you can't support everything, and that this is probably not a use-case worth your dev time. Which is why I come back to the suggestion of updating the marketing material so when new users like me come along and see '40Mb on an RPi' they know that isn't really a viable target install. |
|
Just to be clear, 40MB was referring to the size of the binary executable, not how much disk or memory it needs. I personally run a complete monitoring stack including Prometheus + Grafana on a 4GB Pi4b, but with an external USB3 SSD since Prometheus is quite demanding in terms of IO. |
|
I think binary size is still important but the least one compared to memory, CPU and network usage when talking about constrained environments. As others I also got attracted by the marketing words, but I was wondering why the high usage of memory and CPU in my Raspberry Pi 3+ 1GB cluster. I would hardly consider a 4GB Pi 4D with external SSD ad edge computing. Using Pi 3 B+ was already a luxury for me, meant to use as first step before actually moving on cheaper Pi WH. That being said, I really appreciate the project and afaik k3s is the best state of art. We would like just more consideration regards truly constrained environments in future. |
Jetsons, Corals, and (now) Pi4B/CM4s are what most people have in mind when they talk about edge computing. Pi3Bs and CMs are fairly capable for something like digital signage, or teaching STEM, but not so much for running an entire cluster. |
|
I have similar problem here. Fresh install k3s with no pods running...
|
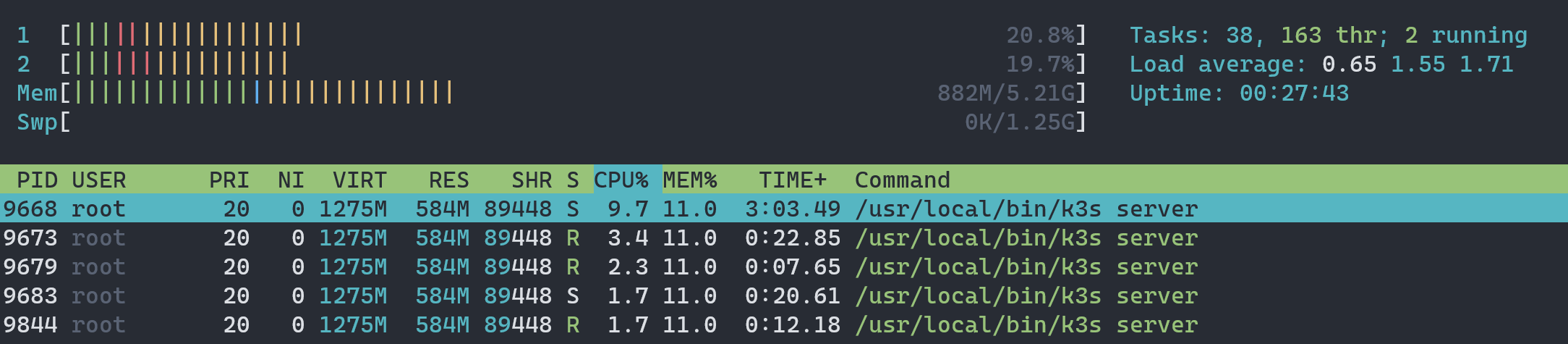
|
@merlinvn please see #2278 (comment) Also note that it is best practice to run Kubernetes with swap disabled. The stock Kubernetes kubelet will actually fail to start if you have swap enabled, but K3s disables this check and leaves it to the user to decide if they need it or not. |
|
Still, no plans to conserve CPU? :( There're people who don't need so frequent updates, any chance for letting us to cut off some CPU usage? |
|
@er1z what would you suggest we remove that wouldn't negatively affect other users who still need those same things? Kubernetes is a living project that will continue to grow, and that growth mostly targets larger deployments. K3s supports low-end hardware better than most distributions, but it is never going to be a zero-overhead option. |
|
I'm not into k3s architecture, but I assume being a Kubernetes distribution doesn't allow to change too many things. But I think, there's a room for,
These are just thoughts-ideas, may be some of them would guide you into coming across other ideas worth at least discussing or even implementing. |
|
im shocked that this loooong existing issue seems to will never be fixed :( this issue is just the continuation of another loooong existing issue :D very funny fact: k8s itself needs much less cpu util. than k3s :D |
Can you prove that? |
What exactly do you want fixed? Have you, yourself, provided any information to the maintainers that specifies an issue you are having? |
|
i have the same problems that everybody does, in this and in the other issue. raspberry 4b, 8gb ram. specs do not really matter. and tried this on every raspberry i got.
|
|
Running Kubernetes is not free. It is expected that it will take about 0.5 to 0.75 of a single core on an embedded system like a Raspberry Pi just as a baseline. If you don't want the overhead of constant health checking, reconciliation, and metrics collection you might look at something a little more lightweight like docker-compose.
This is false. It might appear that way at first glance because individual components (etcd, kube-apiserver, kube-controller-manager, kube-scheduler, kubelet) each run in their own process, but the overall footprint in terms of CPU, memory, and disk space will be higher. I am going to close this issue because at this point it seems to just be attracting more folks who want to argue that Kubernetes should run with zero overhead on any arbitrary low-end or embedded system. Anyone who is curious why this isn't feasible can read the conversation above and click through to the offered links, with https://docs.k3s.io/reference/resource-profiling describing a good baseline. |
|
For anyone still following this, in addition to the resource profiling documentation we added, you might also checkout this research paper: http://ceur-ws.org/Vol-2839/paper11.pdf |
Environmental Info:
K3s Version: k3s version v1.18.8+k3s1 (6b59531)
Running on CentOS 7.8
Node(s) CPU architecture, OS, and Version:
Linux k3s 3.10.0-1127.19.1.el7.x86_64 #1 SMP Tue Aug 25 17:23:54 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
AMD GX-412TC SOC with 2GB RAM
Cluster Configuration:
Single node installation
Describe the bug:
When deploying the latest stable k3s on a single node, the CPU and memory usage may look important.
I understand that Kubernetes isn't lightweight by definition, but the k3s is really interessing for creating/deploying appliances.
On small (embedded) systems, the default CPU and memory usage is important (I'm not speaking here for modern servers).
Is-there a way to optimize these ressources usage or at least to understand the k3s usage of ressources when nothing is deployed?
Steps To Reproduce:
curl -sfL https://get.k3s.io | INSTALL_K3S_EXEC="server --no-deploy traefik" sh
Expected behavior:
Maybe less CPU and memory usage when nothing is deployed and running
Actual behavior:
500MB of memory used and 5% of CPU usage on each core (4 cores CPU) when idle
Additional context / logs:
The text was updated successfully, but these errors were encountered: