This module contains many relevant tools to handle the classification and visualization of 3D concrete image data. The goal of these tools are, among others, to efficiently detect and locate cracks in concrete samples. This can be used as the start of a pipeline that, for example, provides image segmentation.
The module contains tools for
- data generation
- data preprocessing / preparation
- data analysis / visualization
- model training
- model diagnostics / visualization
Additionally, some trained models and current results are provided.
In the following, all available functionality and potential use cases are described.
A good starting point is to look into train_cdd_3d.py and main.py
for training and prediction respectively.
Results that can be obtained by the tools in this module include, for example, prediction on real data,
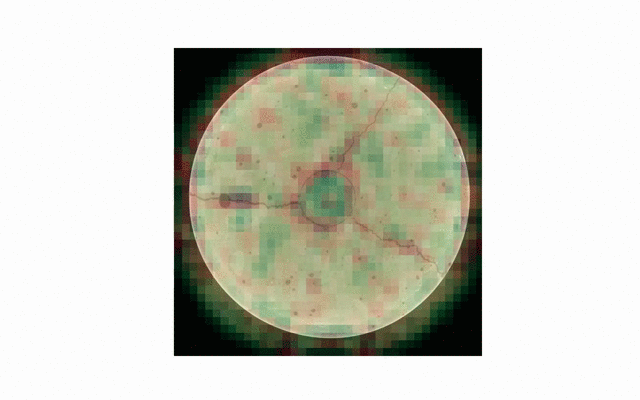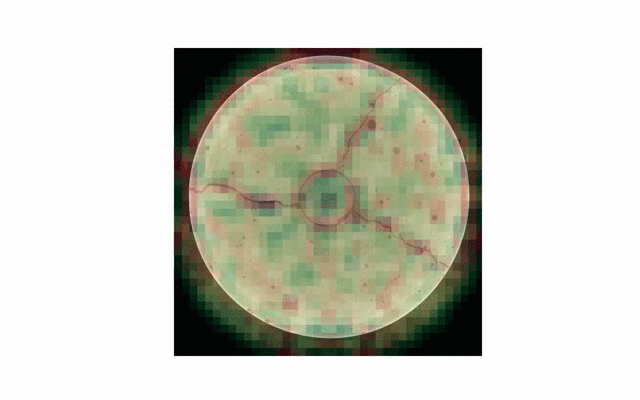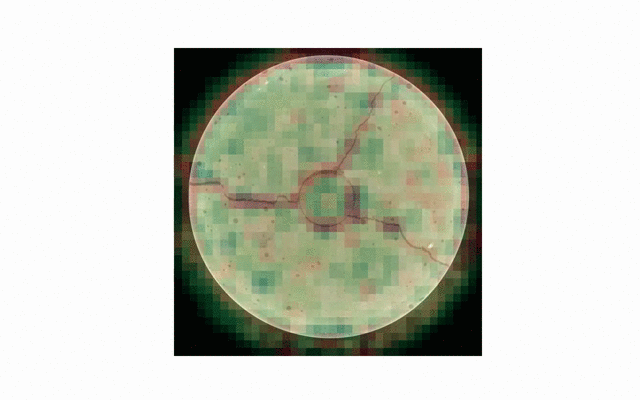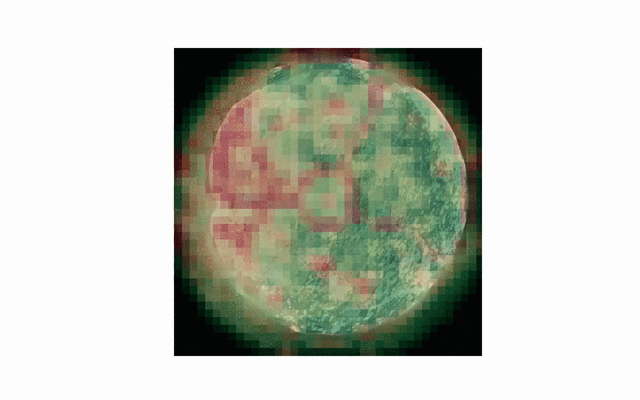
visualization of convolutional filters / features


or checking robustness to changes in scale and shift.


This project is build mainly using PyTorch and most methods including training and prediction
can be done on GPU through CUDA.
For guaranteed compatibility, you can install all needed dependencies from the provided
requirements.txt file, e.g. with
pip install -r requirements.txtSome parts of the module include tools to render .mp4 files, for example,
for diagnosing module output while training or visualization of results over the 3D image.
To use these capabilities a ffmpeg.exe is required which might have to be downloaded.
Additionally, the corresponding path in paths.py has to be edited.
If not needed, relevant parts in the code can be commented out (e.g. in train_cnn_3d.py).
Note that, before working with real or semi-syntethic data, the relevant datasets have to be downloaded
and their locations made known to the module. This is done by modifying the respective entries in the paths.py file
tp point to the correct folders.
Additionally, some files might need to be converted to supported formats (like .npy).
This can be done with the methods in data/unpack.py.
For example, when training on semi-synthethic data that is created just-in-time,
the background images have to be downloaded and converted to
.npy files, e.g. with code similar to
from data import convert_3d
# Scan <img_path> for all .tif files, convert them to numpy and save them in <dest>
convert_3d(img_path="D:Downloads/background/", dest="D:Data/Beton/SemiSynth/npy/")Then, BG_PATH in paths.py has to be set appropriately.
As is, prediction is still not perfect - especially thin or irregular cracks are not detected very well. Additionally, a thorough examination of generalization capabilities across all the available data is needed. For now, most testing has been done on the cylindrical concrete sample also seen above.
There are still a few possible ideas to improve the results which might be worth pursuing. These include, among others, construction of better training sets. This could possibly be done using machine learning tools like Neural Style Transfer. Using a fixed crack width for training and then applying the model on different scales or reusing more general features learned in the segmentation task has been tried briefly but could be looked into more extensively. Averaging over different rotations or using a rotation-invariant CNN could also lead to further improvements.
There are three types of data available for training, validation and testing.
Synthetic data, real data and semi-synthetic data.
All relevant data can be found in the Fraunhofer Cloud.
In the data module, there are tools to
generate, process, prepare, analyze, visualize all kinds of data,
including a pipelines to handle prediction of very big 3D images.
Generally, each type of dataset should be stored as a PyTorch Dataset.
The relevant implementations are SynthData, Betondata and SemiSynthdata.
During training or testing, these datasets are provided via a PyTorch DataLoader.
As detailed below, the easiest way to access the data is to invoke the Betondataset class
and select from a series of presets, while optionally setting some hyperparameters, e.g. with
from data import Betondataset
train, val = Betondataset("semisynth-inf-val", batch_size=4, confidence=0.9)For large 3D image data, that has to be cut in smaller chunks, the BetonImg class
and its methods can be used.
Betondataset in data/presets.py allows easy access to ready-to-use datasets (as a PyTorch DataLoader) by a keyword.
It contains many presets that were/are useful for training and testing and allows to further modify
them by setting hyperparameters. These include parameters about data preparation
(e.g. batch size, the size of the validation set, if data should be shuffled)
or the data itself (e.g. normalization, confidence).
Some of the more important presets include:
| Keyword | Dataset |
|---|---|
semisynth-new |
pre-generated semi-synthetic data (provided as .npy) |
semisynth-inf-new |
non-repeating semi-synthetic data that is generated just-in-time (background provided as .npy) |
real-val |
hand labeled real data from HPC and NC concrete (provided as .npy) |
semisynth-inf-val |
training set is semisynth-inf-new and validation set is real-val |
Inspection and sanity checks can be done as in tests.py, e.g. with the function test_preset_data that
only takes the keyword as a parameter.
When creating a new preset or extending an existing one, it is important to do some preprocessing on the raw data,
such as normalization or data augmentation. These transforms can be found in data/data_transforms.py and include, for example,
normalization of the pixel values (e.g. to a fixed interval), interpolation-based resizing of images and random data manipulations for augmentation (e.g. random cropping, rotating or flipping).
They can be combined and applied to any dataset like a torchvision transform, e.g.
from data import SemiSynthdata, Random_rotate_flip_3d, Normalize_min_max
from torchvision import transforms
transform = transforms.Compose([
transforms.Lambda(Random_rotate_flip_3d()),
transforms.Lambda(Normalize_min_max())
])
data = SemiSynthdata(transform=transform)Tools for data analysis and visualization are contained in data/data_tools.py.
These include methods for plotting histograms of pixel values, plotting batches and
calculating dataset-wide characteristics like the mean, standard deviation or maximum.
For use cases see test.py (or dif-data.py).
Synthetic cracks in 3D are modelled by a Brownian Surface (data/brownian_surface.py) which can be combined
with real background data to form semi-synthetic data or with a synthetic background
modelled as perlin or fractal noise (data/noise.py).
Processing and creation of synthetic data is done in data/synthetic_data.py based on the SynthData class, but is off little value on its own.
To generate semi-synthetic data, background images have to be combined with synthetic cracks.
Processing and creation of semi-synthetic data is done in data/synthetic_data.py based on the SemiSynthdata class.
The creation can be customized by changing, e.g. the number and thickness of the cracks or the grey values
that the cracks may have.
Real data is usually too large to be classified with a CNN all at once.
Therefore, it has to be cut into smaller cubes prior to classification.
If the data is needed for training or validation the chunks can be created using data/unpack.py and saved as .npy.
If a trained model is used just to make predictions, using the BetonImg class in data/bigpic.py provides
a full pipeline from raw data to results that can be visualized.
Supported file types currently include .tif and .tar (directory of .jpg / .png of slices).
For use cases see main.py.
In essence, it could look like the following
from data import BetonImg
from models import Net
import torch
# Data will be loaded from file at <img_path>
data = BetonImg(img_path="D:/Data/Beton/image.tif", overlap=50)
# Initialize model with trained parameters
net = Net()
net.load_state_dict(torch.load("checkpoints/net.cp"))
# make predictions
data.predict(net, device="cpu")
# visualization
data.plot_layer(idx=1000, mode="cmap")
data.animate(mode="cmap")Prediction on real datasets is done with a Convolutional Neural Network (CNN) that was trained on semi-synthetic data. Because this transfer learning task is more difficult than training on labeled real data directly, the results have to evaluated thoroughly to ensure robust predictions and great generalization.
In the models module, there are a few different versions of a light-weight CNN.
These include the current version (Net class in models/cnn_3d.py),
older legacy versions that are no longer relevant (models/legacy.py),
and a CNN that uses more general features learned by solving the segmentation task (models/cnn_from_seq.py).
Finally models/gan.py contains a Generative Adversarial Network (GAN),
that was intended to be used to generate training data.
However, pursuit of this idea was stopped before any usable results were achieved.
A set of recently trained versions of the net can be found in checkpoints/
| checkpoint | parameters | training |
|---|---|---|
current.cp |
n=100, layer=1, kernel_size=5, dropout=0.1 |
trained on 3000 images from semisynth-inf |
current2.cp |
n=100, layer=1, kernel_size=5, dropout=0.1 |
trained on 5000 images from semisynth-inf-new |
fixed_width3.cp |
n=100, layer=1, kernel_size=5, dropout=0.1 |
trained on 5000 images from semisynth-inf-fix |
Training of models is done in train_cnn_3d.py. Here it is possible to modifying everything related to training,
e.g. the used data preset, model architecture, model hyperparameters or from which checkpoint progress is loaded.
Helpful tools to diagnose trained models are found in dif_data.py (and some more in train_cnn_3d.py).
There are a suite of tools to analyze model performance and generalization as well as tools for model
interpretability and visualization somewhat alleviating the black-box nature of using a CNN.
Methods include prediction and computation of relevant metrics (inspect_net),
inspection of wrong and right predictions (analyze_net) and
qualitative assessment of the model's internal idea of a crack,
obtained by sorting a dataset w.r.t. the predicted probability (animate_dataset).
There are tools to check model robustness by checking how the results change under changed
scale, shift or rotation (shift, scale, shift_and_scale, symmetry).
Sometimes generalization performance during prediction is improved by changing, for example,
the scale, in addition to proper normalization. To find optimal values for post-normalization
shift and scale on a new dataset, as an alternative to above methods, fit.py can be used.
It does automatic fitting using on gradient descent, based on a small batch of labeled data.
Finally, there are methods to visualize the convolutional filter and weights of a model (kernels)
as well as tools to interpret their meaning.
The latter is done by inspecting what each filter detects on given data (explain)
or by creating an image that is most representative of each filter's detectable structure,
by maximizing filter activation (visualize).