Aggregation --> CRDTs discussion #40
Comments
|
I've been thinking about this a lot and one of the problems I keep running into is how to find other peers who are also running the aggregation software, which is presumably a separate app that runs on top of ipfs. |
|
There is another way; have a single centralized node handle aggregation/coordination. Use something like https://ipfs.io/ipfs/QmTkzDwWqPbnAh5YiV5VwcTLnGdwSNsNTn2aDxdXBFca7D/example#/ipfs/QmThrNbvLj7afQZhxH72m5Nn1qiVn3eMKWFYV49Zp2mv9B/api/service/readme.md to manage the client -> server communication channel (and standard IPNS for the reverse). I realize 'centralized' is pretty much a dirty word 'round these parts but it's a sensible option that should be a part of the conversation, it has its own set of pros/cons: For example, lets say you have some sort of image aggregation service like imgur, with millions of users and upvotes and so on. A sensible approach for uploading images might be a framework where on 'uploading' a file the user's client adds it to local daemon, and sends the hash through IPFS to the server node. The server node patches that hash into the site's structure, and publishes the new root hash back out to IPNS. The server node would not actually grab a copy of the file, it would only deal with the structure of the dag. This should have the result that this aggregation node doesn't have to do much of anything cpu/bandwidth intensive and could just sit on some cheap VPS somewhere, easily replaceable by anyone should something bad happen to it. You could then have another server run by either the same or a third party operator which does nothing but monitor the DHT and whenever the first server publishes an update, recursively pins the new root hash. Anybody could add to the stability of the service by setting up yet more nodes to do the same thing. Since the site is an open book, should the original site curator shut down anyone else could fork the site and take over that role at any time. The effect of a curator disappearance would be limited to the site coming to a standstill, no data would ever be lost and so long as even one person still cared about it the site could still remain up permanently. Even though it's technically centralized, this approach lacks all the normal hangups that IPFS was made to avoid. I feel it worth considering, particularly as it makes the otherwise hard problem of building purely p2p services much more palatable. |
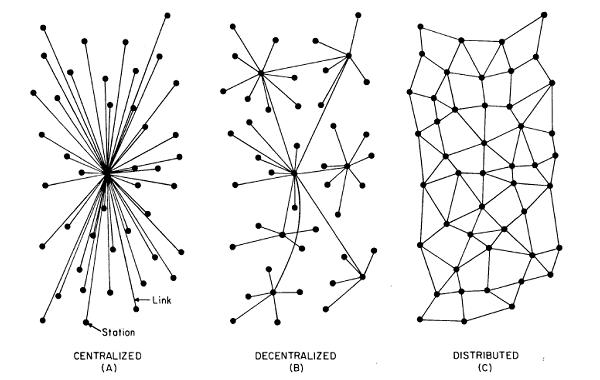
Lucky for you, what you're suggesting sounds more like decentralised but not distributed :) Yes, this is definitely another option, and is a generalisation of what I'm proposing for ipfs-inactive/archives#5 |
|
My idea is to build something along the lines of what @reit-c was suggesting; Each node participating in the aggregation service advertises and aggregates new blocks into a shared blockchain, and then stores and indexes the mdag objects that these blocks point to. In this case a block is: A regular merkel-dag object that links to a previous block and a bunch of merkel-dag objects to be indexed, thus forming a chain. In a situation where each node is getting a lot of traffic (like a web forum), it would be unfeasible to coordinate a large influx of new objects, and so blocks and the blockchain would minimize i/o and serve as a way for each node to pass around packages of new objects, and coordinate which objects should be stored and indexed. Functionality could also be separated into aggregator nodes, storage nodes, index nodes, etc (as @reit-c suggested). Instead of there being one large index, there could be many smaller indices with each node deciding on which index to aggregate on, thus nodes can chose which indices to support. Each index could correspond to a multihash from which peers can be discovered through the DHT. Blocks are advertised and discovered by a gossip protocol built on IPNS, where each node will periodically contact all its peers and resolve TL:DR, functionality can be split into three things;
Seeing as I'm fairly new to distributed applications, I was wondering if anyone could help me out with understanding the following:
I would love to hear other peoples' thoughts on this because I am itching to get this going! |
|
( Relevant: http://hal.upmc.fr/inria-00555588/document ) |
|
@ehd @cmeiklejohn excellent list |
|
These are fantastic resources, thanks! |
|
It'd be incredibly interesting to add CRDTs to IPFS. The simplest primitive seems to be some kind of grow-only (append-only) datastructure. The edits, and additions to the datastructure don't need to have any order in themselves. In fact, as IPFS is immutable, it perhaps makes sense to populate the append-only datastructure with deltas, along with accompanying causality data (dotted version vector / vector clock) of the delta. The model that's purposed by @davidar seems to be heading in this direction with the current IPFS primitives. Is it reasonable to add to the primitives provided by IPFS, and IPNS to provide a grow-only datastructure, or a content hash which only has an ever increasing number of edges provided? I know bittorrent has some of the same problems, making editing old torrents a problem. Once a G-set CRDT is implemented on top of IPFS, it becomes easier to add other types of CRDTs. I imagine an implementation could have a bunch of IPNS addresses representing CRDTs, and add those to a set. When it comes time to update the CRDT itself, all that must happen is that the CRDT component is updated. Now, this prevents some of the "permanence" of IPFS. One example of a global, distributed, append-only log is blockchain technology. Now, in my opinion, blockchain technology may not be the right approach, because it has a ham-fisted approach for reaching consensus in order to make progress, with some safety guarantees. Perhaps, that can be a source of inspiration. (If you have any CRDT-specific questions, perhaps I can answer them too?) |
|
@sargun Could you explain how append-only objects would be implemented/enforced (if not by a blockchain)? I agree it would be very helpful for implementing aggregation, but am having difficulty seeing how it would work myself. The main question I have about CRDTs is: Is it possible for nodes to agree on the hash of the merged object with minimal communication (i.e. not having to download the other node's object fully)? |
|
So, I thought about this for a while last night. A place to start might be ScuttleButt: https://www.cs.cornell.edu/home/rvr/papers/flowgossip.pdf. In addition, SSBC: https://github.com/ssbc/docs. If an actor only edits their own view of a CRDT, and we maintain the merged version of the CRDT as a separate component from the "source" of the CRDT, it becomes somewhat easier to do this. |
|
I'll take this a bit further, both in functionality and time: Now, the main issue is finding other users. There should probably be a central server to kickstart the whole thing. Once the first users are registered (i.e. created a profile bound to some sort of cryptographic ID), the network becomes self-sustained: clients store connection info (IP addr, ...) of the user's friends, enabling communication without any central party. Let's hope and pray for IPv6 to move its slow ass and make this a sensible option. Searches for new people to befriend go out to the user's current friends, recursing through their friend lists until the person is found (which is practically, though not theoretically, bound to happen sometime). Privacy implications can be close to nil:
Facebook is obviously never going to do such a thing since it would mean losing their basis of existence - user data. However, I see in IPFS a new way to build open and libre web applications and services where user data is never stored outside the user's control. For instance: to chat with a friend, your client would connect to that person's client based on your record of him/her. If the person isn't online right now, your client retries every now and then. TL;DR: Web apps/services need to be built differently on IPFS than on HTTP. Basta. [WIP] |
|
@jbenet thoughts? |
WIPIgnoring IPFS, I'm trying to think about how one would build a CRDT store that's P2P, and user-editable. There are people who are consumers of this CRDT - people who are willing to pull a copy of the CRDT from their nearest node, or similar, but are unlikely to keep constantly up to date. Then, there are producers - individuals who are producing updates to the CRDTs. Every producer should have a copy of the data structure at a point in time, so we can also call them replicas. I've been thinking about this more and more, and it seems difficult. There are tradeoffs for content that has lots of publishers, or lots of consumers. Let's assume we have a Pastry-like system to start with. Let's also assume that the keys / peer IDs are SHA-512 hashes of public keys, and for the sake of discussion, let's say we're building Twitter. Ignoring the complexities of user discovery, and such, let's focus on time lines. PlayersLet's say there are consumer's who's public keys hash to C-[1-100]. In addition, let's say there are replicas, R-[1-10]. Any actor who performs a write, must also be a replica. Every node participating in the system must be using a key registered with Keybase. The purpose of this is to prevent abuse to the system, and keybase is a decent reputation management system. DatastructuresLet's build the timeline for oprah. Data structure membership listsThese are the members that are replicas of a given data structure. These will be a set of the replicas along with a timestamp of when that replica was last seen. They don't actually have to be a full set of replicas, but they instead can be a random sampling of the most recent replicas that have registered. At some interval, replicas will squawk that they're alive along with a new time stamp. The timestamp must come from a timestamp service which allows for any timestamp, up till TAI +/- 100 seconds. In a first version of the service, someone can simply host a handful of servers that sync with NIST, and serve up the current time, signed with their public key. The membership list will be aggressively pruned, based on out of date servers, except M replicas, no matter how old they are, will stay in the replica set. Example
Replica datastructureThis is where the magic happens. The replica datastructure is basically a CRDT, and a version vector along with that. These would be delta CRDTs, so when it comes time to update other replicas, they can be done efficiently. MechanismReplicasWhen a replica first joins the network, it sends a query to get It then takes some subset, {R1, R45} of this, and sends a request to fetch-metadata When it comes time to a write, the actor must update the metadata, and generate the delta itself. The delta and metadata is then sent out via the rendezvous point Consumers instead fetch the list of members, and subscribe as well. They only need to read one replica's copy to build their local version. Open Questions:Q: How do you prevent explosion in the size of the metadata (version vector) required for the replica datastructure? |
|
Also, tagging in @russelldb - who kinda is an expert in CRDTs. |
|
@sargun I'm not familiar enough with CRDTs to say much, but I do have one comment:
Personally I'm quite interested in the case where the data structure is too large to assume any node has a full copy, eg. a search engine index. Can this case be supported within a CRDT-based system, or would it require something else? |
|
@davidar I think so, yes. CRDTs can be decomposed, or partitioned. But you're looking at current research problems, not known solutions. |
|
The case of having a CRDT that is too large to assume that any node can maintain it is a very interesting one that the SyncFree research group (and, specifically members of my lab at the Université catholique de Louvain) been working on. There's an upcoming publication at IEEE CloudCom 2015 on conflict-free partially replicated CRDTs, that may be of interest to you. I'm not sure if they are still working on the camera ready still or not, but it will be publicly available shortly. The work being done at NOVA on computational CRDTs is also relevant here. These C-CRDTs try to embed the computation in the design of the CRDT itself, and provide a different merge operation for when nodes that do not contain overlapping state must be joined -- this can be thought of as a sum operation. The work on Titan is relevant here, as well as this formalism for constructing these data types. My lab's work on Lasp might also be relevant here. Lasp builds on previous work to provide a programming abstraction over distributed copies of CRDTs and provides a runtime for executing these computations. The important observation about Lasp is that the computations are dynamic: based on how much knowledge each node in the system has, which is a property of how often these nodes communicate, replicated copies that observe the same system changes will converge to the correct value. We've used Lasp to build a prototype implementation of distributed "materialized views" in Riak that allows simple selection and projection (but is relevant to any Chord-style DHT) which I believe is essentially a smaller instance of what's being discussed here. In this example, each node in the system contains some partial state in the system. For example, in a Dynamo-style system, each node contains data replicated from it's neighboring partitions. Partial "views" are computed from data local to each partition: these views themselves are mergable with their replicas, to ensure high availability and fault-tolerance of the view itself, and then a commutative sum operation is used to join these views. This work build upon all of the previous work mentioned in this post. These are all open research questions still, and there's multiple people across multiple labs working on them, so it will be very interesting to see where things evolve! |
|
@davidar, I suggest you take a look at a paper I presented last year at Onward! 2014. It claims that git-style version control can provide a better flexibility in managing CAP-theorem trade-offs when storing application state. It describes a system I did not fully implement, named VERCAST (VERsion Controlled Application STate). I actually started to doubt the relevance of this paper until I stumbled across IPFS a few days ago... The system I am proposing in the paper has three layers: An object layer, storing a content-addressable DAG of immutable objects, a version graph layer that supports merging operations for such objects, and a branch layer, which contains a mutable map from branch IDs to object versions. The object layer maps more-or-less to IPFS, while the branch layer maps nicely to IPNS. The differences are that the VERCAST object layer also handles mutation to the state through patches, which can be seen as functions that take one version and return another. There are certain rules for what is and is not allowed for patches, but the important thing is that mutation is a part of the state (thing objects in OOP). I believe the VERCAST object layer can be implemented over IPFS with relative ease. However, the real missing piece is the version graph, the one thing that allows aggregation of state... In the few days I've known about IPFS I found myself thinking a lot about how this can be used to maintain application state. Same as the other folks writing on this page, I too don't have a clear picture in my head on how this can be done. Anyways, I thought my VERCAST paper could be relevant to the discussion. Maybe it will give someone an idea... |
|
@cmeiklejohn @brosenan We have reformulated An outdated first draft version, also comparing @cmeiklejohn Lasp is nice btw. but I am not sure whether inventing a new syntax again is making me happy as a Lisper :P. I have been looking a bit into the proof ideas presented at the |
|
Everyone on this thread: this is awesome. I'm very glad to see all of this discussion springing up. I will take more time to discuss the various topics above, but i have a lot of reading to do first. I would like to note a few things here -- for lack of an equally nice sideband: (a) We would love to figure out how to make IPFS better to support CRDTs. it will be really valuable to have one common transport for all CRDT datastructures so that things can be linked with each other. In a big way, we're making an "IP for datastructures" with our dag format. We have a set of protocols/formats for figuring out how to make sense of data, and it will really help to discuss with you to make this the easiest thing to build on. (b) We can easily ship CRDT-based applications on top of IPFS at this point, because you can just many any frontend js thing, and use a local IPFS node as the transport. we (really @diasdavid) are still working on making the js/node implementation of ipfs (https://github.com/ipfs/node-ipfs) but for now can use a local ipfs node. We can also speed up "extension bundling" if it would make it easier for you to do research + implement CRDT applications to deploy to end users. (c) as a "small first step" we really want to make a CRDT based Etherpad on IPFS, and a CRDT based markdown editor. I know many are out there, but are there any easy to rebase on top ipfs? (d) I want to stimulate CRDT interest and use. It may be useful to organize a small (20-100 people) "programming language-style conf" for CRDTs. Have a bunch of talks, record them with high production value, and present both libraries ready for use, and interesting new directions. I am sure you all have lots to talk about, and spreading your ideas + code will help make the web better. (e) keep at it! your work is super important. you're improving the world dramatically by solving so many distributed systems problems so cleanly, elegantly, and efficiently (in terms of a huge amount of engineering-years) |
|
@russelldb @cmeiklejohn @brosenan @whilo It's great to hear that this is a problem that is being actively researched :). I wish I were familiar enough with this area to make more than superficial comments, but ... I'm really looking forward to seeing this integrated with IPFS, and am excited about the applications that it would enable. |
@larskluge you might be interested in taking part of this endeavour, I recall we talking about using IPFS for inkpad (which would be pretty awesome :) ) |
|
Thanks for dialing me in @diasdavid—indeed, I'm thinking to support IPFS with Inkpad. Curious how the interesting is here.. :) |
|
@ekmett’s talk about propagators: |

|
cc @cleichner |
|
I've been working on something that provides a way to to "dynamic content on ipfs" and is related to CRDTs more or less. See https://github.com/haadcode/orbit-client and https://github.com/haadcode/orbit-server. orbit-client is basically an event log and kv-store and orbit-server handles tracking of (head) hashes for channels (think feeds, topics, tables). It's a grow-only linked list where new items are posted in sequential order and uses an "operation" mechanism to differentiate between add and remove ops and item's status/value is Last-Write-Wins. An event (message) is divided into two parts: the LL data structure item and the actual content of that item are separate ipfs objects. The LL item refers to the ipfs-hash of the content and contains a link to the next item in the list (again, an ipfs-hash). The data is encrypted and there's a verification step to verify the integrity of each message. At the moment the server keeps the track of the head hash of each channel but once you have the head, you can traverse the linked list without server communication. On the client side, the database is eventually consistent as clients pull the latest heads and traverse the data. orbit-client is based on code in Orbit (https://github.com/haadcode/anonymous-networks) and the server is what currently powers Orbit. Both of these have been working nicely the past couple of months. There's still a lot of work to do and the goal is to make orbit-client work without a server eventually, but this is dependent on some features to land IPFS (namely pubsub). There's not a lot of documentation available yet but if you feel adventurous, take a look and explore the data structures. I'm not very familiar with CRDTs on implementation level, so I'd be happy to get feedback and see where we can take this! |
|
I still think it is much more sane to build replication around the CRDT mechanism and then build a filesystem and immutable value distribution a la bittorrent etc. on top instead of simulating a file-system layer which can be written to in an arbitrary format and hence is difficult if not impossible to reformulate as a CRDT for the generic case. Distributed reads are easy to scale, distributed writes are not and a filesystem expresses a fake abstraction in form of binary file handles as your writes do not really succeed as is thought of by the application. You can never satisfy the traditional unix filesystem semantics (i.e. fsync) in a distributed system. If you have ever tried to use NFS, AFS, glusterfs or other distributed filesystems like SSHFS, dropbox etc., you certainly have experienced corruption, conflicts and serious problems in form of locks when you have run an application which needs fine grained write-semantics, e.g. a database like sqlite or mysql in parallel on multiple clients. And these are mostly local and small scale solutions. I have tried to get even only the home folder distributed ten years ago that way and failed with many fairly simple free desktop applications for this very reason (without understanding the dimension of the problem back then). I think it is much better to implement a FUSE filesystem on top of some CRDT for applications which need this and have a well understood write behaviour and otherwise use CRDTs directly as these can be understood by the developers and expose their semantics to the application. You can still have the global namespace and share the goals of IPFS as we do, but we have doubts about the filesystem approach (which we also elaborated in our original whitepaper). I don't want this to be misunderstood, exactly because we share the goals of IPFS and want to build a free and open internet with shared data sources and painfree scalability, I think it is necessary to rethink the approach of IPFS. We have finally released the first version of our replication software btw.: https://github.com/replikativ/replikativ/ and have implemented a social network application with it: https://topiq.es |
|
I'll look at your links in depth later but you may be missing the fact that (Maybe in skimming I failed to understand you, but your mention of fsync On Wed, Jan 20, 2016 at 15:41 Christian Weilbach [email protected]
|
|
Made some good progress on prototyping CRDTs on IPFS. See the latest version of OrbitDB and the implementation. I reckon the implementation can be simplified a lot in the future using IPLD, see the current data structure. The LWW set works nicely for the db operations and I figured out a better way to achieve partial ordering using (sort of) vector clocks together with the linked list. |
|
So many familiar people speaking on so familiar topics here that I decided to chime in.
In my opinion, concepts of distributed FS and DB are both orthogonal and complementary. General point: FS makes a poor DB and DB makes a poor FS. We may see it in a way that DB is implemented on top of a FS or that FS is a binary blob store for a DB. FS is about unstructured data and DB is about structured data, be it distributed or not. With my current understanding of IPFS, I see two potential issues. First, a DB typically needs an op log, which can be implemented as an append-only file in IPFS. With op-based CRDTs, the file may grow in very small increments. I mean, a hash may turn bigger than an op, so the stream of log hashes will be actually bigger than the op log itself. As far as I understand, IPFS will have to pump that data through IPNS, not sure how it will go. Second, I am not sure how IPNS handles concurrent writes; a CRDT op log is partially ordered because of concurrent writers. I understand how a Merkle DAG should handle multiple "heads" (more or less like git does), but I don't know how IPFS/IPNS works here. Any hints are welcome. Edits 11.03: Merkle tree -> DAG, git reference |
|
cc @mafintosh, @substack and @noffle who seem to be thinking a lot about shared content-addressable append-only logs |
|
(Disclaimer: this is all still in the very early / mad science stages of R&D.) The general pattern I've exploring using is using an overlay swarm of peers interested in a topic, to track new merkle dag nodes that link to ones already in the swarm, and then IPFS nodes throughout that swarm to replicate data to the IPFS network for permanent storage. In Javascript, I'm using ipfs-hyperlog: it provides real-time replication of a growing merkle dag of IPFS objects, modeled as an append-only log. For forming the actual swarm, hyperswarm can be used in the browser (central signalling server + WebRTC), or discovery-swarm (BitTorrent DHT + TCP|UTP) in Node. This doesn't involve IPFS by itself (other than the merkle dag format), but the trick is to then populate the swarm with "replicator nodes" (IPFS nodes that listen for the new IPFS heads that are published to the hyperlog), and replicate snapshots of those dag heads to IPFS for said permanent storage. |
|
Hi, as I don't really have in depth understanding of CRDTs I may just be completely wrong but I think having dynamic content/CRDT on top of a distributed storage like IPFS is equivalent to solving the asynchronous byzantine generals problem (if we want it to be cryptographically secure): we need to have a strong mean of ordering the transactions (updates) because sometimes concurrent delta-states cannot be merged. If I didn't completely missed the point I am gonna reference another issue I created, it may provide some ideas about this exact problem: #138. Edit: I now understand a bit better, consensus algorithms focus on consistency and CRDT focus on availability (with convergence and eventual consistency) both of which cannot be fully acheived by the CAP theorem. So the two approaches are complementary and CRDTs may not be ideal in every use case. |
|
I gave a more introductory talk about propagators at Yow! LambdaJam in Brisbane a few weeks ago. It may be useful to folks for framing the discussion about CRDTs: |
|
Hi y'all, some of us gathered today to discuss orbit's future, essentially gather ideas of what is possible. Some notes from the discussion:
We've also realized that since CRDTs are actually a broad topic with a lot of people interested, that it would be better to open a repo |
|
I would love to get the opinion of some CRDT experts here on what I believe is a new design for a Set CRDT: |
|
In the context of the IIIF-over-IPFS project, I created an IPFS connector for Yjs (a CRDT library). Demo (using a IIIF data structure) here. Next steps:
Links: |
|
Just came here to say that now there is a awesome video tutorial of how to get Yjs to use IPFS! https://github.com/ipfs/research-CRDT/issues/7 ❤️👏🏽👏🏽 Thanks @pgte 👏🏽👏🏽💖 |
|
@ianopolous Have you seen this ORSet? http://haslab.uminho.pt/ashoker/files/deltacrdt_0.pdf |
|
While reading the multiple comment posted out here, a question came up to my mind.
|
|
Just to add more context, IPFS is open and free, hashgraph is patented in US. |
So, a lot of the questions about "dynamic content on ipfs" seem to boil down to how to aggregate content from multiple sources. Use cases:
This should be possible with IPFS+IPNS, but it needs to be well-documented and streamlined for users.
Another issue is how to make it scale, so you're not having to aggregate millions of sources in every client (e.g. reddit on ipfs).
The text was updated successfully, but these errors were encountered: