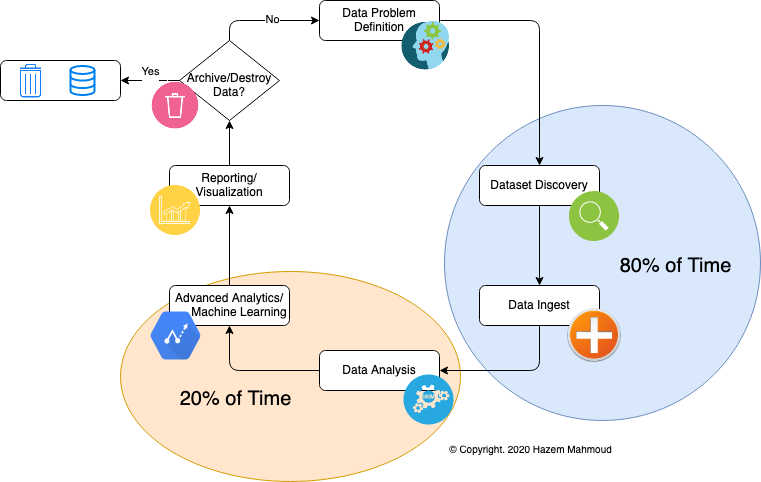
- Data Problem Definition
- Dataset Discovery
- Data Ingest (cleansing, transformations, etc)
- Data Analysis
- Machine Learning
- Reporting/Visualization
- Data Archival/Destruction
Does weather have an impact on the spread of COVID-19?
Critical to find reliable dataset sources. For this exercise, I went with data from kaggle.com, which is considered fairly reliable, but is not from the actual source data and hence quality may not be as reliable. Typically this may involve paying to get the reliable data sources you need
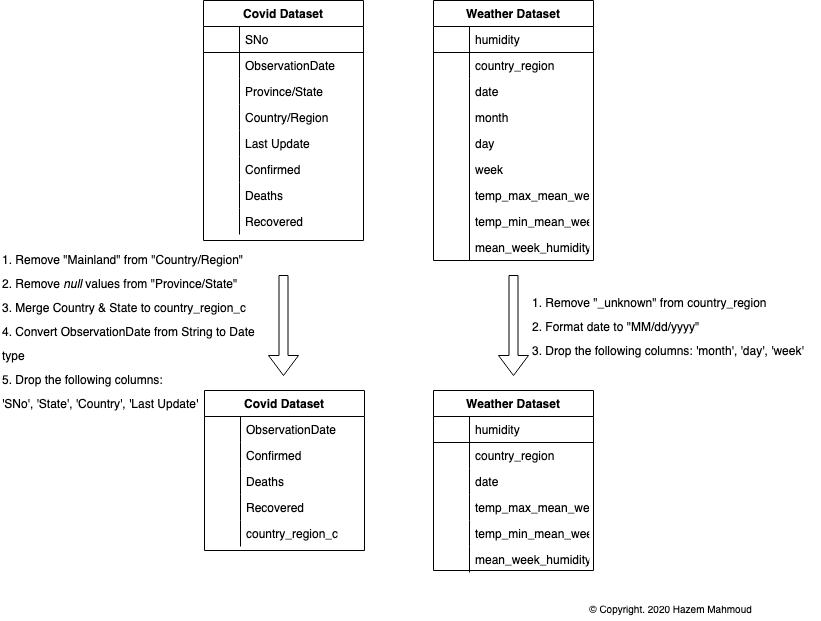
Use Spark to ingest datasets into Spark dataframes Perform some cleansing of the data and transformations Denormalize the dataset and then write to Cassandra


brew install scala
brew install apache-spark
Add the following in your profile:
export SPARK_HOME=/usr/local/Cellar/apache-spark/2.4.5/libexec
export PYSPARK_PYTHON=python3
export PATH=$JAVA_HOME/bin:$SPARK_HOME:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
Need to set PYSPARK_PYTHON so that PySpark uses Python3, which we need for the Kaggle API (which is installed further down)
If you want to view Spark History Server UI to view jobs:
mkdir /tmp/spark-events
/usr/local/Cellar/apache-spark/2.4.5/libexec/sbin/start-history-server.sh
Make sure to stop Spark History Server when you're done:
/usr/local/Cellar/apache-spark/2.4.5/libexec/sbin/stop-history-server.sh
pip3 install cql
this installs cassandra query language
brew install cassandra
this will install cassandra at /usr/local/Cellar/cassandra/3.11.6_2 To Start:
cassandra -f
OR, the following, but this will start up Cassandra at every system restart
launchctl load ~/Library/LaunchAgents/homebrew.mxcl.cassandra.plist
cqlsh> CREATE KEYSPACE hazem
... WITH REPLICATION = {
... 'class' : 'SimpleStrategy',
... 'replication_factor' : 1
... };
cqlsh> use hazem;
cqlsh:hazem> CREATE TABLE hazem.weather (
... humidity float,
... country_region text,
... date date,
... temp_max_mean_week float,
... temp_min_mean_week float,
... mean_week_humidity float,
... PRIMARY KEY (country_region,date));
cqlsh:hazem> CREATE TABLE hazem.covid (
... "ObservationDate" date,
... "Confirmed" float,
... "Deaths" float,
... "Recovered" float,
... country_region_c text,
... PRIMARY KEY (country_region_c,"ObservationDate"));
cqlsh:hazem> CREATE TABLE hazem.covidweather (
... confirmed float,
... deaths float,
... recovered float,
... humidity float,
... country_region text,
... date date,
... temp_max_mean_week float,
... temp_min_mean_week float,
... mean_week_humidity float,
... PRIMARY KEY (country_region,date));
Note: Added double quotes to keep case-sensitivity. No reason to keep it, but just to demonstrate that nuance.
To verify:
cqlsh:hazem> DESCRIBE hazem.weather ;
CREATE TABLE hazem.weather (
country_region text,
date date,
humidity float,
mean_week_humidity float,
temp_max_mean_week float,
temp_min_mean_week float,
PRIMARY KEY (country_region, date)
) WITH CLUSTERING ORDER BY (date ASC)
AND bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
cqlsh:hazem> DESCRIBE hazem.covid
CREATE TABLE hazem.covid (
country_region_c text,
"ObservationDate" date,
"Confirmed" float,
"Deaths" float,
"Recovered" float,
PRIMARY KEY (country_region_c, "ObservationDate")
) WITH CLUSTERING ORDER BY (observationdate ASC)
AND bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
cqlsh:hazem> DESCRIBE hazem.covidweather;
CREATE TABLE hazem.covidweather (
country_region text,
date date,
confirmed float,
deaths float,
humidity float,
mean_week_humidity float,
recovered float,
temp_max_mean_week float,
temp_min_mean_week float,
PRIMARY KEY (country_region, date)
) WITH CLUSTERING ORDER BY (date ASC)
AND bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
cqlsh:hazem> select * from hazem.covidweather;
wget http://dl.bintray.com/spark-packages/maven/anguenot/pyspark-cassandra/2.4.0/pyspark-cassandra-2.4.0.jar
(Source: https://spark-packages.org/package/anguenot/pyspark-cassandra)
If you want to test via pyspark shell, you can do the following (to get Spark Cassandra connector from Spark Packages directly):
pyspark --packages anguenot:pyspark-cassandra:2.4.0 --conf spark.cassandra.connection.host=127.0.0.1
>>> import pyspark_cassandra
pip install kaggle
Go to your Kaggle account at https://www.kaggle.com/<account_name>/account Click on "Create New API Token" Move the auto-downloaded json file (kaggle.json) to your Kaggle home directory (/Users/hmahmoud/.kaggle/)
chmod 600 /Users/hmahmoud/.kaggle/kaggle.json
Contents of kaggle.json will look like this
{"username":"ihazem","key":"<KEY>"}
- Clean/reliable data source quality
cdf.printSchema()
wdf.printSchema()
root
|-- SNo: integer (nullable = true)
|-- ObservationDate: string (nullable = true)
|-- Province/State: string (nullable = true)
|-- Country/Region: string (nullable = true)
|-- Last Update: string (nullable = true)
|-- Confirmed: double (nullable = true)
|-- Deaths: double (nullable = true)
|-- Recovered: double (nullable = true)
root
|-- humidity: double (nullable = true)
|-- country_region: string (nullable = true)
|-- date: timestamp (nullable = true)
|-- month: integer (nullable = true)
|-- day: integer (nullable = true)
|-- week: integer (nullable = true)
|-- temp_max_mean_week: double (nullable = true)
|-- temp_min_mean_week: double (nullable = true)
|-- mean_week_humidity: double (nullable = true)
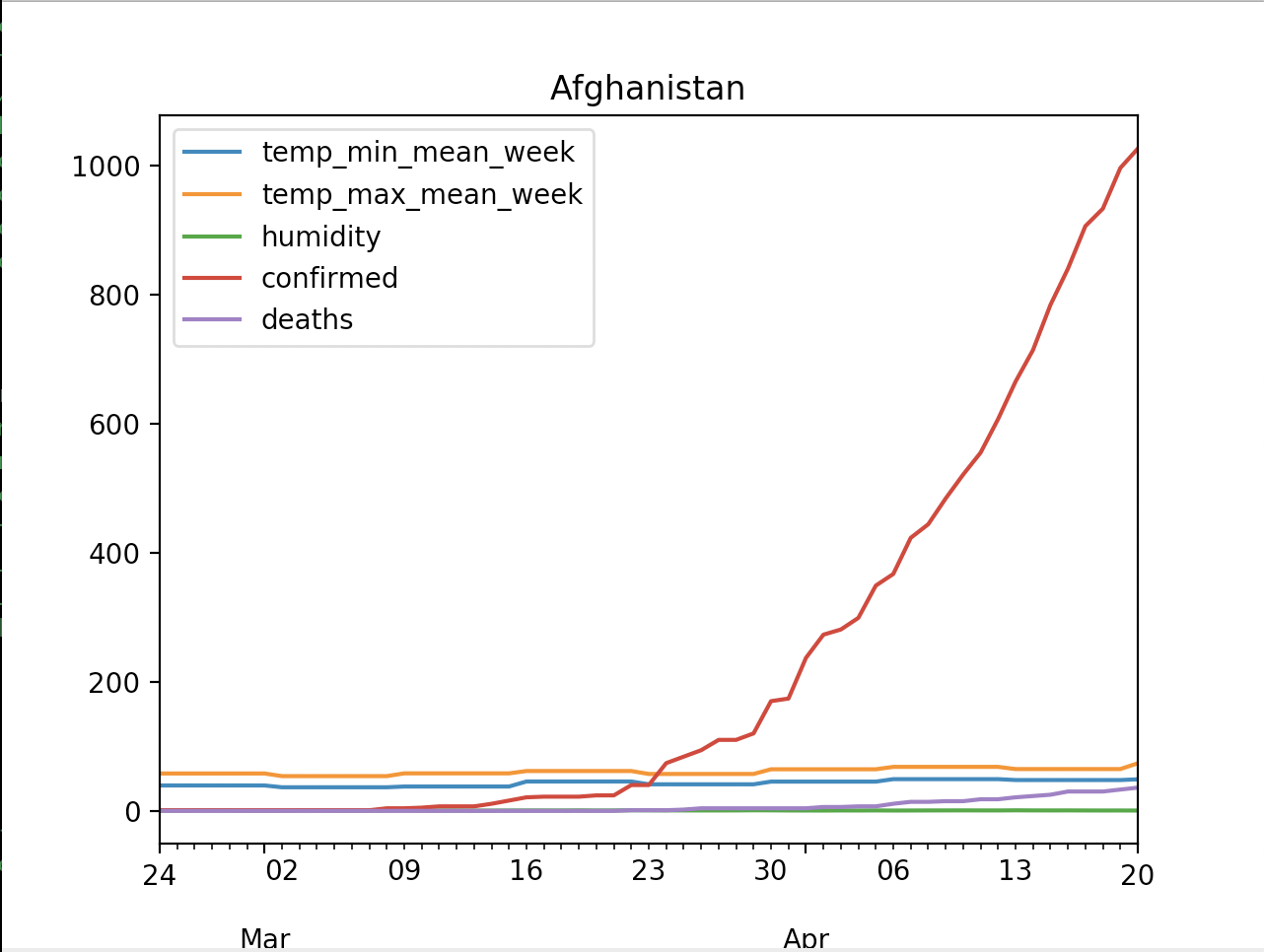
spark-submit --packages anguenot:pyspark-cassandra:2.4.0 --jars jars/pyspark-cassandra-2.4.0.jar,jars/spark-cassandra-connector-2.4.0-s_2.11.jar --py-files jars/pyspark-cassandra-2.4.0.jar,jars/spark-cassandra-connector-2.4.0-s_2.11.jar --conf spark.cassandra.connection.host=127.0.0.1 covid-weather.py <COUNTRY>
For example:
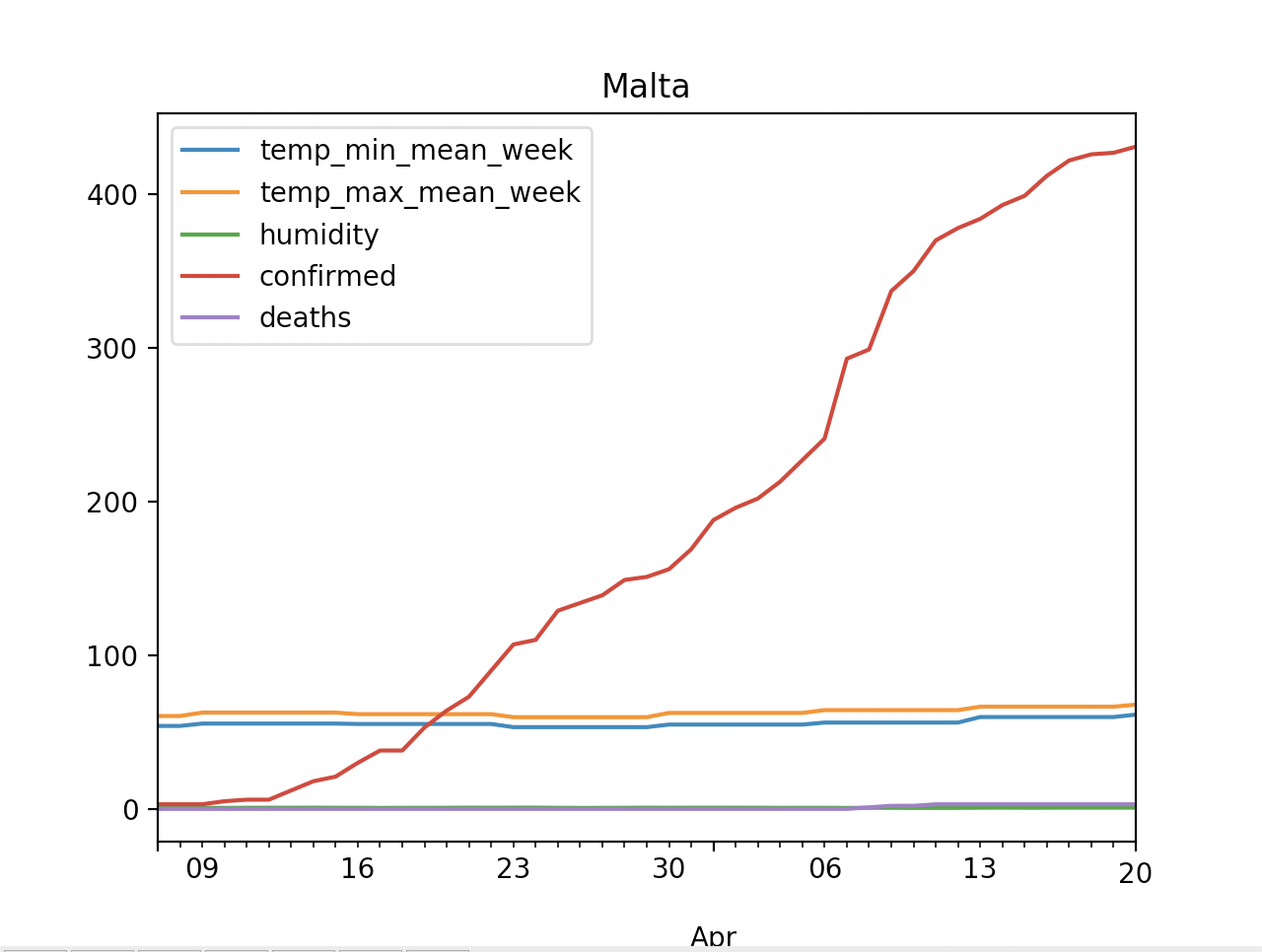
spark-submit --packages anguenot:pyspark-cassandra:2.4.0 --jars jars/pyspark-cassandra-2.4.0.jar,jars/spark-cassandra-connector-2.4.0-s_2.11.jar --py-files jars/pyspark-cassandra-2.4.0.jar,jars/spark-cassandra-connector-2.4.0-s_2.11.jar --conf spark.cassandra.connection.host=127.0.0.1 covid-weather.py Malta
- https://www.kaggle.com/sudalairajkumar/novel-corona-virus-2019-dataset
- https://www.kaggle.com/leela2299/weather-covid19
- https://github.com/Kaggle/kaggle-api/blob/master/kaggle/api/kaggle_api_extended.py
- https://technowhisp.com/kaggle-api-python-documentation/
- http://spark.apache.org/docs/latest/api/python/pyspark.sql.html#module-pyspark.sql.functions
- https://spark.apache.org/docs/2.3.0/sql-programming-guide.html