PBFE stands for Performance Based Engineering for Resilient Food Industry. We aim at developing a food system management framework by combining Performance Based Engineering (PBE) and Artificial Intelligence (AI), to increase the efficiency, safety & resilience of agricultural production by improving food yield in terms of both quantity and quality, controlling crop diseases, decreasing resource consumption & waste, and increasing traceability. Traditionally, agricultural management is based on empirical judgement resulting from experiments & experience, which is no longer adequate because of increased complexity and added uncertainty of food systems due to the increasing demands of the world population. Thus, uncertainty quantification in food systems has been recently adopted. However, a robust framework is still lacking and this project aims at filling this gap.
Figure 1. Overview of the PBFE framework.
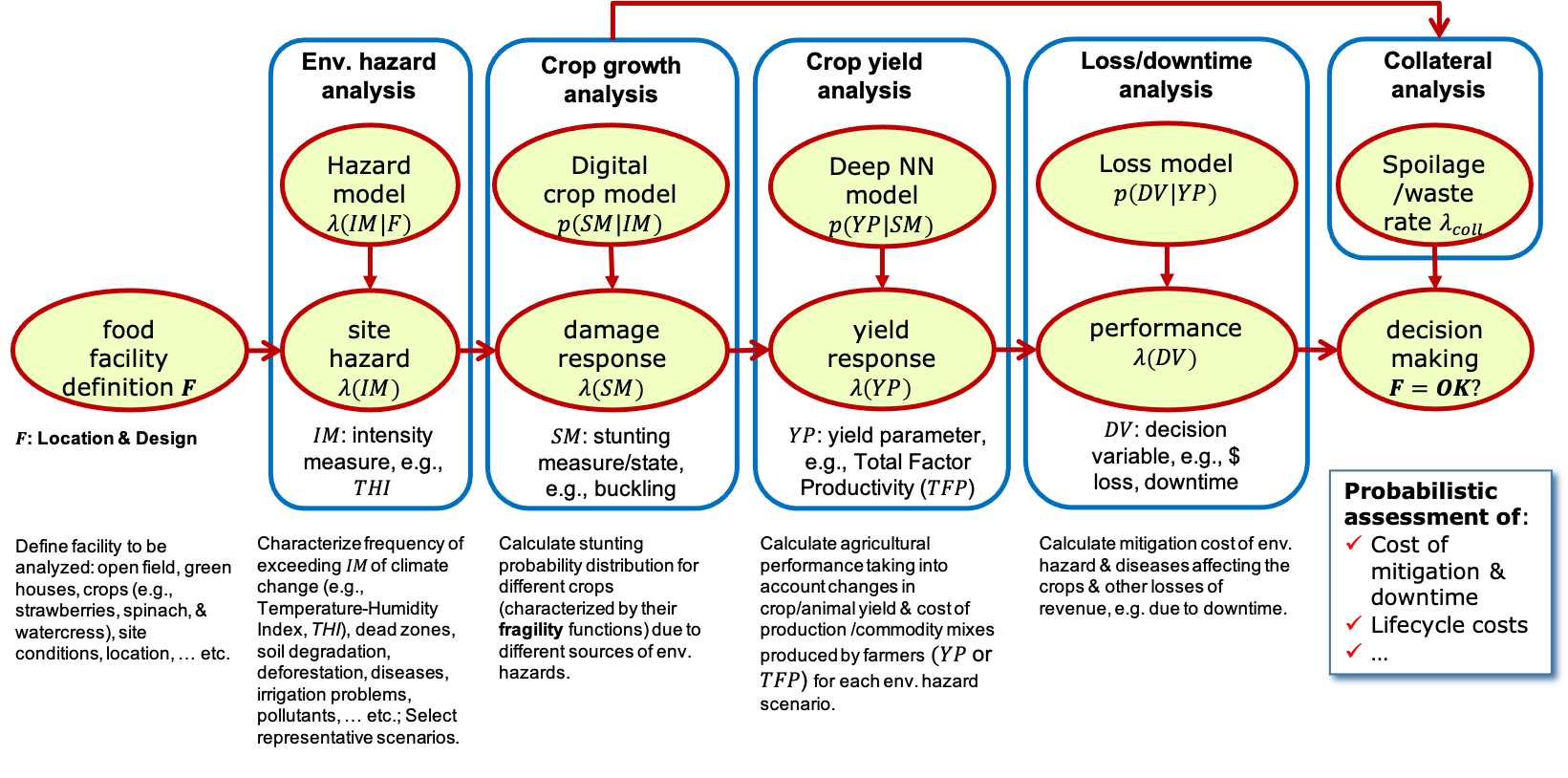
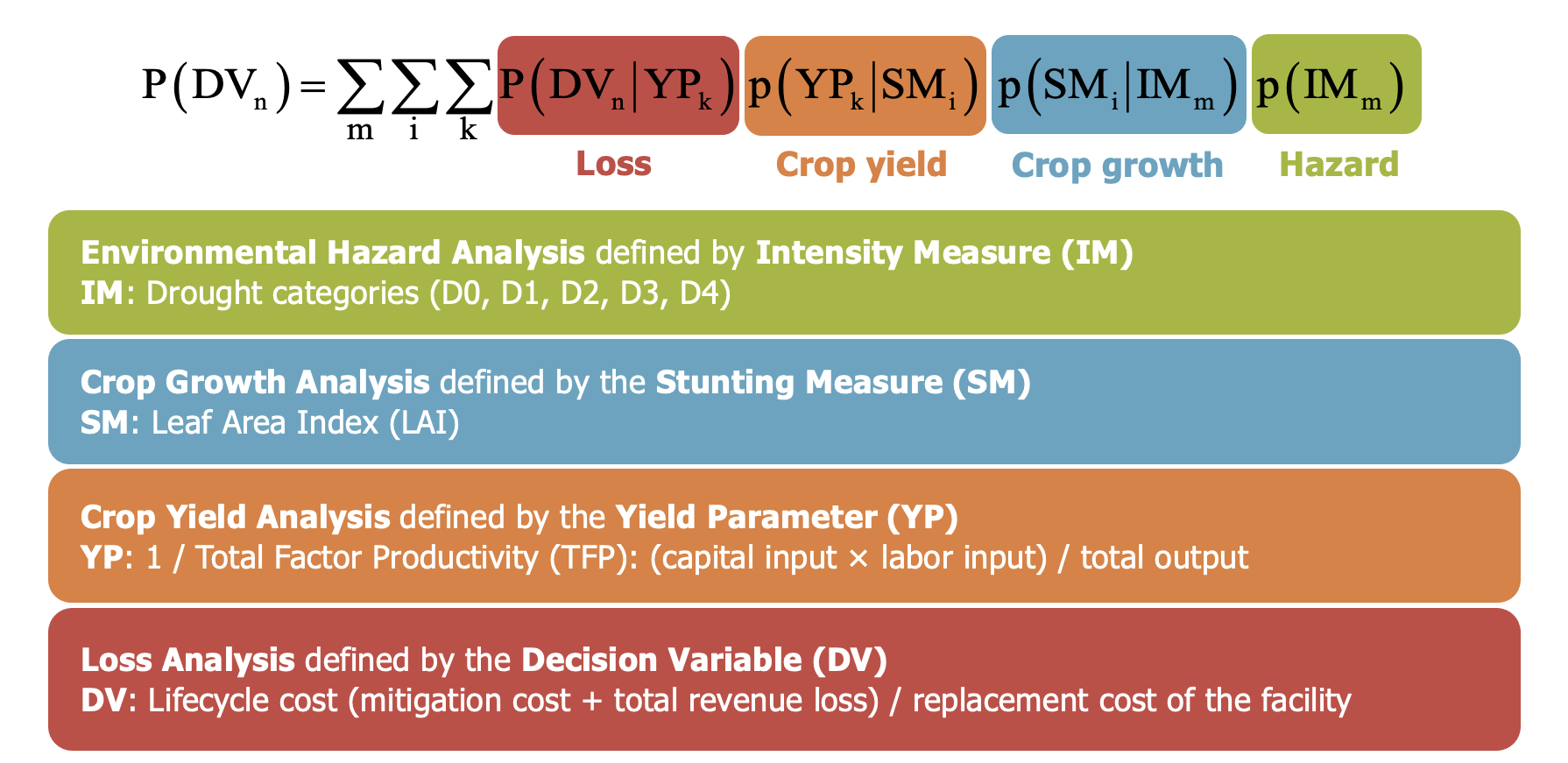
PBFE consists of four phases (environmental hazard analysis, crop growth analysis, crop yield analysis and loss analysis) and uses the total probability theorem to compute the loss curve which represents the Probability of Exceedance (POE) of different values of a Decision Variable (DV). We developed the Python script for implementing the PBFE methodology, where the selections of the variables in each phase are shown in Figure 2.
Figure 2. PBFE formulation and variable selections.
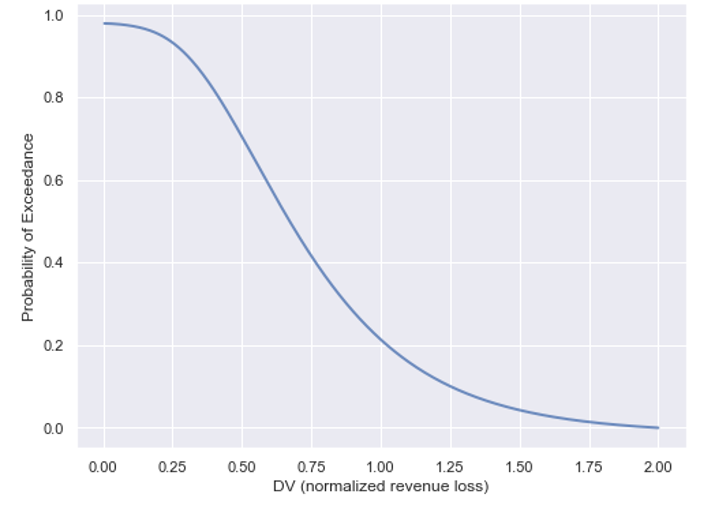
A branch graph (Figure 3) can be used to visualize the computations and to clarify the formulation and the numerical process. Since currently there is not sufficient data to quantify the probabilities, the developed script used some hypothetical values for each phase, resulting in the loss curve shown in Figure 4 as a demonstrative application.
Figure 3. Branch graph for the formulation process visualization.
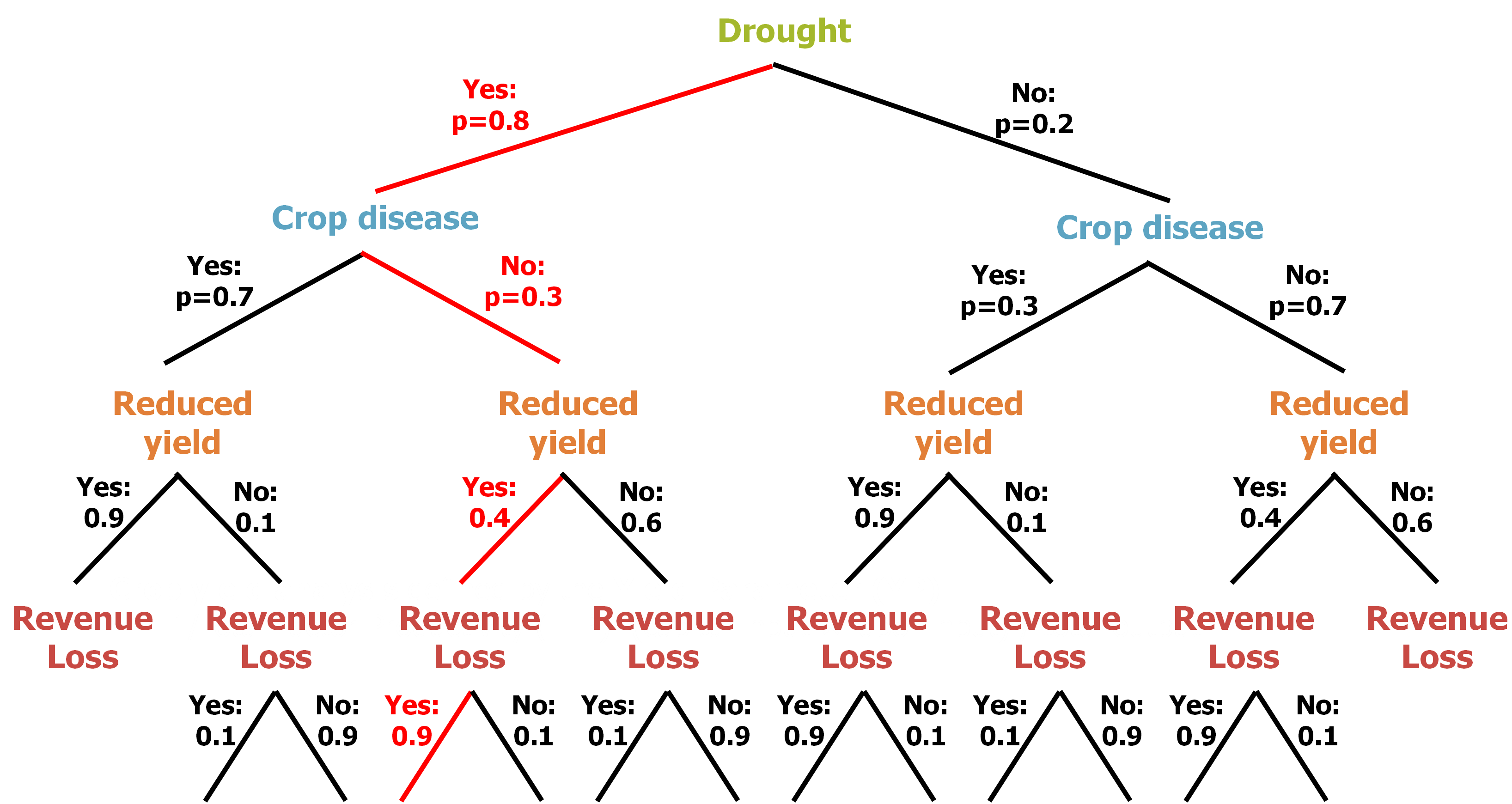
Figure 4. Example loss curve obtained by the PBFE methodology.
We selected drought as the environmental hazard variable in phase 1. For environmental hazard analysis, we collected weather data in California and developed a decision tree and a random forest model for drought classifications (D0, D1, D2, D3, & D4). The details and results can be found in the ./scripts/drought folder.
This code has been tested with Python 3.8.
To prevent dependency problems, please use either virtualenv
# Activate Python virtualenv
virtualenv env_name
source ./env_name/bin/activate # Linux or Mac
# Dectivate Python virtualenv
deactivate
or conda.
# Activate Conda environment
conda create -n env_name python=3.8
# Deactivate Conda environment
conda deactivate
These platforms are convenient since they have the mostly used Python libraries pre-installed. If any error is incurred, please install the required python packages in your environment according to the error message.
The code for PBFE execution is straightforward and ready to use with the proper configuration of the parameters in four different phases.
In order to reproduce the results in the drought prediction work, please follow the detailed steps below to run the code.
Download all the input weather data following the instructions in the script.
Preprocessing the weather data for training the model, split the data into train, test, and validation sets.
Train the decision tree/random forest model.
- Khalid M. Mosalam1,2,3
- Fan Hu1,3
- Department of Civil and Environmental Engineering, University of California at Berkeley
- Pacific Earthquake Engineering Research (PEER) Center, University of California at Davis
- USDA/NSF AI Institute for Next Generation Food Systems (AIFS)
For any questions, please contact us at [email protected].
Citation will be updated later.
This project is licensed under the [Name of license]. Please see the LICENSE file for details.
Acknowledgements will be updated later.
- USDA-NIFA AI Institute for Next Generation Food Systems (AIFS), USDA-NIFA award number 2020-67021-32855.