
- 转载请注明出处
- 严禁商用化
大声告诉我,今天咋们摸鱼团队要来干什么? 什么?看B站?呃(⊙o⊙)…不对,今天咋们要来干掉B站的图文验证码!
觉得啰嗦的可以跳过这一段
相同类似的文章,我也有发表过,就比如《【JS】去NM的视频广告》干掉了“爱奇艺、腾讯、芒果Tv”的视频广告,当然还有没(bu)发(gan)表(fa)过(biao)的文章,就比如《xx在线视频加速攒分》、《xx大学在线考试一键满分》、《xx游戏自动xx脚本》等等等等
他们都是利用一种语言或多种语言协作开发并利用某种漏洞做成的xx脚本
但今天摸鱼大队长遇到难题了,之前做的一类脚本被人私信说不好用了,说是出现了验证码问题,我笑了笑,验证码我又不是没解决过,xx游戏的脚本就有我写的破解验证码呢,我怀着傲视群雄的心情点开了那个网站,结果我心态崩了,TM是图文顺序验证码
图文顺序验证码比起普通字母数字组合的验证码,那破解难度是“蹭蹭蹭”直线飙升的,暂不说复杂多样的背景图,就连简单的文字区域选取都很难,更别说先后顺序排列了,现在回过头来看看,文字数量的分割反倒是最简单的了
 ̄□ ̄||
直接供上代码,给大家测试
优势:
- 无任何引用库,手写OCR识别(只做到了选取位置)
- 源码共800余行,含注释等其他200行
- 不带机器学习及数据库,多种算法一次到底,控制台粘贴就能用
- 无风险,不管是代码本身还是B站都不会对页面产生崩溃或账号封停,刷新即止
注意:
- 几乎不可能一次成功,快的十几秒,慢的十几分钟 -_-|| 你或许可以干点其他事儿,它会循环到直到登录进去才停止
- 若无反应,可能B站更新了
- 偶尔B站会呈现普通验证码或拉块 ,届时请等到图文验证码时再做测试
操作步骤:
- 打开B站,输入账号密码(可随便填)点击登录,调出图文验证码
- 点击下方链接将代码粘贴至控制台 - 回车 即可


知道OCR的同学应该都知道识别的工作都是从像素点出发的,人虽然能认出字体,但机器却不能识别出图案里的文字,因为对它来说,全是N*N的RGB像素点,这就相当于让一位大猩猩来看图画,指出图画中文字那么困难 诶?你说大猩猩也能指出文字?那他一定发现了这个东西跟图画中不同的点,这就叫做差异点 机器亦然
图文就如同重构视网膜,算法就相当于大猩猩的想法,那他是如何实现的呢?请往下看~

我没用到数据库,所以我也没写关于机器学习的算法,也就是我们没法训练大猩猩,告诉他这个就是文字,所以可行性就非常重要了,你也不能全指望大猩猩是不是?
看验证码是非常重要的工程,以B站为例,我们先替大猩猩看看图案,先刷新个几张看看效果,得出属于自己的结论,若你没有想法,那大猩猩还是帮他关回动物园吧
思考结论:
- 2 ≤ 文字 ≤ 4
- 背景多样,几乎几十张才看到相同的一张
- 图案中文字颠倒,与示例文字大小不一且微微扭曲,字体不同,粗细偶尔也不同
- 图案中文字与背景的对比度较大
可别小看了这几个结论,每个结论都会影响到结果
可行性结论:
- 不需要识别这是什么字,只要知道这是字(或跟所示例的东西)差不多就行了
- 有些文字跟图案的色差还是蛮大的,对比值或许可以
- 所示例的文字跟图案中的文字还是挺像的,旋转好角度,放到图案中似乎可以
经过各种思考,我还是选择了色差比较(对比度)
但对比度也不是轻轻松松就可以的,复杂度高的我们就不要了(就像给大猩猩识别验证码,复杂的图案给了也毫无意义)
断舍离,该减减该删删
1、背景与文字高度耦合,文字都有渐变色了,我们识不识别?——不识别,这花费的代价是可怕的,而且成功率还不高(但事实上还是识别了,因为我们用的就是高对比度抓取,这判断都不好判断呀 - 结果一定是失败,虽然我们知道,但也无可奈何)

2、背景相当复杂,饱和度高,色差严重,这类我们识不识别?——不识别,密集的高色差对我们的采集非常不利,一张图会出现相当多的差异点,也就是捕获到高对比度的像素点,若是超过7000,咋们就不识别了(7000源自于调试里的值)

3、4个字识不识别?——不识别,这倒不是因为抓取困难,而是因为这对我们后边的指认顺序,增加了非常大的难度

那我们该识别的是哪种?是这种(文字比较鲜明,颜色较单一,与背景图格格不入的这种)

还有这种

识别的顺序,开发的顺序,都得在这一步想好,想好了才有规划,才能脚踏实地的成功
1、点击顺序:
可行性考虑了,高复杂的舍去了,我们最后来看下简单的点击顺序
为什么说简单?当然识别并不简单,这里的简单指的是我们无路可走——只有像素点统计比较
因为前面的色差抓取并不能保证抓住的一定是文字,所以我们后面的算法会比较单一(当然也可以做复杂的比较,但我感觉收益不高)
2、开发顺序
- 先分割示例文字,并计算文字数量跟统计各个文字的像素点
- 抓取图案中色彩差异较高的部分,储存
- 对储存的像素点做一系列处理
- 对识别出的位置(区块)进行像素点统计,并与示例文字的统计结果进行比对
- 顺序打点
看不懂没关系,下面我们一步一步来
最好先fork后,切换到 1.0.0分支 进行阅读
示例图案

图片对应项目目录 - img/4.jpg
没错,B站的图案跟文字示例是黏在一块的,是一张图,我们得把他分开,利用ctx.drawImage变成单独的一张图(canvas)(函数:verImgInit)

然后对齐进行分割统计等处理(函数:verImgHandle)查看效果可将以下代码注释
// ...
// 计算像素点
const arr = this.textPix();
// ...以及对(函数:isCheckThickness)取消部分注释
data[_i] = 255; // red
data[_i + 1] = 0; // green
data[_i + 2] = 0; // blue使用Live Server扩展或打开服务器,发现一共有五条直线穿插了下来,没错,这就是我们的分割判断,B站拥有以下三种情况

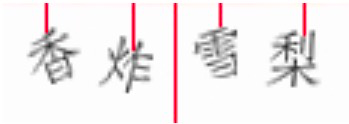

所以我按以上情况写了(函数:checkNumber)判定函数
checkNumber() {
let { canvas, width, ctx } = this.data.verImg;
let imageData = ctx.getImageData(0, 0, canvas.width, canvas.height);
let data = imageData.data;
const mid = parseInt(width / 4 / 2) * 4;
this.data.verImg.imageData = imageData;
// 测试是否有值
let isL1 = this.isCheckThickness(mid, width);
let isL2 = this.isCheckThickness(mid + parseInt(width / 4) * 4, width);
let isL3 = this.isCheckThickness(mid + (width / 2) * 4, width);
let isL4 = this.isCheckThickness(mid * 3 + (width / 2) * 4, width);
// 处理特殊情况 - 居中线
let isL5 = this.isCheckThickness(mid * 2 + (width / 2) * 2, width);
// 都碰到为4
if (isL1 && isL2 && isL3 && isL4) {
return 4;
}
// 中间没擦到
else if (!isL5) {
return 2;
}
return 3;
}有了数量的判定,我们就可以轻松将“不可行性3”给舍去
if (num > 3) {
console.warn("识别数字大于3,跳过");
this.call.fail();
return;
}接下来将(函数:verImgHandle)被注释的部分还原会出现红色全部覆盖的情况
const arr = this.textPix();这是因为按分割线进行了竖向像素点计算,相关代码可到(函数:textPix)注释以下代码查看
if (num === 3) {
arr.push(
{
key: 0,
val: this.isCheckThickness(
mid + parseInt(width / 4) * 4 - 4,
width,
mid + parseInt(width / 4) * 4,
true
)
},
// {
// key: 1,
// val: this.isCheckThickness(
// mid + (width / 2) * 4,
// width,
// width,
// true
// )
// },
// {
// key: 2,
// val: this.isCheckThickness(
// width * 4 - 4,
// width,
// mid + parseInt(width / 4) * 4,
// true
// )
// }
);
}

chooseNo 这是像素点大小的排列,跟后面的点击顺序有关 如此,从左到右黑色像素点就统计出来了(函数:isCheckThickness),分割示例文字,统计像素点的流程就到此结束
每个像素点都含有RGB三种颜色,对比实在是太麻烦了,为了简单易用,我们先将图案置灰,只取中间色(函数:grayscale)
grayscale() {
const{ imageData } = this.data.img;
let data = imageData.data;
for (let i = 0; i < data.length; i += 4) {
let avg = (data[i] + data[i + 1] + data[i + 2]) / 3;
data[i] = avg;
data[i + 1] = avg;
data[i + 2] = avg;
}
this.data.img.ctx.putImageData(imageData, 0, 0);
}如此RGB变成了一种颜色,我们今后只取data[i]即可,因为三类颜色都变成了相同 为什么是 i += 4,因为每个像素点都包含3种颜色+1饱和度,所以 i = 0时(0,1,2,3)的值都是同一个像素点,而260 * 260的图案像素点数组即是 260 * 260 * 4

有没有发现文字反而变清晰了?
我们将采取对比度判断(函数:pixels),其实函数里注释都写了-_-|| 希望大家也要养成边开发边写注释的好习惯
pixels() {
const { imageData, countAvg, countStart, countEnd } = this.data.img;
// 前后对比值 突然超过 80 且 超过后在 > 2 < 10 个像素点内 比开始的对比值高 即可
// 若超过10个像素仍然很高,则放弃
const _this = this;
let data = imageData.data;
let preVal,
nowVal,
isBig,
bigCount = 0,
bigData = [];
for (let i = 0, j = 0; i < data.length; i += 4, j += 4) {
if (!preVal) {
preVal = data[i];
// 当前无值,则跳过第一次
if (!nowVal) {
continue;
}
}
nowVal = data[i];
if (Math.abs(preVal - nowVal) > countAvg && bigCount < countEnd) {
bigCount++;
bigData.push(i);
} else {
bigCount = 0;
bigData = [];
preVal = data[i];
}
if (bigCount > countStart && bigCount < countEnd) {
for (let _i = 0; _i < bigData.length; _i++) {
data[bigData[_i]] = 0; // R
data[bigData[_i] + 1] = 255; // G
data[bigData[_i] + 2] = 0; // B
_this.data.img.bigData.push(bigData[_i]);
}
bigData = [];
}
}
this.data.img.ctx.putImageData(imageData, 0, 0);
}
就这样我们捕获到了1663个有效点位 诶?好像有什么奇怪的东西捕获进去了?没关系,咋们只是第一步,只要保证文字含有绿色的条条就行
最耗时的一步(耗cpu),没有之一(函数:recHandle)
首先我们先将上一步捕获到的点进行判断,若是太多,我们也不计算了(去除 不可行性2)
if (bigData.length > bigDataMax) {
console.warn(
`捕获到超出${bigDataMax}的像素点,过于复杂不计算`,
bigData.length
);
this.call.fail();
return;
}
if (!bigData.length) {
console.warn("无像素点捕获,退出");
this.call.fail();
return;
}接下来是重点,我们对每一个点位进行算法处理——建立矩形选框,也就是 以当前点位为中心,创建 50 * 50 大小的正方形
当然在边边角角的像素点是不可能实现的,所以我们还得先做边界处理
// 列
let line =
bigData[i] - parseInt(recWidth / 2) * (nextCol - recWidth * 4);
// 防止突破顶端
if (line <= 0) {
line = bigData[i] - parseInt(recWidth / 2) * 4;
}
// 防止突破左端
if (nextCol - (line % nextCol) <= recWidth * 4) {
line += recWidth * 4 - (nextCol - (line % nextCol));
}
// 防止突破右端
if (nextCol - (line % nextCol) <= recWidth * 4) {
line -= recWidth * 4 - (nextCol - (line % nextCol));
}代码大意就是当 像素点在xx 时,可没办法 以当前点位为中心,创建 50 * 50 大小的正方形 所以我们得偏移下位置
终于可以做降噪处理了(去除无效点位)
我们对 50 * 50 大小的正方形 进行有效点收集(也就是上面捕获到的点位),收集到了1663个,而这1663个内包含了各自的有效点位以及sum值

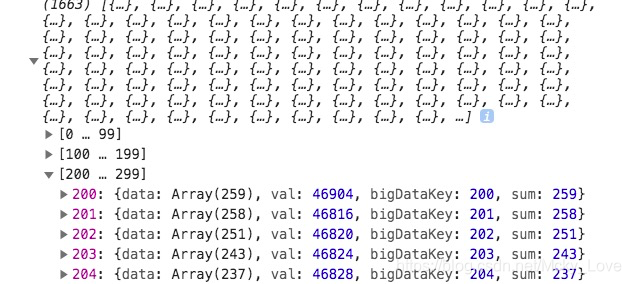
我们发现1663个点位有好多是自成一派,50 * 50 大小的正方形选框 里,根本没它点位(边缘点位),而一些点位数量参差不齐,我们再做处理,将所有数组进行去重
// 升序
recData = recData.sort(this.compare("sum"));
// 综合去重
recData = this.dupRemoval(recData);
// 去除范围杂质
recData = this.dupImpurity(recData, dupImpurityValue);其中(函数:dupImpurity)的 dupImpurityValue = 200 值 依然是个估计值,意思为矩形数组内低于 200 有效像素点的矩形不考虑,但是,若所有像素点都低于200怎么办?岂不是达不到示例文字的个数了?所以我们再做处理
// 去杂质 --- 递归直到算到符合校验的个数
dupImpurity(data, val) {
const { num } = this.data.verImg;
let newData = [];
data.map(item => item.sum >= val && newData.push(item));
if (newData.length < num) {
return this.dupImpurity(data, val - 10);
}
return newData;
}
这样来看,已经差不多了,但事实才刚刚开始
我们捕获到了三组有效矩形,1663的有效点数,降噪后也降到了890,但依然不行,因为这个点位根本没集中到文字上,这对后面的顺序排列会造成影响
我们对这三组有效矩形(50 * 50 正方形)进行中心点位判断,扩大选区(80 * 80 正方形),渲染正确的位置并进行储存(函数:recRender)

在这里,我们需要再次进行捕获高对比度像素点,但这时已经不是初次这么困难了,我们只对矩形范围内的有效像素点进行捕捉(函数:computePix)
对之前捕捉到的矩形像素点进行color转换,排序,得到colorMax值,作为这条街最靓的仔
然后,重新捕捉!对 80 * 80 正方形 再次执行色彩比较,符合则填充为红色,顺便计算像素点数
// 矩形个数
colorArr.map((item, _i) => {
// 80 * 80 像素点
item.recRenderData.map(i => {
if (Math.abs(data[i] - item.colorMax) < diff) {
item.sum++;
data[i] = 255;
data[i + 1] = 0;
data[i + 2] = 0;
}
});
// ...
})在这个新正方形里,我们再次进行矩形降噪,对矩形选框进行长条、竖条等规则的像素点进行删除 - 以及减去已经捕获进的sum值
// 矩形去噪 --- 是否要从 大 到小 递归下continuityDiff值?因为有些图去不掉
// --- 太麻烦了,算了
// 还有各种 纵横长方形的东西 - 长,高,diff值
// 长条
this.recRenderDataFilter(
item,
data,
"longRec",
continuityDiff * 4,
continuityDiff * width,
continuityDiff
);
// 竖条
this.recRenderDataFilter(
item,
data,
"heightRec",
continuityDiff,
continuityDiff * width * 2 * 2,
continuityDiff
);结束后,我们顺便再计算矩形的居中值,作为后续打点的x、y
// 计算居中值 - 不是取值的居中数而是取数组的中间数
// 矩形像素点为偶数
if (item.recRenderData.length % 2 === 0) {
// 列数 + 行数 = 居中数
item.xyCenter =
item.recRenderData[
item.recRenderData.length / 2 +
Math.sqrt(item.recRenderData.length) / 2
];
} else {
// 奇数
item.xyCenter =
item.recRenderData[parseInt(item.recRenderData.length / 2)];
}
// 计算坐标
item.x = ((item.xyCenter / 4) % width) - 10;
item.y = (item.xyCenter / 4 - item.x) / width - 10;效果

这样就已经差不多了,如果在执行(函数:computePix)之前,先执行(函数:rezCanvas)下,能看更到更真实的效果

到这一步,图案的处理告一段落
终于来到这一步了,我们将示例文字统计的像素点与矩形选框内的有效像素点进行比对,得到结果(函数:posRender)


诶?发现问题没有
示例文字 --- 玉:270,带:468,糕:495 图文文字 --- 玉:372,带:662,糕:851
大小好像不相符,但这已经是不是问题的问题了,我们将其递归一下就简单结束此章
// 若最相近的点位找不到,则扩大diff值递归
if (txAlArr.length < textArr.length) {
this.posRender(diff + 30, txAlArr, colorAlArr);
}根据 x、y 值按 chooseNo 顺序打点

tips:只要有一类可行,那就是在这成百上千的验证码中,它也是有一定的几率
make:o︻そ╆OVE▅▅▅▆▇◤(清一色天空)
blog:http://blog.csdn.net/mcky_love
掘金:https://juejin.im/user/59fbe6c66fb9a045186a159a/posts
lofter:http://zcxy-gs.lofter.com/
sf:https://segmentfault.com/u/mybestangel
git:https://github.com/gs3170981
脚本呢当然是完成了,但上面的脚本可不是我交付给甲方的脚本哦,毕竟该类产品准确率,效率速度都会是纳入考核的标准,而且破解类都跟某些东西有关,有小小的风险,所以我找上了B站花了5天时间研发给大家玩,希望大家在使用的同时对OCR乃至AI产生兴趣~ 下一篇不出意外,可能我会写机器学习,监督学习类的文章,破解率高达99%的那种