I created this framework to allow developers to integrate and use the functionality of llama.cpp in their apps targeting iOS and MacOS development.
The framework allows the developers to implement OpenAI chatGPT like LLM (large language model) based apps with theLLM model running locally on the devices: iPhone (yes) and MacOS with M1 or later machine. Developers can essentially build apps that allow the users to chat with the files locally on their device, or contents of internet documents without relying on OpenAI's GPT which does not have any knowledge of the users' documents (of course unless you have mastered embedding technology which could be expensive at additional charges). Since users' documents stay local, this does provide a tremendous advantage in privacy protection. Any business definitely does not want to leak the contents of their internal documents to competitors or hackers because of the need to upload embeddings of the documents or the document itself to the cloud.

- Clone the repo: git clone https://github.com/fdchiu/llamaFramework.git
- Open Xcode project:
llamaFramework/ExampleApps/LlamaExampleApp.xcodeproj
Tested Xcode version: 15.0.1
You can choose to build either iOS or MacOS app. 3. Download Models: Download the models from huggingface. This model is tested with the sample apps:
https://huggingface.co/TheBloke/Mistral-7B-v0.1-GGUF/blob/main/mistral-7b-v0.1.Q4_K_M.gguf
-
MacOS
-
iOS
The first release included two example apps: one for iOS and another MacOS. The supported versions are:
- iOS: 16.0 or later, iPhone 11 or later
- MacOS, preferably M1 or later
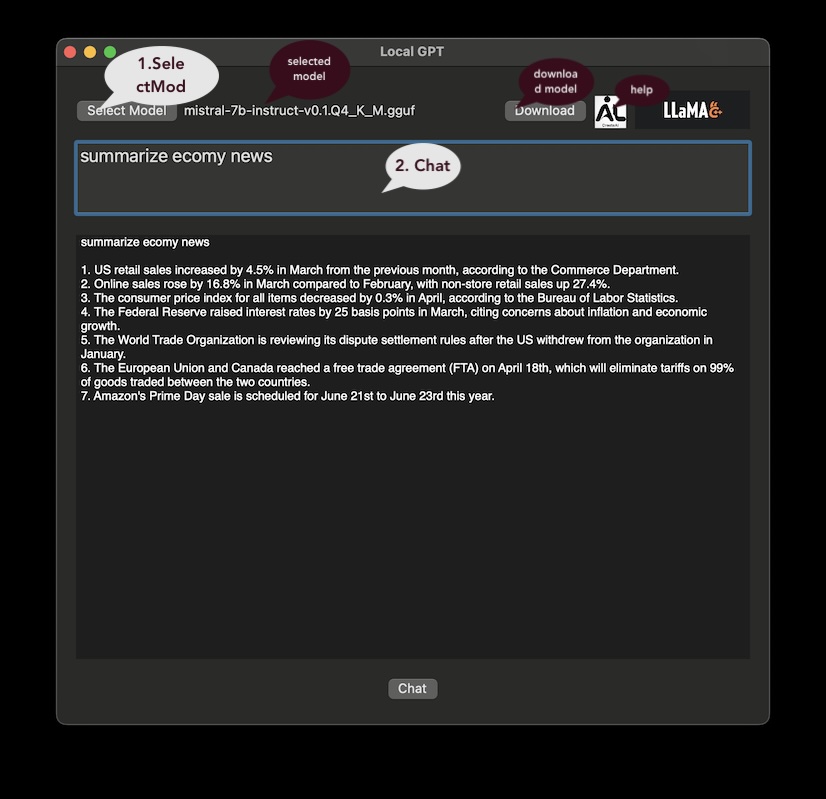
A chat session running on MacBook M1 device:
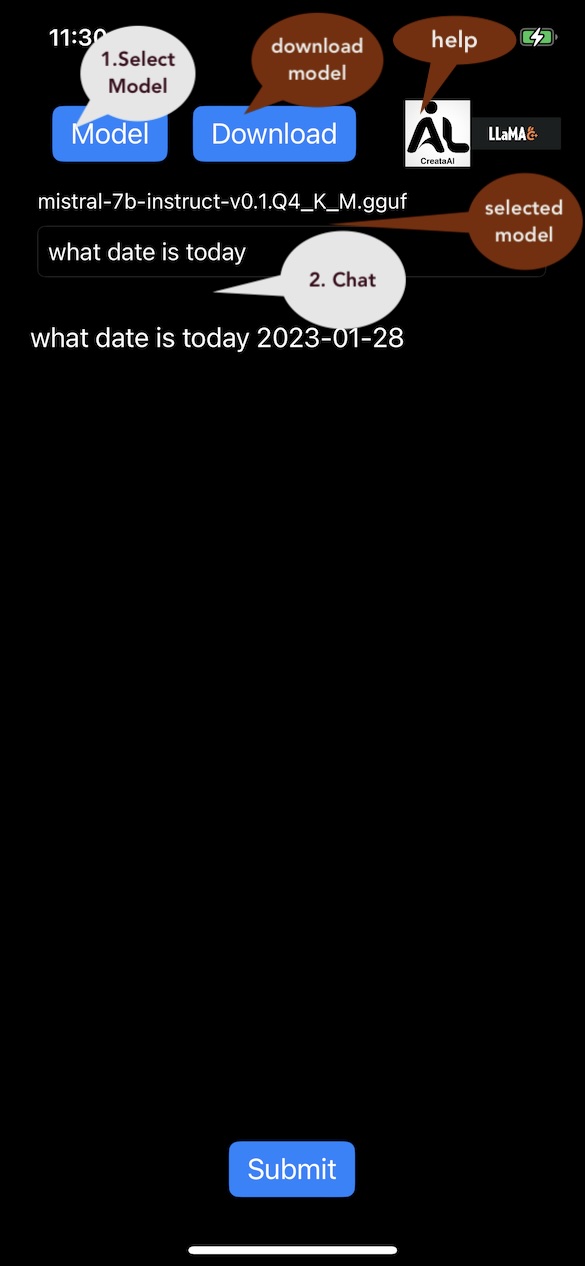
A chat session running on iOS:
Note: The code makes use of Apple's metal GPU to accelerate the token generation, but it's still very slow and not good for practical use.
- iOS: the app takes 4 seconds to generate one word (token)
- MacBook M1: 0.040 second for one token. or 25 tokens per second which is acceptable
Recommended models are 7B or 13B quantized Llama models in gguf format. The following models are tested with the apps and llama.cpp:
- mistral-7b-v0.1.Q4_K_M.gguf: https://huggingface.co/TheBloke/Mistral-7B-v0.1-GGUF/blob/main/mistral-7b-v0.1.Q4_K_M.gguf
- mistral-7b-instruct-v0.1.Q4_K_M.gguf: https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GGUF/blob/main/mistral-7b-instruct-v0.1.Q4_K_M.gguf
In general, mistral-7b-v0.1.Q4_K_M.gguf is good for chat applications, while mistral-7b-instruct-v0.1.Q4_K_M.gguf for chat and instruction. Here instruction means the model accepts instruction such as:
" write an article...", "create code for...", " summarize today's news" etc..
Please refer to the model creator and trainer's original documentation for accurate description. The user is responsible to follow model providers license requirements, while this framework does not offer commercial use without authorization.
- mistral-7b-v0.1.Q4_K_M.gguf: https://drive.google.com/file/d/1_v9mmGKuDzwJkWFvZnWaasJ6pTcJrinH/view?usp=share_link
- mistral-7b-instruct-v0.1.Q4_K_M.gguf: https://drive.google.com/file/d/1fX84uLGhvUjuIzM9l9Z8t_Pv3EEXksU5/view?usp=share_link
| Model Parameters | Size | Required PC RAM | For iOS | For MacBook/PC/Linux |
|---|---|---|---|---|
| 7B | ~4 to 5 GB | 8 GB | Yes | *Probably |
| 13B | ~ 7 GB | 16 GB | No | *Probably |
| 30B | ~ 20 GB | 32 GB | No | Try by yourself |
| * As long as the PC has 16 GB or more RAM |
Where 7B means a 7 billion parameter model. More number of parameters the more complex and potentially trained with more data and supposed to be more accurate. As a comparison, OpenAI's GPT-3 model has 175 billion parameters. GPT-4 has 1760 billion parameters. However, none of the Open AI models can run on a PC, obviously.
One can potentially build any LLM application, which include but not limited to:
- Q&A apps where users can ask questions about the documents
- Knowledge base with AI
- AI agent
- AI assistant
- AI help system
- Customer support
The current version runs interference of LLM models. It's just a starting point. The initial version is released as an experiment to gauge developer tracktion and interest. It lacks support for direct embedding, vector database and similarity search that further improve the performance and make the framework practical and really useful for building LLM based products and fully leverage AI's capabilities.
If you are interested in joining the force or sending pull requests, please do so.
This repo is for non-commercial use, and users who download or fork the repo must follow the terms and conditions of the following license: Creative Commons Attribution-NonCommercial (CC BY-NC) For details about the license, see here this page