Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
[8.x] [Security Solution] [Attack discovery] Output chunking / refine…
…ment, LangGraph migration, and evaluation improvements (#195669) (#196334) # Backport This will backport the following commits from `main` to `8.x`: - [[Security Solution] [Attack discovery] Output chunking / refinement, LangGraph migration, and evaluation improvements (#195669)](#195669) <!--- Backport version: 9.4.3 --> ### Questions ? Please refer to the [Backport tool documentation](https://github.com/sqren/backport) <!--BACKPORT [{"author":{"name":"Andrew Macri","email":"[email protected]"},"sourceCommit":{"committedDate":"2024-10-15T14:39:48Z","message":"[Security Solution] [Attack discovery] Output chunking / refinement, LangGraph migration, and evaluation improvements (#195669)\n\n## [Security Solution] [Attack discovery] Output chunking / refinement, LangGraph migration, and evaluation improvements\r\n\r\n### Summary\r\n\r\nThis PR improves the Attack discovery user and developer experience with output chunking / refinement, migration to LangGraph, and improvements to evaluations.\r\n\r\nThe improvements were realized by transitioning from directly using lower-level LangChain apis to LangGraph in this PR, and a deeper integration with the evaluation features of LangSmith.\r\n\r\n#### Output chunking\r\n\r\n_Output chunking_ increases the maximum and default number of alerts sent as context, working around the output token limitations of popular large language models (LLMs):\r\n\r\n| | Old | New |\r\n|----------------|-------|-------|\r\n| max alerts | `100` | `500` |\r\n| default alerts | `20` | `200` |\r\n\r\nSee _Output chunking details_ below for more information.\r\n\r\n#### Settings\r\n\r\nA new settings modal makes it possible to configure the number of alerts sent as context directly from the Attack discovery page:\r\n\r\n\r\n\r\n- Previously, users configured this value for Attack discovery via the security assistant Knowledge base settings, as documented [here](https://www.elastic.co/guide/en/security/8.15/attack-discovery.html#attack-discovery-generate-discoveries)\r\n- The new settings modal uses local storage (instead of the previously-shared assistant Knowledge base setting, which is stored in Elasticsearch)\r\n\r\n#### Output refinement\r\n\r\n_Output refinement_ automatically combines related discoveries (that were previously represented as two or more discoveries):\r\n\r\n 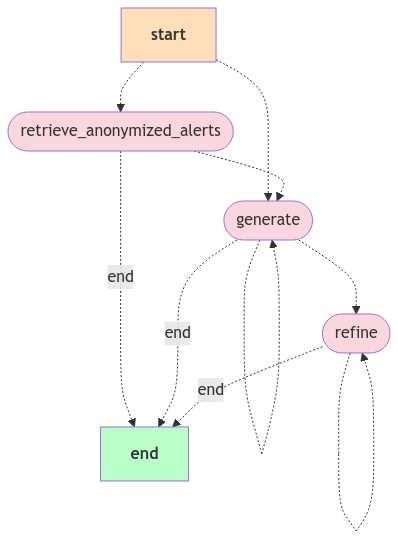\r\n\r\n- The `refine` step in the graph diagram above may (for example), combine three discoveries from the `generate` step into two discoveries when they are related\r\n\r\n### Hallucination detection\r\n\r\nNew _hallucination detection_ displays an error in lieu of showing hallucinated output:\r\n\r\n\r\n\r\n- A new tour step was added to the Attack discovery page to share the improvements:\r\n\r\n\r\n\r\n### Summary of improvements for developers\r\n\r\nThe following features improve the developer experience when running evaluations for Attack discovery:\r\n\r\n#### Replay alerts in evaluations\r\n\r\nThis evaluation feature eliminates the need to populate a local environment with alerts to (re)run evaluations:\r\n\r\n \r\n\r\nAlert replay skips the `retrieve_anonymized_alerts` step in the graph, because it uses the `anonymizedAlerts` and `replacements` provided as `Input` in a dataset example. See _Replay alerts in evaluations details_ below for more information.\r\n\r\n#### Override graph state\r\n\r\nOverride graph state via datatset examples to test prompt improvements and edge cases via evaluations:\r\n\r\n \r\n\r\nTo use this feature, add an `overrides` key to the `Input` of a dataset example. See _Override graph state details_ below for more information.\r\n\r\n#### New custom evaluator\r\n\r\nPrior to this PR, an evaluator had to be manually added to each dataset in LangSmith to use an LLM as the judge for correctness.\r\n\r\nThis PR introduces a custom, programmatic evaluator that handles anonymization automatically, and eliminates the need to manually create evaluators in LangSmith. To use it, simply run evaluations from the `Evaluation` tab in settings.\r\n\r\n#### New evaluation settings\r\n\r\nThis PR introduces new settings in the `Evaluation` tab:\r\n\r\n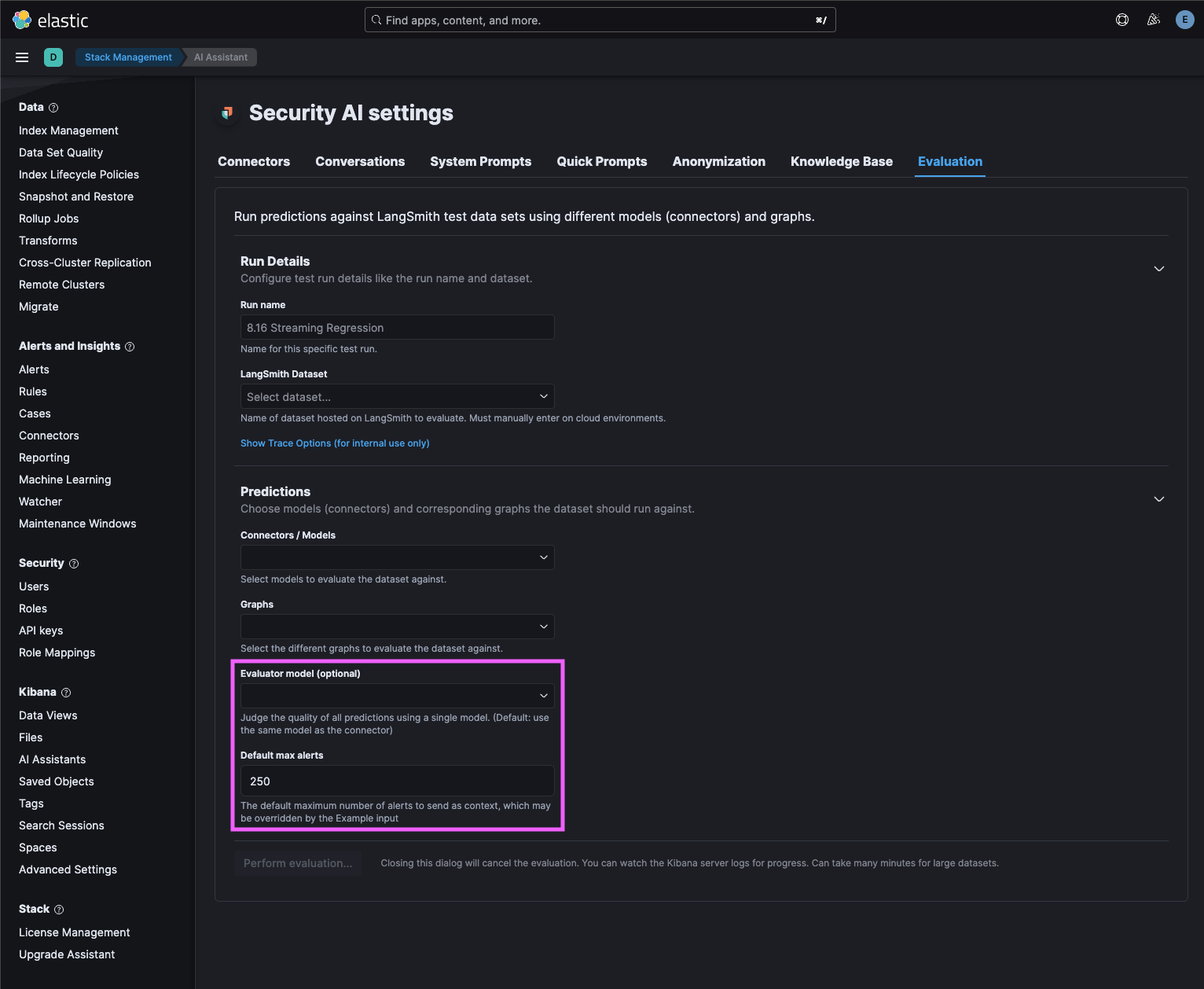\r\n\r\nNew evaluation settings:\r\n\r\n- `Evaluator model (optional)` - Judge the quality of predictions using a single model. (Default: use the same model as the connector)\r\n\r\nThis new setting is useful when you want to use the same model, e.g. `GPT-4o` to judge the quality of all the models evaluated in an experiment.\r\n\r\n- `Default max alerts` - The default maximum number of alerts to send as context, which may be overridden by the example input\r\n\r\nThis new setting is useful when using the alerts in the local environment to run evaluations. Examples that use the Alerts replay feature will ignore this value, because the alerts in the example `Input` will be used instead.\r\n\r\n#### Directory structure refactoring\r\n\r\n- The server-side directory structure was refactored to consolidate the location of Attack discovery related files\r\n\r\n### Details\r\n\r\nThis section describes some of the improvements above in detail.\r\n\r\n#### Output chunking details\r\n\r\nThe new output chunking feature increases the maximum and default number of alerts that may be sent as context. It achieves this improvement by working around output token limitations.\r\n\r\nLLMs have different limits for the number of tokens accepted as _input_ for requests, and the number of tokens available for _output_ when generating responses.\r\n\r\nToday, the output token limits of most popular models are significantly smaller than the input token limits.\r\n\r\nFor example, at the time of this writing, the Gemini 1.5 Pro model's limits are ([source](https://ai.google.dev/gemini-api/docs/models/gemini)):\r\n\r\n- Input token limit: `2,097,152`\r\n- Output token limit: `8,192`\r\n\r\nAs a result of this relatively smaller output token limit, previous versions of Attack discovery would simply fail when an LLM ran out of output tokens when generating a response. This often happened \"mid sentence\", and resulted in errors or hallucinations being displayed to users.\r\n\r\nThe new output chunking feature detects incomplete responses from the LLM in the `generate` step of the Graph. When an incomplete response is detected, the `generate` step will run again with:\r\n\r\n- The original prompt\r\n- The Alerts provided as context\r\n- The partially generated response\r\n- Instructions to \"continue where you left off\"\r\n\r\nThe `generate` step in the graph will run until one of the following conditions is met:\r\n\r\n- The incomplete response can be successfully parsed\r\n- The maximum number of generation attempts (default: `10`) is reached\r\n- The maximum number of hallucinations detected (default: `5`) is reached\r\n\r\n#### Output refinement details\r\n\r\nThe new output refinement feature automatically combines related discoveries (that were previously represented as two or more discoveries).\r\n\r\nThe new `refine` step in the graph re-submits the discoveries from the `generate` step with a `refinePrompt` to combine related attack discoveries.\r\n\r\nThe `refine` step is subject to the model's output token limits, just like the `generate` step. That means a response to the refine prompt from the LLM may be cut off \"mid\" sentence. To that end:\r\n\r\n- The refine step will re-run until the (same, shared) `maxGenerationAttempts` and `maxHallucinationFailures` limits as the `generate` step are reached\r\n- The maximum number of attempts (default: `10`) is _shared_ with the `generate` step. For example, if it took `7` tries (`generationAttempts`) to complete the `generate` step, the refine `step` will only run up to `3` times.\r\n\r\nThe `refine` step will return _unrefined_ results from the `generate` step when:\r\n\r\n- The `generate` step uses all `10` generation attempts. When this happens, the `refine` step will be skipped, and the unrefined output of the `generate` step will be returned to the user\r\n- If the `refine` step uses all remaining attempts, but fails to produce a refined response, due to output token limitations, or hallucinations in the refined response\r\n\r\n#### Hallucination detection details\r\n\r\nBefore this PR, Attack discovery directly used lower level LangChain APIs to parse responses from the LLM. After this PR, Attack discovery uses LangGraph.\r\n\r\nIn the previous implementation, when Attack discovery received an incomplete response because the output token limits of a model were hit, the LangChain APIs automatically re-submitted the incomplete response in an attempt to \"repair\" it. However, the re-submitted results didn't include all of the original context (i.e. alerts that generated them). The repair process often resulted in hallucinated results being presented to users, especially with some models i.e. `Claude 3.5 Haiku`.\r\n\r\nIn this PR, the `generate` and `refine` steps detect (some) hallucinations. When hallucinations are detected:\r\n\r\n- The current accumulated `generations` or `refinements` are (respectively) discarded, effectively restarting the `generate` or `refine` process\r\n- The `generate` and `refine` steps will be retried until the maximum generation attempts (default: `10`) or hallucinations detected (default: `5`) limits are reached\r\n\r\nHitting the hallucination limit during the `generate` step will result in an error being displayed to the user.\r\n\r\nHitting the hallucination limit during the `refine` step will result in the unrefined discoveries being displayed to the user.\r\n\r\n#### Replay alerts in evaluations details\r\n\r\nAlerts replay makes it possible to re-run evaluations, even when your local deployment has zero alerts.\r\n\r\nThis feature eliminates the chore of populating your local instance with specific alerts for each example.\r\n\r\nEvery example in a dataset may (optionally) specify a different set of alerts.\r\n\r\nAlert replay skips the `retrieve_anonymized_alerts` step in the graph, because it uses the `anonymizedAlerts` and `replacements` provided as `Input` in a dataset example.\r\n\r\nThe following instructions document the process of creating a new LangSmith dataset example that uses the Alerts replay feature:\r\n\r\n1) In Kibana, navigate to Security > Attack discovery\r\n\r\n2) Click `Generate` to generate Attack discoveries\r\n\r\n3) In LangSmith, navigate to Projects > _Your project_\r\n\r\n4) In the `Runs` tab of the LangSmith project, click on the latest `Attack discovery` entry to open the trace\r\n\r\n5) **IMPORTANT**: In the trace, select the **LAST** `ChannelWriteChannelWrite<attackDiscoveries,attackDisc...` entry. The last entry will appear inside the **LAST** `refine` step in the trace, as illustrated by the screenshot below:\r\n\r\n\r\n\r\n6) With the last `ChannelWriteChannelWrite<attackDiscoveries,attackDisc...` entry selected, click `Add to` > `Add to Dataset`\r\n\r\n7) Copy-paste the `Input` to the `Output`, because evaluation Experiments always compare the current run with the `Output` in an example.\r\n\r\n- This step is _always_ required to create a dataset.\r\n- If you don't want to use the Alert replay feature, replace `Input` with an empty object:\r\n\r\n```json\r\n{}\r\n```\r\n\r\n8) Choose an existing dataset, or create a new one\r\n\r\n9) Click the `Submit` button to add the example to the dataset.\r\n\r\nAfter completing the steps above, the dataset is ready to be run in evaluations.\r\n\r\n#### Override graph state details\r\n\r\nWhen a dataset is run in an evaluation (to create Experiments):\r\n\r\n- The (optional) `anonymizedAlerts` and `replacements` provided as `Input` in the example will be replayed, bypassing the `retrieve_anonymized_alerts` step in the graph\r\n- The rest of the properties in `Input` will not be used as inputs to the graph\r\n- In contrast, an empty object `{}` in `Input` means the latest and riskiest alerts in the last 24 hours in the local environment will be queried\r\n\r\nIn addition to the above, you may add an optional `overrides` key in the `Input` of a dataset example to test changes or edge cases. This is useful for evaluating changes without updating the code directly.\r\n\r\nThe `overrides` set the initial state of the graph before it's run in an evaluation.\r\n\r\nThe example `Input` below overrides the prompts used in the `generate` and `refine` steps:\r\n\r\n```json\r\n{\r\n \"overrides\": {\r\n \"refinePrompt\": \"This overrides the refine prompt\",\r\n \"attackDiscoveryPrompt\": \"This overrides the attack discovery prompt\"\r\n }\r\n}\r\n```\r\n\r\nTo use the `overrides` feature in evaluations to set the initial state of the graph:\r\n\r\n1) Create a dataset example, as documented in the _Replay alerts in evaluations details_ section above\r\n\r\n2) In LangSmith, navigate to Datasets & Testing > _Your Dataset_\r\n\r\n3) In the dataset, click the Examples tab\r\n\r\n4) Click an example to open it in the flyout\r\n\r\n5) Click the `Edit` button to edit the example\r\n\r\n6) Add the `overrides` key shown below to the `Input` e.g.:\r\n\r\n```json\r\n{\r\n \"overrides\": {\r\n \"refinePrompt\": \"This overrides the refine prompt\",\r\n \"attackDiscoveryPrompt\": \"This overrides the attack discovery prompt\"\r\n }\r\n}\r\n```\r\n\r\n7) Edit the `overrides` in the example `Input` above to add (or remove) entries that will determine the initial state of the graph.\r\n\r\nAll of the `overides` shown in step 6 are optional. The `refinePrompt` and `attackDiscoveryPrompt` could be removed from the `overrides` example above, and replaced with `maxGenerationAttempts` to test a higher limit.\r\n\r\nAll valid graph state may be specified in `overrides`.","sha":"2c21adb8faafc0016ad7a6591837118f6bdf0907","branchLabelMapping":{"^v9.0.0$":"main","^v8.16.0$":"8.x","^v(\\d+).(\\d+).\\d+$":"$1.$2"}},"sourcePullRequest":{"labels":["release_note:enhancement","v9.0.0","Team: SecuritySolution","ci:cloud-deploy","ci:cloud-persist-deployment","Team:Security Generative AI","v8.16.0","backport:version"],"title":"[Security Solution] [Attack discovery] Output chunking / refinement, LangGraph migration, and evaluation improvements","number":195669,"url":"https://github.com/elastic/kibana/pull/195669","mergeCommit":{"message":"[Security Solution] [Attack discovery] Output chunking / refinement, LangGraph migration, and evaluation improvements (#195669)\n\n## [Security Solution] [Attack discovery] Output chunking / refinement, LangGraph migration, and evaluation improvements\r\n\r\n### Summary\r\n\r\nThis PR improves the Attack discovery user and developer experience with output chunking / refinement, migration to LangGraph, and improvements to evaluations.\r\n\r\nThe improvements were realized by transitioning from directly using lower-level LangChain apis to LangGraph in this PR, and a deeper integration with the evaluation features of LangSmith.\r\n\r\n#### Output chunking\r\n\r\n_Output chunking_ increases the maximum and default number of alerts sent as context, working around the output token limitations of popular large language models (LLMs):\r\n\r\n| | Old | New |\r\n|----------------|-------|-------|\r\n| max alerts | `100` | `500` |\r\n| default alerts | `20` | `200` |\r\n\r\nSee _Output chunking details_ below for more information.\r\n\r\n#### Settings\r\n\r\nA new settings modal makes it possible to configure the number of alerts sent as context directly from the Attack discovery page:\r\n\r\n\r\n\r\n- Previously, users configured this value for Attack discovery via the security assistant Knowledge base settings, as documented [here](https://www.elastic.co/guide/en/security/8.15/attack-discovery.html#attack-discovery-generate-discoveries)\r\n- The new settings modal uses local storage (instead of the previously-shared assistant Knowledge base setting, which is stored in Elasticsearch)\r\n\r\n#### Output refinement\r\n\r\n_Output refinement_ automatically combines related discoveries (that were previously represented as two or more discoveries):\r\n\r\n \r\n\r\n- The `refine` step in the graph diagram above may (for example), combine three discoveries from the `generate` step into two discoveries when they are related\r\n\r\n### Hallucination detection\r\n\r\nNew _hallucination detection_ displays an error in lieu of showing hallucinated output:\r\n\r\n\r\n\r\n- A new tour step was added to the Attack discovery page to share the improvements:\r\n\r\n\r\n\r\n### Summary of improvements for developers\r\n\r\nThe following features improve the developer experience when running evaluations for Attack discovery:\r\n\r\n#### Replay alerts in evaluations\r\n\r\nThis evaluation feature eliminates the need to populate a local environment with alerts to (re)run evaluations:\r\n\r\n \r\n\r\nAlert replay skips the `retrieve_anonymized_alerts` step in the graph, because it uses the `anonymizedAlerts` and `replacements` provided as `Input` in a dataset example. See _Replay alerts in evaluations details_ below for more information.\r\n\r\n#### Override graph state\r\n\r\nOverride graph state via datatset examples to test prompt improvements and edge cases via evaluations:\r\n\r\n \r\n\r\nTo use this feature, add an `overrides` key to the `Input` of a dataset example. See _Override graph state details_ below for more information.\r\n\r\n#### New custom evaluator\r\n\r\nPrior to this PR, an evaluator had to be manually added to each dataset in LangSmith to use an LLM as the judge for correctness.\r\n\r\nThis PR introduces a custom, programmatic evaluator that handles anonymization automatically, and eliminates the need to manually create evaluators in LangSmith. To use it, simply run evaluations from the `Evaluation` tab in settings.\r\n\r\n#### New evaluation settings\r\n\r\nThis PR introduces new settings in the `Evaluation` tab:\r\n\r\n\r\n\r\nNew evaluation settings:\r\n\r\n- `Evaluator model (optional)` - Judge the quality of predictions using a single model. (Default: use the same model as the connector)\r\n\r\nThis new setting is useful when you want to use the same model, e.g. `GPT-4o` to judge the quality of all the models evaluated in an experiment.\r\n\r\n- `Default max alerts` - The default maximum number of alerts to send as context, which may be overridden by the example input\r\n\r\nThis new setting is useful when using the alerts in the local environment to run evaluations. Examples that use the Alerts replay feature will ignore this value, because the alerts in the example `Input` will be used instead.\r\n\r\n#### Directory structure refactoring\r\n\r\n- The server-side directory structure was refactored to consolidate the location of Attack discovery related files\r\n\r\n### Details\r\n\r\nThis section describes some of the improvements above in detail.\r\n\r\n#### Output chunking details\r\n\r\nThe new output chunking feature increases the maximum and default number of alerts that may be sent as context. It achieves this improvement by working around output token limitations.\r\n\r\nLLMs have different limits for the number of tokens accepted as _input_ for requests, and the number of tokens available for _output_ when generating responses.\r\n\r\nToday, the output token limits of most popular models are significantly smaller than the input token limits.\r\n\r\nFor example, at the time of this writing, the Gemini 1.5 Pro model's limits are ([source](https://ai.google.dev/gemini-api/docs/models/gemini)):\r\n\r\n- Input token limit: `2,097,152`\r\n- Output token limit: `8,192`\r\n\r\nAs a result of this relatively smaller output token limit, previous versions of Attack discovery would simply fail when an LLM ran out of output tokens when generating a response. This often happened \"mid sentence\", and resulted in errors or hallucinations being displayed to users.\r\n\r\nThe new output chunking feature detects incomplete responses from the LLM in the `generate` step of the Graph. When an incomplete response is detected, the `generate` step will run again with:\r\n\r\n- The original prompt\r\n- The Alerts provided as context\r\n- The partially generated response\r\n- Instructions to \"continue where you left off\"\r\n\r\nThe `generate` step in the graph will run until one of the following conditions is met:\r\n\r\n- The incomplete response can be successfully parsed\r\n- The maximum number of generation attempts (default: `10`) is reached\r\n- The maximum number of hallucinations detected (default: `5`) is reached\r\n\r\n#### Output refinement details\r\n\r\nThe new output refinement feature automatically combines related discoveries (that were previously represented as two or more discoveries).\r\n\r\nThe new `refine` step in the graph re-submits the discoveries from the `generate` step with a `refinePrompt` to combine related attack discoveries.\r\n\r\nThe `refine` step is subject to the model's output token limits, just like the `generate` step. That means a response to the refine prompt from the LLM may be cut off \"mid\" sentence. To that end:\r\n\r\n- The refine step will re-run until the (same, shared) `maxGenerationAttempts` and `maxHallucinationFailures` limits as the `generate` step are reached\r\n- The maximum number of attempts (default: `10`) is _shared_ with the `generate` step. For example, if it took `7` tries (`generationAttempts`) to complete the `generate` step, the refine `step` will only run up to `3` times.\r\n\r\nThe `refine` step will return _unrefined_ results from the `generate` step when:\r\n\r\n- The `generate` step uses all `10` generation attempts. When this happens, the `refine` step will be skipped, and the unrefined output of the `generate` step will be returned to the user\r\n- If the `refine` step uses all remaining attempts, but fails to produce a refined response, due to output token limitations, or hallucinations in the refined response\r\n\r\n#### Hallucination detection details\r\n\r\nBefore this PR, Attack discovery directly used lower level LangChain APIs to parse responses from the LLM. After this PR, Attack discovery uses LangGraph.\r\n\r\nIn the previous implementation, when Attack discovery received an incomplete response because the output token limits of a model were hit, the LangChain APIs automatically re-submitted the incomplete response in an attempt to \"repair\" it. However, the re-submitted results didn't include all of the original context (i.e. alerts that generated them). The repair process often resulted in hallucinated results being presented to users, especially with some models i.e. `Claude 3.5 Haiku`.\r\n\r\nIn this PR, the `generate` and `refine` steps detect (some) hallucinations. When hallucinations are detected:\r\n\r\n- The current accumulated `generations` or `refinements` are (respectively) discarded, effectively restarting the `generate` or `refine` process\r\n- The `generate` and `refine` steps will be retried until the maximum generation attempts (default: `10`) or hallucinations detected (default: `5`) limits are reached\r\n\r\nHitting the hallucination limit during the `generate` step will result in an error being displayed to the user.\r\n\r\nHitting the hallucination limit during the `refine` step will result in the unrefined discoveries being displayed to the user.\r\n\r\n#### Replay alerts in evaluations details\r\n\r\nAlerts replay makes it possible to re-run evaluations, even when your local deployment has zero alerts.\r\n\r\nThis feature eliminates the chore of populating your local instance with specific alerts for each example.\r\n\r\nEvery example in a dataset may (optionally) specify a different set of alerts.\r\n\r\nAlert replay skips the `retrieve_anonymized_alerts` step in the graph, because it uses the `anonymizedAlerts` and `replacements` provided as `Input` in a dataset example.\r\n\r\nThe following instructions document the process of creating a new LangSmith dataset example that uses the Alerts replay feature:\r\n\r\n1) In Kibana, navigate to Security > Attack discovery\r\n\r\n2) Click `Generate` to generate Attack discoveries\r\n\r\n3) In LangSmith, navigate to Projects > _Your project_\r\n\r\n4) In the `Runs` tab of the LangSmith project, click on the latest `Attack discovery` entry to open the trace\r\n\r\n5) **IMPORTANT**: In the trace, select the **LAST** `ChannelWriteChannelWrite<attackDiscoveries,attackDisc...` entry. The last entry will appear inside the **LAST** `refine` step in the trace, as illustrated by the screenshot below:\r\n\r\n\r\n\r\n6) With the last `ChannelWriteChannelWrite<attackDiscoveries,attackDisc...` entry selected, click `Add to` > `Add to Dataset`\r\n\r\n7) Copy-paste the `Input` to the `Output`, because evaluation Experiments always compare the current run with the `Output` in an example.\r\n\r\n- This step is _always_ required to create a dataset.\r\n- If you don't want to use the Alert replay feature, replace `Input` with an empty object:\r\n\r\n```json\r\n{}\r\n```\r\n\r\n8) Choose an existing dataset, or create a new one\r\n\r\n9) Click the `Submit` button to add the example to the dataset.\r\n\r\nAfter completing the steps above, the dataset is ready to be run in evaluations.\r\n\r\n#### Override graph state details\r\n\r\nWhen a dataset is run in an evaluation (to create Experiments):\r\n\r\n- The (optional) `anonymizedAlerts` and `replacements` provided as `Input` in the example will be replayed, bypassing the `retrieve_anonymized_alerts` step in the graph\r\n- The rest of the properties in `Input` will not be used as inputs to the graph\r\n- In contrast, an empty object `{}` in `Input` means the latest and riskiest alerts in the last 24 hours in the local environment will be queried\r\n\r\nIn addition to the above, you may add an optional `overrides` key in the `Input` of a dataset example to test changes or edge cases. This is useful for evaluating changes without updating the code directly.\r\n\r\nThe `overrides` set the initial state of the graph before it's run in an evaluation.\r\n\r\nThe example `Input` below overrides the prompts used in the `generate` and `refine` steps:\r\n\r\n```json\r\n{\r\n \"overrides\": {\r\n \"refinePrompt\": \"This overrides the refine prompt\",\r\n \"attackDiscoveryPrompt\": \"This overrides the attack discovery prompt\"\r\n }\r\n}\r\n```\r\n\r\nTo use the `overrides` feature in evaluations to set the initial state of the graph:\r\n\r\n1) Create a dataset example, as documented in the _Replay alerts in evaluations details_ section above\r\n\r\n2) In LangSmith, navigate to Datasets & Testing > _Your Dataset_\r\n\r\n3) In the dataset, click the Examples tab\r\n\r\n4) Click an example to open it in the flyout\r\n\r\n5) Click the `Edit` button to edit the example\r\n\r\n6) Add the `overrides` key shown below to the `Input` e.g.:\r\n\r\n```json\r\n{\r\n \"overrides\": {\r\n \"refinePrompt\": \"This overrides the refine prompt\",\r\n \"attackDiscoveryPrompt\": \"This overrides the attack discovery prompt\"\r\n }\r\n}\r\n```\r\n\r\n7) Edit the `overrides` in the example `Input` above to add (or remove) entries that will determine the initial state of the graph.\r\n\r\nAll of the `overides` shown in step 6 are optional. The `refinePrompt` and `attackDiscoveryPrompt` could be removed from the `overrides` example above, and replaced with `maxGenerationAttempts` to test a higher limit.\r\n\r\nAll valid graph state may be specified in `overrides`.","sha":"2c21adb8faafc0016ad7a6591837118f6bdf0907"}},"sourceBranch":"main","suggestedTargetBranches":["8.x"],"targetPullRequestStates":[{"branch":"main","label":"v9.0.0","branchLabelMappingKey":"^v9.0.0$","isSourceBranch":true,"state":"MERGED","url":"https://github.com/elastic/kibana/pull/195669","number":195669,"mergeCommit":{"message":"[Security Solution] [Attack discovery] Output chunking / refinement, LangGraph migration, and evaluation improvements (#195669)\n\n## [Security Solution] [Attack discovery] Output chunking / refinement, LangGraph migration, and evaluation improvements\r\n\r\n### Summary\r\n\r\nThis PR improves the Attack discovery user and developer experience with output chunking / refinement, migration to LangGraph, and improvements to evaluations.\r\n\r\nThe improvements were realized by transitioning from directly using lower-level LangChain apis to LangGraph in this PR, and a deeper integration with the evaluation features of LangSmith.\r\n\r\n#### Output chunking\r\n\r\n_Output chunking_ increases the maximum and default number of alerts sent as context, working around the output token limitations of popular large language models (LLMs):\r\n\r\n| | Old | New |\r\n|----------------|-------|-------|\r\n| max alerts | `100` | `500` |\r\n| default alerts | `20` | `200` |\r\n\r\nSee _Output chunking details_ below for more information.\r\n\r\n#### Settings\r\n\r\nA new settings modal makes it possible to configure the number of alerts sent as context directly from the Attack discovery page:\r\n\r\n\r\n\r\n- Previously, users configured this value for Attack discovery via the security assistant Knowledge base settings, as documented [here](https://www.elastic.co/guide/en/security/8.15/attack-discovery.html#attack-discovery-generate-discoveries)\r\n- The new settings modal uses local storage (instead of the previously-shared assistant Knowledge base setting, which is stored in Elasticsearch)\r\n\r\n#### Output refinement\r\n\r\n_Output refinement_ automatically combines related discoveries (that were previously represented as two or more discoveries):\r\n\r\n \r\n\r\n- The `refine` step in the graph diagram above may (for example), combine three discoveries from the `generate` step into two discoveries when they are related\r\n\r\n### Hallucination detection\r\n\r\nNew _hallucination detection_ displays an error in lieu of showing hallucinated output:\r\n\r\n\r\n\r\n- A new tour step was added to the Attack discovery page to share the improvements:\r\n\r\n\r\n\r\n### Summary of improvements for developers\r\n\r\nThe following features improve the developer experience when running evaluations for Attack discovery:\r\n\r\n#### Replay alerts in evaluations\r\n\r\nThis evaluation feature eliminates the need to populate a local environment with alerts to (re)run evaluations:\r\n\r\n \r\n\r\nAlert replay skips the `retrieve_anonymized_alerts` step in the graph, because it uses the `anonymizedAlerts` and `replacements` provided as `Input` in a dataset example. See _Replay alerts in evaluations details_ below for more information.\r\n\r\n#### Override graph state\r\n\r\nOverride graph state via datatset examples to test prompt improvements and edge cases via evaluations:\r\n\r\n \r\n\r\nTo use this feature, add an `overrides` key to the `Input` of a dataset example. See _Override graph state details_ below for more information.\r\n\r\n#### New custom evaluator\r\n\r\nPrior to this PR, an evaluator had to be manually added to each dataset in LangSmith to use an LLM as the judge for correctness.\r\n\r\nThis PR introduces a custom, programmatic evaluator that handles anonymization automatically, and eliminates the need to manually create evaluators in LangSmith. To use it, simply run evaluations from the `Evaluation` tab in settings.\r\n\r\n#### New evaluation settings\r\n\r\nThis PR introduces new settings in the `Evaluation` tab:\r\n\r\n\r\n\r\nNew evaluation settings:\r\n\r\n- `Evaluator model (optional)` - Judge the quality of predictions using a single model. (Default: use the same model as the connector)\r\n\r\nThis new setting is useful when you want to use the same model, e.g. `GPT-4o` to judge the quality of all the models evaluated in an experiment.\r\n\r\n- `Default max alerts` - The default maximum number of alerts to send as context, which may be overridden by the example input\r\n\r\nThis new setting is useful when using the alerts in the local environment to run evaluations. Examples that use the Alerts replay feature will ignore this value, because the alerts in the example `Input` will be used instead.\r\n\r\n#### Directory structure refactoring\r\n\r\n- The server-side directory structure was refactored to consolidate the location of Attack discovery related files\r\n\r\n### Details\r\n\r\nThis section describes some of the improvements above in detail.\r\n\r\n#### Output chunking details\r\n\r\nThe new output chunking feature increases the maximum and default number of alerts that may be sent as context. It achieves this improvement by working around output token limitations.\r\n\r\nLLMs have different limits for the number of tokens accepted as _input_ for requests, and the number of tokens available for _output_ when generating responses.\r\n\r\nToday, the output token limits of most popular models are significantly smaller than the input token limits.\r\n\r\nFor example, at the time of this writing, the Gemini 1.5 Pro model's limits are ([source](https://ai.google.dev/gemini-api/docs/models/gemini)):\r\n\r\n- Input token limit: `2,097,152`\r\n- Output token limit: `8,192`\r\n\r\nAs a result of this relatively smaller output token limit, previous versions of Attack discovery would simply fail when an LLM ran out of output tokens when generating a response. This often happened \"mid sentence\", and resulted in errors or hallucinations being displayed to users.\r\n\r\nThe new output chunking feature detects incomplete responses from the LLM in the `generate` step of the Graph. When an incomplete response is detected, the `generate` step will run again with:\r\n\r\n- The original prompt\r\n- The Alerts provided as context\r\n- The partially generated response\r\n- Instructions to \"continue where you left off\"\r\n\r\nThe `generate` step in the graph will run until one of the following conditions is met:\r\n\r\n- The incomplete response can be successfully parsed\r\n- The maximum number of generation attempts (default: `10`) is reached\r\n- The maximum number of hallucinations detected (default: `5`) is reached\r\n\r\n#### Output refinement details\r\n\r\nThe new output refinement feature automatically combines related discoveries (that were previously represented as two or more discoveries).\r\n\r\nThe new `refine` step in the graph re-submits the discoveries from the `generate` step with a `refinePrompt` to combine related attack discoveries.\r\n\r\nThe `refine` step is subject to the model's output token limits, just like the `generate` step. That means a response to the refine prompt from the LLM may be cut off \"mid\" sentence. To that end:\r\n\r\n- The refine step will re-run until the (same, shared) `maxGenerationAttempts` and `maxHallucinationFailures` limits as the `generate` step are reached\r\n- The maximum number of attempts (default: `10`) is _shared_ with the `generate` step. For example, if it took `7` tries (`generationAttempts`) to complete the `generate` step, the refine `step` will only run up to `3` times.\r\n\r\nThe `refine` step will return _unrefined_ results from the `generate` step when:\r\n\r\n- The `generate` step uses all `10` generation attempts. When this happens, the `refine` step will be skipped, and the unrefined output of the `generate` step will be returned to the user\r\n- If the `refine` step uses all remaining attempts, but fails to produce a refined response, due to output token limitations, or hallucinations in the refined response\r\n\r\n#### Hallucination detection details\r\n\r\nBefore this PR, Attack discovery directly used lower level LangChain APIs to parse responses from the LLM. After this PR, Attack discovery uses LangGraph.\r\n\r\nIn the previous implementation, when Attack discovery received an incomplete response because the output token limits of a model were hit, the LangChain APIs automatically re-submitted the incomplete response in an attempt to \"repair\" it. However, the re-submitted results didn't include all of the original context (i.e. alerts that generated them). The repair process often resulted in hallucinated results being presented to users, especially with some models i.e. `Claude 3.5 Haiku`.\r\n\r\nIn this PR, the `generate` and `refine` steps detect (some) hallucinations. When hallucinations are detected:\r\n\r\n- The current accumulated `generations` or `refinements` are (respectively) discarded, effectively restarting the `generate` or `refine` process\r\n- The `generate` and `refine` steps will be retried until the maximum generation attempts (default: `10`) or hallucinations detected (default: `5`) limits are reached\r\n\r\nHitting the hallucination limit during the `generate` step will result in an error being displayed to the user.\r\n\r\nHitting the hallucination limit during the `refine` step will result in the unrefined discoveries being displayed to the user.\r\n\r\n#### Replay alerts in evaluations details\r\n\r\nAlerts replay makes it possible to re-run evaluations, even when your local deployment has zero alerts.\r\n\r\nThis feature eliminates the chore of populating your local instance with specific alerts for each example.\r\n\r\nEvery example in a dataset may (optionally) specify a different set of alerts.\r\n\r\nAlert replay skips the `retrieve_anonymized_alerts` step in the graph, because it uses the `anonymizedAlerts` and `replacements` provided as `Input` in a dataset example.\r\n\r\nThe following instructions document the process of creating a new LangSmith dataset example that uses the Alerts replay feature:\r\n\r\n1) In Kibana, navigate to Security > Attack discovery\r\n\r\n2) Click `Generate` to generate Attack discoveries\r\n\r\n3) In LangSmith, navigate to Projects > _Your project_\r\n\r\n4) In the `Runs` tab of the LangSmith project, click on the latest `Attack discovery` entry to open the trace\r\n\r\n5) **IMPORTANT**: In the trace, select the **LAST** `ChannelWriteChannelWrite<attackDiscoveries,attackDisc...` entry. The last entry will appear inside the **LAST** `refine` step in the trace, as illustrated by the screenshot below:\r\n\r\n\r\n\r\n6) With the last `ChannelWriteChannelWrite<attackDiscoveries,attackDisc...` entry selected, click `Add to` > `Add to Dataset`\r\n\r\n7) Copy-paste the `Input` to the `Output`, because evaluation Experiments always compare the current run with the `Output` in an example.\r\n\r\n- This step is _always_ required to create a dataset.\r\n- If you don't want to use the Alert replay feature, replace `Input` with an empty object:\r\n\r\n```json\r\n{}\r\n```\r\n\r\n8) Choose an existing dataset, or create a new one\r\n\r\n9) Click the `Submit` button to add the example to the dataset.\r\n\r\nAfter completing the steps above, the dataset is ready to be run in evaluations.\r\n\r\n#### Override graph state details\r\n\r\nWhen a dataset is run in an evaluation (to create Experiments):\r\n\r\n- The (optional) `anonymizedAlerts` and `replacements` provided as `Input` in the example will be replayed, bypassing the `retrieve_anonymized_alerts` step in the graph\r\n- The rest of the properties in `Input` will not be used as inputs to the graph\r\n- In contrast, an empty object `{}` in `Input` means the latest and riskiest alerts in the last 24 hours in the local environment will be queried\r\n\r\nIn addition to the above, you may add an optional `overrides` key in the `Input` of a dataset example to test changes or edge cases. This is useful for evaluating changes without updating the code directly.\r\n\r\nThe `overrides` set the initial state of the graph before it's run in an evaluation.\r\n\r\nThe example `Input` below overrides the prompts used in the `generate` and `refine` steps:\r\n\r\n```json\r\n{\r\n \"overrides\": {\r\n \"refinePrompt\": \"This overrides the refine prompt\",\r\n \"attackDiscoveryPrompt\": \"This overrides the attack discovery prompt\"\r\n }\r\n}\r\n```\r\n\r\nTo use the `overrides` feature in evaluations to set the initial state of the graph:\r\n\r\n1) Create a dataset example, as documented in the _Replay alerts in evaluations details_ section above\r\n\r\n2) In LangSmith, navigate to Datasets & Testing > _Your Dataset_\r\n\r\n3) In the dataset, click the Examples tab\r\n\r\n4) Click an example to open it in the flyout\r\n\r\n5) Click the `Edit` button to edit the example\r\n\r\n6) Add the `overrides` key shown below to the `Input` e.g.:\r\n\r\n```json\r\n{\r\n \"overrides\": {\r\n \"refinePrompt\": \"This overrides the refine prompt\",\r\n \"attackDiscoveryPrompt\": \"This overrides the attack discovery prompt\"\r\n }\r\n}\r\n```\r\n\r\n7) Edit the `overrides` in the example `Input` above to add (or remove) entries that will determine the initial state of the graph.\r\n\r\nAll of the `overides` shown in step 6 are optional. The `refinePrompt` and `attackDiscoveryPrompt` could be removed from the `overrides` example above, and replaced with `maxGenerationAttempts` to test a higher limit.\r\n\r\nAll valid graph state may be specified in `overrides`.","sha":"2c21adb8faafc0016ad7a6591837118f6bdf0907"}},{"branch":"8.x","label":"v8.16.0","branchLabelMappingKey":"^v8.16.0$","isSourceBranch":false,"state":"NOT_CREATED"}]}] BACKPORT--> Co-authored-by: Andrew Macri <[email protected]>
- Loading branch information
1 parent
760021b
commit e3996ca