Logging libraries for ECS #281
Comments
|
+1. Somewhat related, I think we should also standardise on some sort of Elastic or ECS protocol, which can be as simple as JSON over TCP/UDP, with the twist that the JSON respects ECS. This means we could have a Filebeat/Logstash input for this protocol, and then any 3rd parties that want to integrate with our stack can implement this. |
|
@tsg I like the idea, should we also open a separate issue for it to not mix discussions? |
|
I see some merit in looking into this. I'm curious what form this would take concretely, in the usage of such a library. When doing structured logging, there's usually still a free form message (key How did you see the featureset offered by these logging libraries? Especially wrt the ad hoc key naming. If we decide to implement this, I call dibs on implementing the Ruby library The one thing we need to steer away from is actually shipping the logs. An application should never have to manage (or suffer from) problems in the logging pipeline. It shouldn't do the queueing, the retries, etc. Hopefully we're just talking about logging libraries that format a text logfile or a syslog payload. |
|
Here is an example logging library for go by @urso https://github.com/urso/ecslog |
|
This library combines a many concepts and separates between ECS and custom user defined fields. It is based on a many experiments with a many other go libraries and some Serilog. The type safe part is based on generated code from the fields.yml files. Users can define their own type safe namespaces and even generate a template.json file if required. Everything is meant to be compatible to ECS. I found the key difference between structured loggers is how the context is handled in all go libraries. I was hoping to do a meta-logger that can operate with other structured loggers, but unfortunately this didn't work out well. Yet I didn't find a library doing exactly as I wanted, so I did roll my own. I will add an Readme with ideas and concepts used in the library the next days, so to have some ground for discussions. For the curious check out this test application using the logger. What also sets this apart from other go based logging libraries is the custom message formatter can capture user meta-data: |
|
++ would be good to write adapters for .NET logging and metrics libraries (Serilog, NLog, AppMetrics...) |
|
I've prototyped implementing a log4j2 Is there any corresponding Filebeat module in the works which could correctly set up the index pattern? Or should the default Filebeat index pattern be good enough? During the implementation, I noticed several log-related fields are either missing or there's no clear mapping to an ECS field:
I have mapped the MDC (Thread-local key/value pairs) to |
|
The default index pattern should be "good enough" as it contains all the ECS fields. For the +1 on your function and line proposal. I wonder what we use for source code at the moment in APM? I guess this is kind of similar? Not sure I fully understood the part around labels, probably need to read up on MDC ;-) |
Not necessarily. It's mostly used to know from which class the log stems from. But it does not have to be the class name. It can also be a user-defined string value.
One problem is that it sort of clashes with the fields Filebeat adds. For example, Filebeat adds
In APM, we refer to source code in the |
|
I used to think that To take Elasticsearch logs as an example, As you outline in your comment from today, nesting source file metadata such as file name and line number doesn't make sense under I like the idea of mapping the MDC to |
|
What speaks for
But the fact that there is already an
There's an open issue for that: #99 The problem is that the APM Java agent can only really leverage the MDC in order to annotate log events with the current |
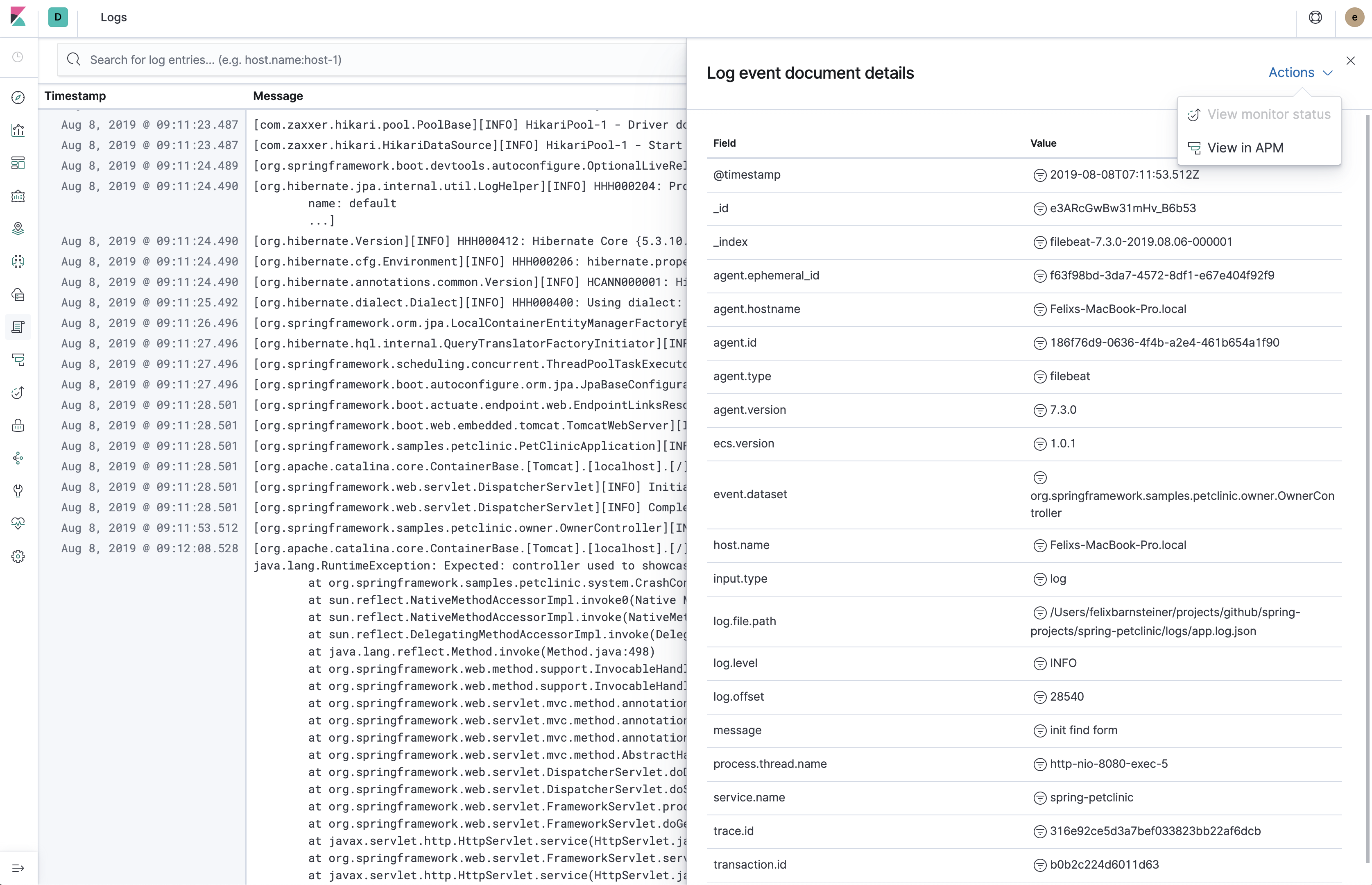
|
As the "log file" and the "origin of the event" can be very different, fully agree it should not be in the same place. The description of the origin of any APM event, be it a log or an error, should be described the same from an ECS perspective I'm thinking. I'm wondering if we need the concept of referring to source code in ECS (source already has an other meaning). Something like |
|
@ruflin Agreed. Check my answer on #521 (comment) |
|
I suggest we open a separate issue / thread for this as this issue is initially about logging libraries? |
|
With https://github.com/elastic/ecs-logging live for a little bit, I think we can close this issue, right? Any unaddressed issue here should be brought up over there, or in the relevant language libs linked in the ecs-logging readme |
Most ECS data is fetched from log files. To make generation of ECS based logs easier, ECS could provide logging libraries or tools on top of the existing logging libraries for the different programming languages. This should make generation of ECS based logs much easier.
This is partially related to #280 as it could be used as a foundation for the logging libraries.
The text was updated successfully, but these errors were encountered: