Stack monitoring with Metricbeat #2415
Comments
This comment has been minimized.
This comment has been minimized.
|
@anyasabo I am going to use Elasticsearch as the example below but stack monitoring applies to other Elstic stack products as well of course.
Hm this might be a misunderstanding, but this issue is about the monitoring feature build into the different stack products. So for Elasticsearch, the monitoring you enable via
If we were to use a shared Metricbeat instance on each k8s node we would need to modify the configuration whenever a new Elasticsearch cluster is created or removed or rescheduled to another node.
I don't think you can expose any Prometheus metrics in ES without third-party tooling. |
As a note here, this is something we have been thinking on for a while and we may start working on it soon, but we don't have a target release for it yet. |
|
One hybrid option that may make sense: one metricbeat deployment per Elasticsearch cluster. That way each cluster can output to a separate monitoring cluster if necessary. We don't need to regularly modify the secrets mounted into metricbeat since it is just monitoring one cluster. For the metricbeat configuration, we can also use autodiscover for that cluster's labels so once it is created we shouldn't need to modify it. It also lets us use less resources than we would using a sidecar and is straightforward to implement. I'm not sure if there's a limit on how many hosts metricbeat can realistically scrape at once. Another downside is that it is still using more resources than if we had one metricbeat deployment for multiple Elasticsearch clusters (the "Central management" option in Peter's original post). This may be significant for users with many ES clusters. Maybe it's worth picking one of the simpler to implement options now, and we can potentially alter it later to allow more density? |
|
Do we have any data on the metricbeat resource consumption? It seems that this would get us more insights about how much we really save on not doing sidecar approach. As for the deployment per cluster, I have mixed feelings, mostly around scalability and spof. Are we sure we can handle any cluster size this way? Would pod running that metricbeat become noisy at some scale? I think if ES is introducing a solution to this problem in 8.0 we should follow that solution. As to the pre-8.0 versions (for which, I assume, we also want to introduce this) I'd be for doing the sidecar as it seems most straightforward and "native". |
|
@pebrc if we end up doing anything else but using the bundled beats in the stack images, can you ping me? I’m not saying it’s no good but I would like to understand the reasons in that case. |
Agreed this feels like a container anti-pattern. The primary argument in favor of it that I read in any of the stack issues was that it is easier for people to deploy, and remains similar to the in-stack monitoring collection configuration. I didn't see any discussion of the cons in the list, so here are some of the reasons why I'd prefer to keep beats and stack containers separate at least for Kubernetes deployments:
Note that these are just arguments against having them in the same container -- we could still have them as separate containers in the same pod (so access to the same namespace, fs, etc). And to reiterate Peter's point, we would only be able to use the in-container method in >=8.0, we would still need some method to support earlier versions. I don't think the ease of deployment is a very strong argument for adopting in-container metricbeats for ECK, since adding a sidecar results in a very similar end state (one metricbeat/ES node, access to the same namespace/fs) and is pretty straightforward for us to implement. |
|
Is there a particular reason for us to rely on Metricbeat for stack monitoring? IIUC, stack monitoring in the current stack version can be done through exporters running in Elasticsearch. Which in future Elasticsearch versions may be replaced by Metricbeat. Isn't it simpler for us to just use that feature instead of deploying Metricbeat in our own way? Users can already configure Elasticsearch the following way: xpack.monitoring.collection.enabled: true
xpack.monitoring.exporters:
id1:
type: http
host: ["https://es-mon1:9200", "https://es-mon2:9200"]
auth:
username: remote_monitoring_user
password: YOUR_PASSWORD
ssl:
truststore.path: /path/to/file
truststore.password: passwordIf we want to simplify this bit of configuration, I guess we could propose something like the following in the Elasticsearch resource: apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: quickstart
spec:
version: 7.5.2
monitoring:
enable: true
exporters:
elasticsearchRef:
namespace: monitoring-ns
name: my-monitoring-cluster
nodeSets:
- name: default
count: 1If Elasticsearch runs Metricbeat internally in future versions I don't think that would impact us in a meaningful way, we would probably just setup a different ES configuration internally instead, but maybe keep the same ES resource. |
|
One additional concern @pebrc smartly raised: beats are forward-compatible with ES within a major but not backwards compatible, e.g. metricbeat 7.3 will work with ES 7.3 - 8.0, but not ES 7.2. It might work, but it is not tested. That said, it should just fail until ES is upgraded, similar to Kibana. This is the same issue described in: #2600 It's not clear to me if we want to enforce metricbeat version == elasticsearch version for now, or if we want to use the least common denominator. For instance, if the source Elasticsearch is 7.3 and the destination Elasticsearch is 7.2, use metricbeat version 7.2. This only applies to elasticsearchRefs where we can parse the version easily. It's not clear to me which we want to do, and even if we want to do the least common denominator, do we do it at first or leave it as an improvement? I also wonder if we want to add a webhook validation for incompatible versions (say src ES 7.2 dest ES 6.8). See the compatibility matrix for more detail. I'd also like to flesh out the spec a little bit more. I think we would like to support both type ElasticsearchSpec struct {
...
// Monitoring contains Elasticsearch references to send stack monitoring metrics to.
Monitoring Monitoring `json:"monitoring,omitempty"`
...
}
type Monitoring struct {
// ServiceAccountName is used to check access from the current resource to a resource (eg. Elasticsearch) in a different namespace.
// Can only be used if ECK is enforcing RBAC on references.
// +optional
ServiceAccountName string `json:"serviceAccountName,omitempty"`
ElasticsearchRefs []commonv1.ObjectSelector `json:"elasticsearchRefs,omitempty"`
Secrets []string `json:"secrets,omitempty"`
}
Each of these will spin up a sidecar with a configuration similar to the example in the first post, with an output to the specified cluster. Users could then override the containers in the podTemplate similar to init containers today. I favor this approach, but would wait to implement the |
We discussed this out of band, but to update it here: the plan is to remove internal collection in 8.x regardless of the status of bundling metricbeat into the ES image, so we chose to use the sidecar since it will work with 6.x, 7.x, and 8.x. If it was not for the future removal it would be tempting to use internal collection due to the ease of configuration. |
Can you clarify the reasoning not to go with autodiscovery first? /cc @roncohen for visibility and guidance. |
|
@bleskes tl;dr: it's not feasible to use autodiscover currently without compromising security and/or ugly workarounds. There's a few ways we might use autodiscover: we could have one central metricbeat that monitors all elasticsearch instances across an entire k8s cluster. This has some challenges: Our clusters have security enabled by default and each cluster has its own CA, so we would need to mount the CAs and credentials into the metricbeat pod(s).
We could also use one Metricbeat instance per Elasticsearch cluster. This would keep us from needing to reconcile cluster-wide secrets. There are two implementation issues:
The hope is that we could at least switch to the second option with the same user interface in the future, but for now Metricbeat seemed the simplest. From @exekias's comment upthread some of this may change in the future, but nothing concrete yet. |
|
A few implementation issues that came up / questions: It would be helpful to allow users to easily modify the sidecar similar to how they can modify the primary container today. This would be a larger refactor though, and is essentially the same as #2306. The pod template builder Secondly, the current association model is designed around 1:1 associations -- each Kibana is associated with only one Elasticsearch instance. This makes it slightly more complicated to implement multiple elasticsearchRefs. We currently store the association info in the association.k8s.elastic.co/es-conf annotation. For example: I wonder if it makes sense to stick with the CRD design proposed here #2415 (comment), but limit the length of |
|
I think you folks covered all the options:
The sidecar approach looks good enough to me, in general the only bit I dislike about it is that you don't have fine grained control over the Metricbeat agent, as it's lifecycle is tied to the Elasticsearch/Kibana node. For instance, operations like pausing/stopping monitoring collection will become challenging. Running a Metricbeat per cluster is also nice, as it solves the above stated problems. I see you are facing some other issues and would love to dig more into them:
I guess the new mode for SSL verification is something we could discuss implementing.
Same here, we already discussed this one and it's something we want to implement. |
|
After some out of band discussion we decided to pause implementing stack monitoring as a sidecar for the time being, and investigate further if it could be modeled as part of the generic beats design: #2417. This means stack monitoring will likely not ship in 1.1, but that is TBD. It started to feel more like modifying Elasticsearch spec to include a stack monitoring section was a little unwieldy and not in line with how people interact with the specs today. Here are two example yamls that attempt to accomplish the same thing: setting up stack monitoring for an elasticsearch resource, while modifying the metricbeat config and metricbeat resources. The biggest difference is the lack of a top level That said, it's not clear to me how necessary modifying the config would be -- the options I can see the most are the metricsets and the period. The rest is basically just the input and output information. So maybe it is not that big of a downside. It's also problematic to modify the Elasticsearch CRD without being very confident that is correct, since it is already v1 and we do not want to make breaking changes unless it's necessary. It seemed prudent to do some more investigation and make sure we cannot wrap stack monitoring into the generic beats CRD. |
|
To sum up where we stand today: This is temporarily blocked while we wait to merge the generic beats CRD (initial PR here). It may be that stack monitoring shares code or wraps a beats crd object. This will likely land in 1.2. We would also like to have beats support |
|
Status update: Adding a stack monitoring CRD is not currently planned. We added a stack monitoring recipe using the generic beats CRD. We have avoided adding "presets" or defaults for different known beat types in favor of using recipes, and the same arguments apply to stack monitoring. This avoids a lot of the configuration merging issues and allows for much simpler testing. The main argument remaining for adding a stack monitoring type is that keeping the monitored resource's CAs in sync across namespaces would be handled by ECK if we added a stack monitoring CRD. As it is you would need to keep them in sync yourself. Inside the same namespace you can just use the same secrets and stay in sync automatically (which is what the recipe does), so that is easy today. This is only mildly persuasive to me and I would want to see more examples of this causing issues before deciding. If the recipe approach proves to be problematic we can revisit adding a stack monitoring CRD (and maybe other beats presets). The other stack monitoring approach we discussed was adding a sidecar to allow for per-resource log shipping. This can be accomplished by using autodiscover scoped to specific labels, which we have a recipe for. This does require host access though, but seems to be good enough for now. If there is a stronger need for a non-privileged solution in the future, we may revisit the sidecar approach. The looser TLS hostname validation feature elastic/beats#8164 has not been picked up yet, but I will check with the beats team if they are planning on it soon or would be open to a PR. Currently the stack monitoring recipe disables TLS to the monitored cluster which is Not Good. At this time I don't think there's a good reason to keep this issue open. Unless there's objections I'll close it in a few days. |
Related to #2051
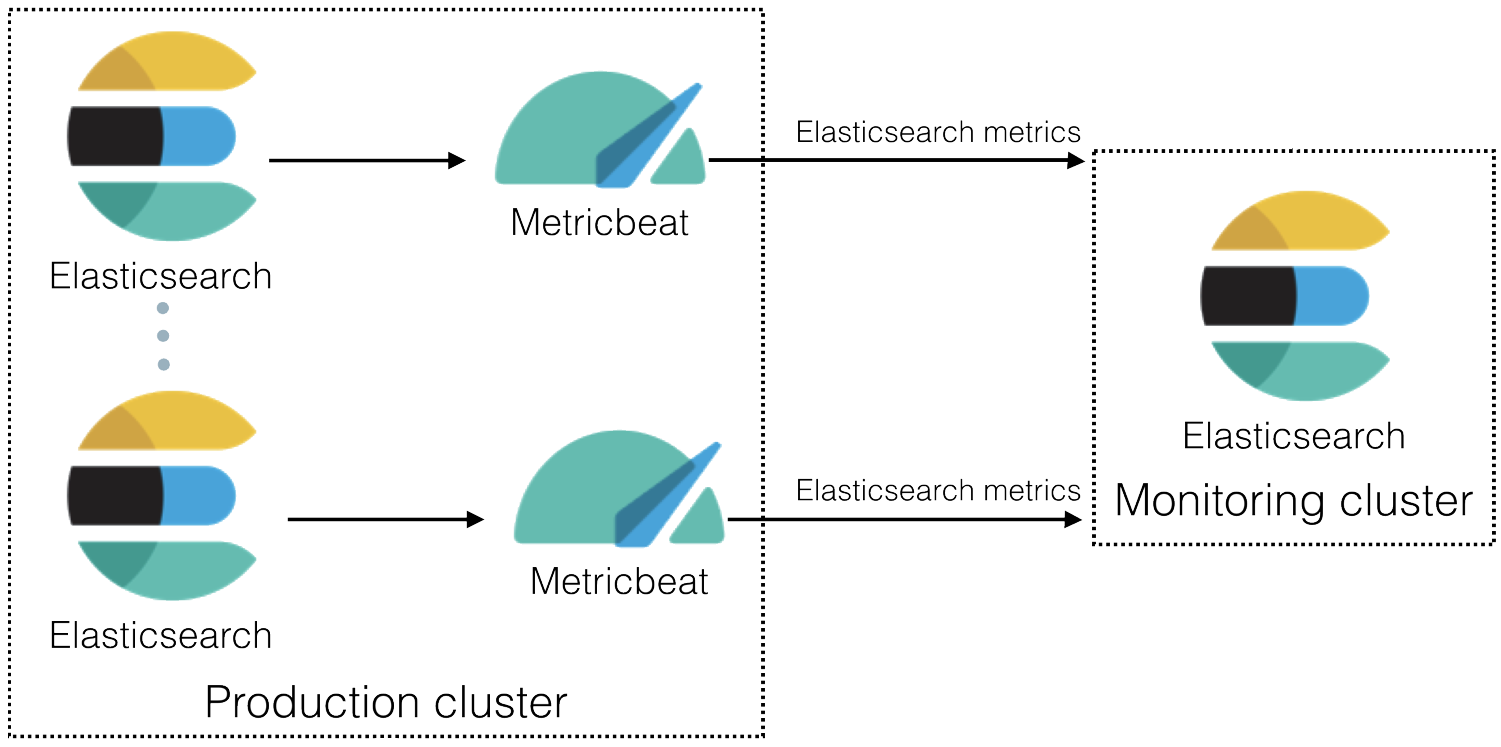
Three possible approaches to collecting monitoring data from Elastic stack containers come to mind
Central management
DaemonSetadvertised in https://www.elastic.co/guide/en/beats/metricbeat/current/running-on-kubernetes.htmlConfigMapto add or remove configuration files if we share aConfigMapbetween e.g. Elasticsearch clustersThe disadvantages seem to outweigh the benefits of saving resources.
In-container Metricbeat process
While this feels like a container anti-pattern at first, the stack seems to be going into that direction starting with version 8.0.0 see elastic/elasticsearch#49399 and elastic/kibana#51224
Unless we have support for this in the official Docker containers we should avoid this route.
Sidecar Metricbeat process
localhostaccess requireslocalhostto be a SAN in the generated certificates (or we have to the turn of cert validation in Metricbeat)The text was updated successfully, but these errors were encountered: