[Wip] Improve Threadpool QUWI throughput #5943
Conversation
5057952 to
aef37e4
Compare
| internal class WorkStealingQueue | ||
| { | ||
| private const int INITIAL_SIZE = 32; | ||
| internal volatile IThreadPoolWorkItem[] m_array = new IThreadPoolWorkItem[INITIAL_SIZE]; | ||
| internal volatile PaddedWorkItem[] m_array = new PaddedWorkItem[INITIAL_SIZE]; |
There was a problem hiding this comment.
Why are you 64-byte padding the items in the queue? The queue is owned by a single thread, and all other threads need to take a lock to access it. The owning thread also needs to take a lock when there are fewer than two items in the queue. The only case where you'd have contention this would help with is if there was a thread stealing concurrently with the owning thread pushing/popping on a list with at least two elements. At that point, they're already some distance apart, though not necessarily a full cache line. Have you shown that this change makes a notable improvement? It does so at the expense of effectively increasing the size of every work item by 56 bytes on 64-bit, since every work item reference to be stored now consumes 64 bytes instead of 8 bytes (plus the size of the work item object itself).
|
@stephentoub as you pointed out don't think padding the items is helpful Still working on it - hot spots are Dequeue and TrySteal |

|
Looking closer the main effect may just be looping the queues (many threads) with mainly empty queues. |
|
@benaadams I think you should start from finding false sharings. In this article shown how to use VS for that. Not sure if it possible on Windows 10,but on Win 7 it was. update: Another good tool Intel VTune |
|
@omariom there is false sharing in stealing; however the current implementation even with the false sharing is pretty hard to improve on. Still iterating, though looking at something quite different than the PR in this current state. |
|
Interesting optimization would be to find all the places (on hot pathes) where volatile reads/writes are unnecessary, replace them with plain reads and use |
There are some areas where this might be possible. Will try it and measure the impact. Although such a change does make me a little uncomfortable 😟 |
eec3a75 to
21c3d55
Compare
|
Bit better, getting a 6% improvement for QueueUserWorkItem throughput for 10M work items (4 core 1 socket) Still investigating. |
|
10% Improvement for regular (13.1s vs 14.7s) |
8632a2d to
7621765
Compare
|
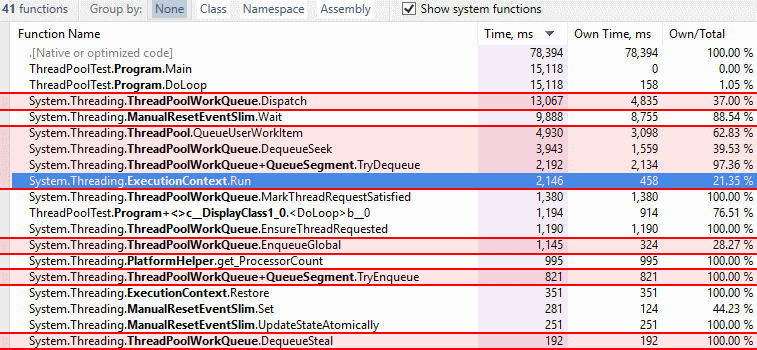
10M threadpool queues and executes. Changed items in red, Threadpool QUWI before Threadpool QUWI after |


|
Test code https://gist.github.com/benaadams/b022934e62a3ac1c4f261be3216b1111 It also allocates 2112 bytes per 255 queued items in discarded Caching a QueueSegment as it gets dropped off the tail and the reusing it as it for a new head avoids these allocations but its also not entirely straightforward with the concurrency flows; so not perusing that at this stage. I believe the changes in this PR should not alter any of the concurrency behaviour. |
|
@dotnet-bot test Linux ARM Emulator Cross Debug Build |
|
@dotnet-bot test Linux ARM Emulator Cross Release Build |
|
@dotnet-bot test this please |
|
Added QueueSegment reuse as commit, needs tests rerunning |
Skip EC.Restore when not changing from defaults Early bail from GetLocalValue when EC Default Fast-path SetLocalValue adding first value
5f13774 to
87d2fae
Compare
|
@benaadams what remains here to call this PR good to go? |
|
@danmosemsft it needs to be freshened and rebased. I'll open as another PR with new results as there is a lot of noise now in this one. |
11% Improvement for regular queuing (1.6sec over 10M QUWI)
19.4% improvement for high thread count queuing (MinWorkerThreads=500) (7.2sec over 10M QUWI)
Test project: https://gist.github.com/benaadams/b022934e62a3ac1c4f261be3216b1111
10M threadpool queues and executes. Changed items in red,
ExecutionContext.Runhighlighted and list pastExecutionContext.Restorefor relative comparison.Threadpool QUWI before
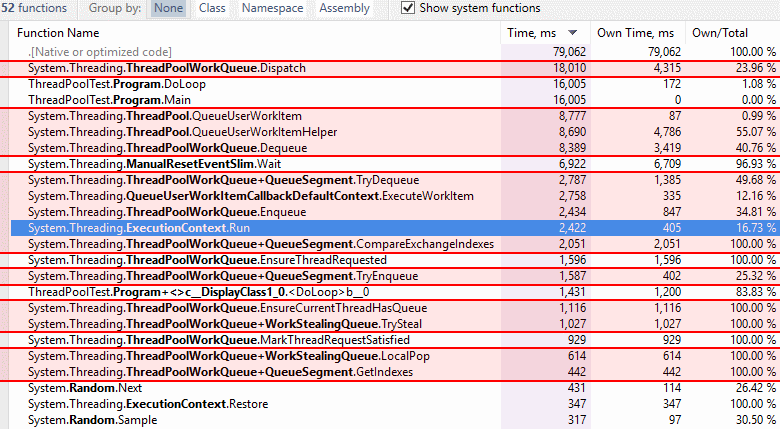
Threadpool QUWI after 2nd Update