#Vincent


###A Python to Vega translator
The folks at Trifacta are making it easy to build visualizations on top of D3 with Vega. Vincent makes it easy to build Vega with Python.
The data capabilities of Python. The visualization capabilities of JavaScript.
Vincent takes Python data structures and translates them into Vega visualization grammar. It allows for quick iteration of visualization designs via getters and setters on grammar elements, and outputs the final visualization to JSON.
Perhaps most importantly, Vincent groks Pandas DataFrames and Series in an intuitive way.
Version 0.2 is a major release for Vincent. It includes many new capabilities, but some regressions- for example, maps are not yet built in as a convenience chart method. Additionally, iPython 1.0 is not yet supported. Both of these are coming soon- please feel free to work on them and submit a pull request.
$pip install vincent
Warning: requires Pandas, which isn't a simple pip install if you don't already have Numpy installed. If you want to go all-pip, I recommend $pip install numpy then $pip install pandas. Or just use Anaconda.
Let's start with some varying data, and then show some different ways to visualize them with Vincent.
Starting with a simple bar chart:
import vincent
bar = vincent.Bar(multi_iter1['y1'])
bar.axis_titles(x='Index', y='Value')
bar.to_json('vega.json')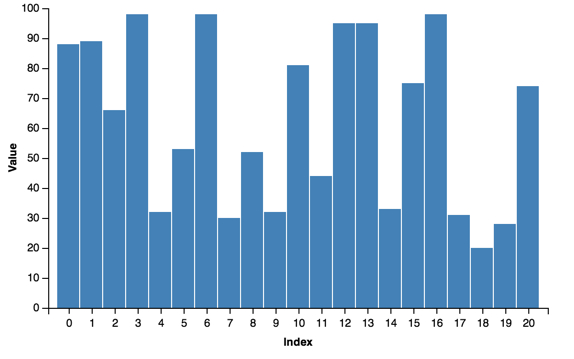
Plotting a number of lines:
line = vincent.Line(multi_iter1, iter_idx='index')
line.axis_titles(x='Index', y='Value')
line.legend(title='Categories')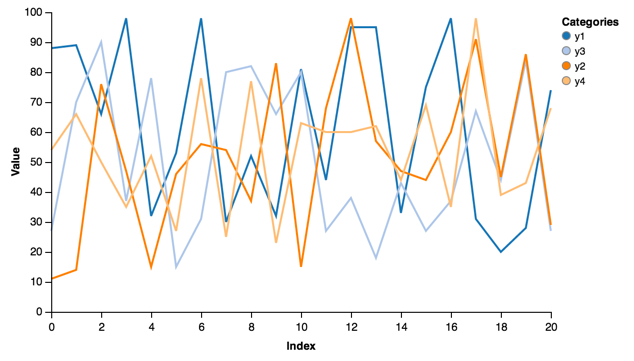
Or a real use case, plotting stock data:
line = vincent.Line(price[['GOOG', 'AAPL']])
line.axis_titles(x='Date', y='Price')
line.legend(title='GOOG vs AAPL')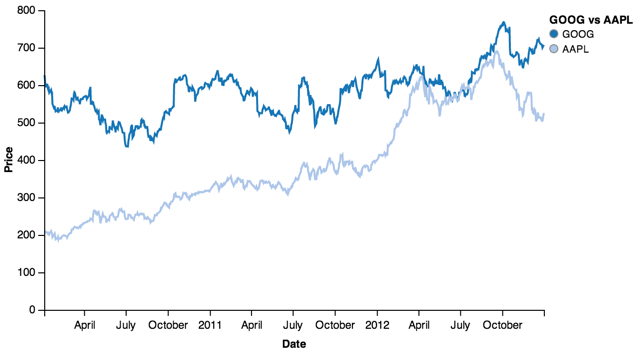
Color brewer scales are built-in. For example, plotting a scatter plot with the Set3 colors:
scatter = vincent.Scatter(multi_iter2, iter_idx='index')
scatter.axis_titles(x='Index', y='Data Value')
scatter.legend(title='Categories')
scatter.colors(brew='Set3')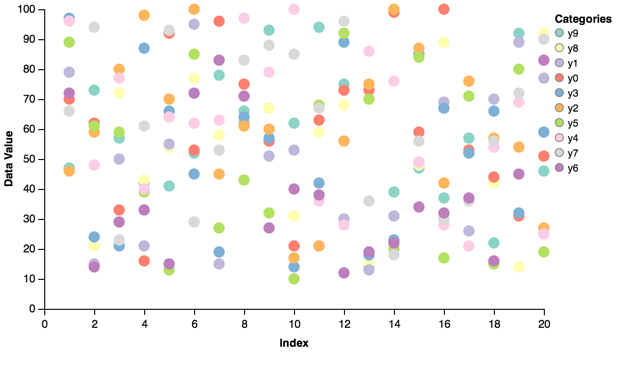
Area charts:
area = vincent.Area(list_data)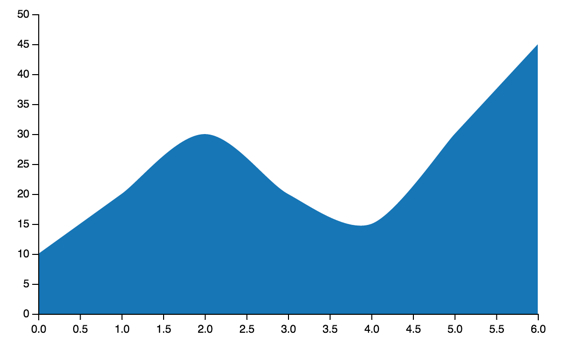
Stacked Area Charts from a DataFrame:
stacked = vincent.StackedArea(df_1)
stacked.axis_titles(x='Index', y='Value')
stacked.legend(title='Categories')
stacked.colors(brew='Spectral')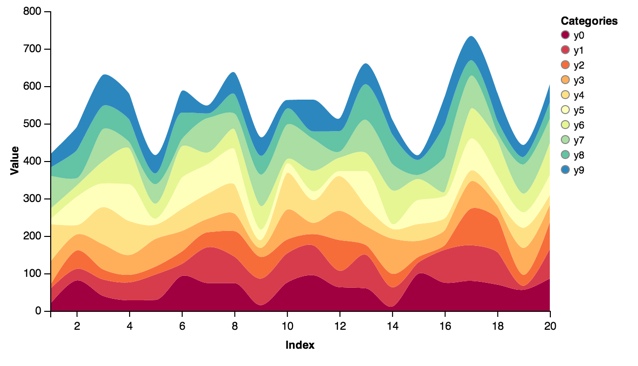
stacked = vincent.StackedArea(price)
stacked.axis_titles(x='Date', y='Price')
stacked.legend(title='Tech Stocks')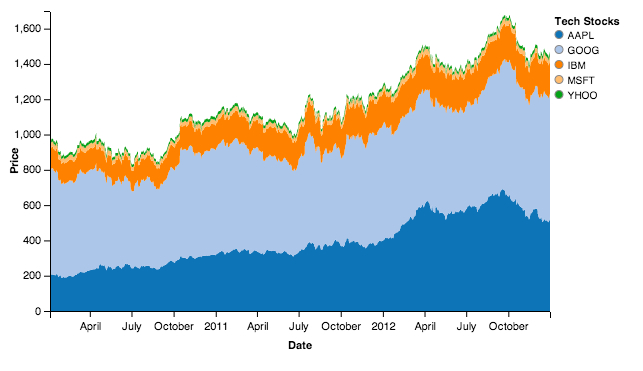
Stacked Bar Charts from a DataFrame:
stack = vincent.StackedBar(df_2)
stack.legend(title='Categories')
stack.scales['x'].padding = 0.1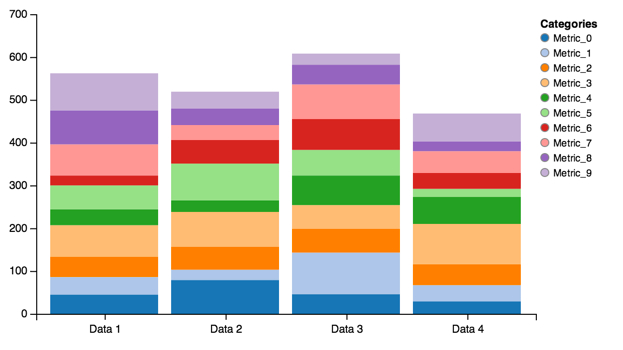
stack = vincent.StackedBar(df_farm.T)
stack.axis_titles(x='Total Produce', y='Farms')
stack.legend(title='Produce Types')
stack.colors(brew='Pastel1')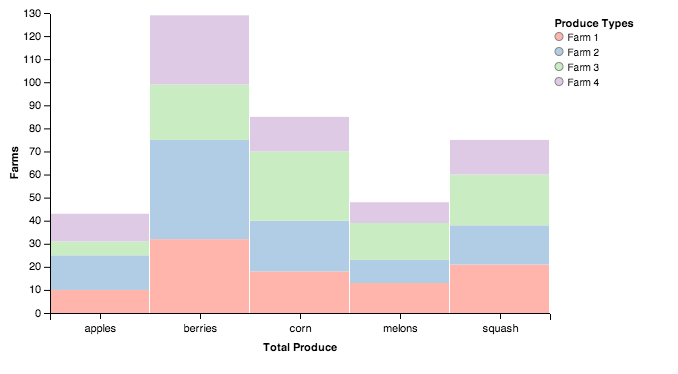
Grouped Bars from a DataFrame:
group = vincent.GroupedBar(df_2)
group.legend(title='Categories')
group.colors(brew='Spectral')
group.width=750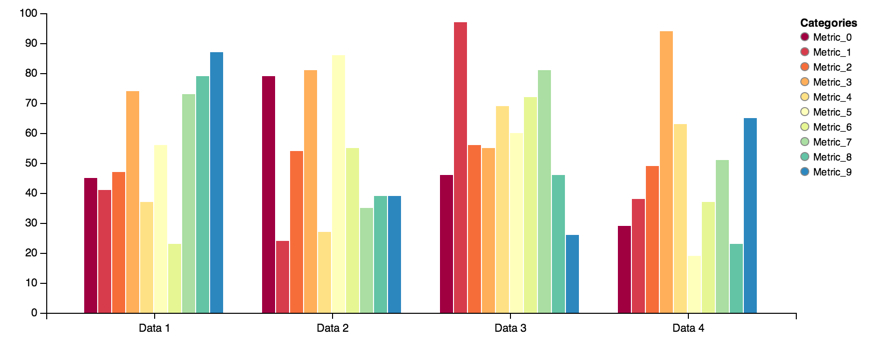
group = vincent.GroupedBar(df_farm)
group.axis_titles(x='Total Produce', y='Farms')
group.legend(title='Produce Types')
group.colors(brew='Set2')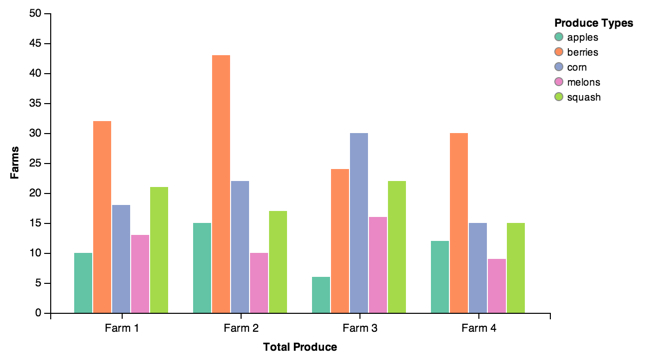
For more examples, including how to build these from scratch, see the examples directory, or the docs.
To see how the charts are being built with Vincent -> Vega grammar, see the charts.py module.
Building the bar chart from scratch will provide a quick example of building with Vincent:
import pandas as pd
from vincent import (Visualization, Scale, DataRef, Data, PropertySet,
Axis, ValueRef, MarkRef, MarkProperties, Mark)
df = pd.DataFrame({'Data 1': [15, 29, 63, 28, 45, 73, 15, 62],
'Data 2': [42, 27, 52, 18, 61, 19, 62, 33]})
#Top level Visualization
vis = Visualization(width=500, height=300)
vis.padding = {'top': 10, 'left': 50, 'bottom': 50, 'right': 100}
#Data. We're going to key Data 2 on Data 1
vis.data.append(Data.from_pandas(df, columns=['Data 2'], key_on='Data 1', name='table'))
#Scales
vis.scales.append(Scale(name='x', type='ordinal', range='width',
domain=DataRef(data='table', field="data.idx")))
vis.scales.append(Scale(name='y', range='height', nice=True,
domain=DataRef(data='table', field="data.val")))
#Axes
vis.axes.extend([Axis(type='x', scale='x'), Axis(type='y', scale='y')])
#Marks
enter_props = PropertySet(x=ValueRef(scale='x', field="data.idx"),
y=ValueRef(scale='y', field="data.val"),
width=ValueRef(scale='x', band=True, offset=-1),
y2=ValueRef(scale='y', value=0))
update_props = PropertySet(fill=ValueRef(value='steelblue'))
mark = Mark(type='rect', from_=MarkRef(data='table'),
properties=MarkProperties(enter=enter_props,
update=update_props))
vis.marks.append(mark)
vis.axis_titles(x='Data 1', y='Data 2')
vis.to_json('vega.json')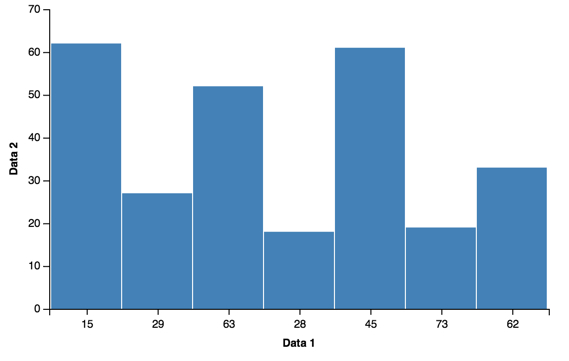
Because the Vega elements are represented by Python classes, it can be difficult to get a good idea of what the Vega grammar looks like:
In [5]: vis.marks[0]
<vincent.marks.Mark at 0x110d630d0>However, at almost any point in the Vincent stack, you can call the grammar() method to output the Vega grammar as Python data structures:
>>>vis.marks[0].grammar()
{u'from': {u'data': u'table'},
u'properties': {u'enter': {u'width': {u'band': True,
u'offset': -1,
u'scale': u'x'},
u'x': {u'field': u'data.idx', u'scale': u'x'},
u'y': {u'field': u'data.val', u'scale': u'y'},
u'y2': {u'scale': u'y', u'value': 0}},
u'update': {u'fill': {u'value': u'steelblue'}}},
u'type': u'rect'}
>>>vis.marks[0].properties.enter.x.grammar()
{u'field': u'data.idx', u'scale': u'x'}or you can simply output it to a string of JSON:
>>>print(vis.marks[0].to_json())
{
"type": "rect",
"from": {
"data": "table"
},
"properties": {
"update": {
"fill": {
"value": "steelblue"
}
},
"enter": {
"y": {
"field": "data.val",
"scale": "y"
},
"width": {
"band": true,
"scale": "x",
"offset": -1
},
"y2": {
"scale": "y",
"value": 0
},
"x": {
"field": "data.idx",
"scale": "x"
}
}
}
}Vincent is built around classes and attributes that map 1:1 to Vega grammar, for easy getting, setting, and deleting of grammar elements:
>>>vis.marks[0].properties.enter.grammar()
{u'width': {u'band': True, u'offset': -1, u'scale': u'x'},
u'x': {u'field': u'data.idx', u'scale': u'x'},
u'y': {u'field': u'data.val', u'scale': u'y'},
u'y2': {u'scale': u'y', u'value': 0}}
>>> del vis.marks[0].properties.enter.width
>>> vis.marks[0].properties.enter.y2.scale = 'y2'
>>> vis.marks[0].properties.enter.grammar()
{u'x': {u'field': u'data.idx', u'scale': u'x'},
u'y': {u'field': u'data.val', u'scale': u'y'},
u'y2': {u'scale': u'y2', u'value': 0}}Huge thanks to all who have contributed to Vincent development:
- Rob Story (wrobstory)
- Dan Miller (dnmiller)
- Peter Lubell-Doughtie (pld)
- Damien Garaud (garaud)
- Abraham Flaxman (aflaxman)
- Mahdi Yusuf (myusuf3)
- Richard Maisano (maisano)
- Julian Berman (Julian)
- Chris Rebert (cvrebert)
- pandas
Testing:
- mock
- nose
PSA: you can use pieces of Vincent without Pandas, but its tricky. Besides, Pandas is awesome- try it!