A lock-free concurrent slab.

![]()

Slabs provide pre-allocated storage for many instances of a single data type. When a large number of values of a single type are required, this can be more efficient than allocating each item individually. Since the allocated items are the same size, memory fragmentation is reduced, and creating and removing new items can be very cheap.
This crate implements a lock-free concurrent slab, indexed by usizes.
Note: This crate is currently experimental. Please feel free to use it in your projects, but bear in mind that there's still plenty of room for optimization, and there may still be some lurking bugs.
First, add this to your Cargo.toml:
sharded-slab = "0.1.0"This crate provides two types, Slab and Pool, which provide slightly
different APIs for using a sharded slab.
Slab implements a slab for storing small types, sharing them between
threads, and accessing them by index. New entries are allocated by inserting
data, moving it in by value. Similarly, entries may be deallocated by taking
from the slab, moving the value out. This API is similar to a Vec<Option<T>>,
but allowing lock-free concurrent insertion and removal.
In contrast, the Pool type provides an object pool style API for
reusing storage. Rather than constructing values and moving them into
the pool, as with Slab, allocating an entry from the pool
takes a closure that's provided with a mutable reference to initialize
the entry in place. When entries are deallocated, they are cleared in
place. Types which own a heap allocation can be cleared by dropping any
data they store, but retaining any previously-allocated capacity. This
means that a Pool may be used to reuse a set of existing heap
allocations, reducing allocator load.
Inserting an item into the slab, returning an index:
use sharded_slab::Slab;
let slab = Slab::new();
let key = slab.insert("hello world").unwrap();
assert_eq!(slab.get(key).unwrap(), "hello world");To share a slab across threads, it may be wrapped in an Arc:
use sharded_slab::Slab;
use std::sync::Arc;
let slab = Arc::new(Slab::new());
let slab2 = slab.clone();
let thread2 = std::thread::spawn(move || {
let key = slab2.insert("hello from thread two").unwrap();
assert_eq!(slab2.get(key).unwrap(), "hello from thread two");
key
});
let key1 = slab.insert("hello from thread one").unwrap();
assert_eq!(slab.get(key1).unwrap(), "hello from thread one");
// Wait for thread 2 to complete.
let key2 = thread2.join().unwrap();
// The item inserted by thread 2 remains in the slab.
assert_eq!(slab.get(key2).unwrap(), "hello from thread two");If items in the slab must be mutated, a Mutex or RwLock may be used for
each item, providing granular locking of items rather than of the slab:
use sharded_slab::Slab;
use std::sync::{Arc, Mutex};
let slab = Arc::new(Slab::new());
let key = slab.insert(Mutex::new(String::from("hello world"))).unwrap();
let slab2 = slab.clone();
let thread2 = std::thread::spawn(move || {
let hello = slab2.get(key).expect("item missing");
let mut hello = hello.lock().expect("mutex poisoned");
*hello = String::from("hello everyone!");
});
thread2.join().unwrap();
let hello = slab.get(key).expect("item missing");
let mut hello = hello.lock().expect("mutex poisoned");
assert_eq!(hello.as_str(), "hello everyone!");-
slab: Carl Lerche'sslabcrate provides a slab implementation with a similar API, implemented by storing all data in a single vector.Unlike
sharded-slab, inserting and removing elements from the slab requires mutable access. This means that if the slab is accessed concurrently by multiple threads, it is necessary for it to be protected by aMutexorRwLock. Items may not be inserted or removed (or accessed, if aMutexis used) concurrently, even when they are unrelated. In many cases, the lock can become a significant bottleneck. On the other hand,sharded-slaballows separate indices in the slab to be accessed, inserted, and removed concurrently without requiring a global lock. Therefore, when the slab is shared across multiple threads, this crate offers significantly better performance thanslab.However, the lock free slab introduces some additional constant-factor overhead. This means that in use-cases where a slab is not shared by multiple threads and locking is not required,
sharded-slabwill likely offer slightly worse performance.In summary:
sharded-slaboffers significantly improved performance in concurrent use-cases, whileslabshould be preferred in single-threaded use-cases.
Most implementations of lock-free data structures in Rust require some
amount of unsafe code, and this crate is not an exception. In order to catch
potential bugs in this unsafe code, we make use of loom, a
permutation-testing tool for concurrent Rust programs. All unsafe blocks
this crate occur in accesses to loom UnsafeCells. This means that when
those accesses occur in this crate's tests, loom will assert that they are
valid under the C11 memory model across multiple permutations of concurrent
executions of those tests.
In order to guard against the ABA problem, this crate makes use of
generational indices. Each slot in the slab tracks a generation counter
which is incremented every time a value is inserted into that slot, and the
indices returned by Slab::insert include the generation of the slot when
the value was inserted, packed into the high-order bits of the index. This
ensures that if a value is inserted, removed, and a new value is inserted
into the same slot in the slab, the key returned by the first call to
insert will not map to the new value.
Since a fixed number of bits are set aside to use for storing the generation counter, the counter will wrap around after being incremented a number of times. To avoid situations where a returned index lives long enough to see the generation counter wrap around to the same value, it is good to be fairly generous when configuring the allocation of index bits.
These graphs were produced by benchmarks of the sharded slab implementation,
using the criterion crate.
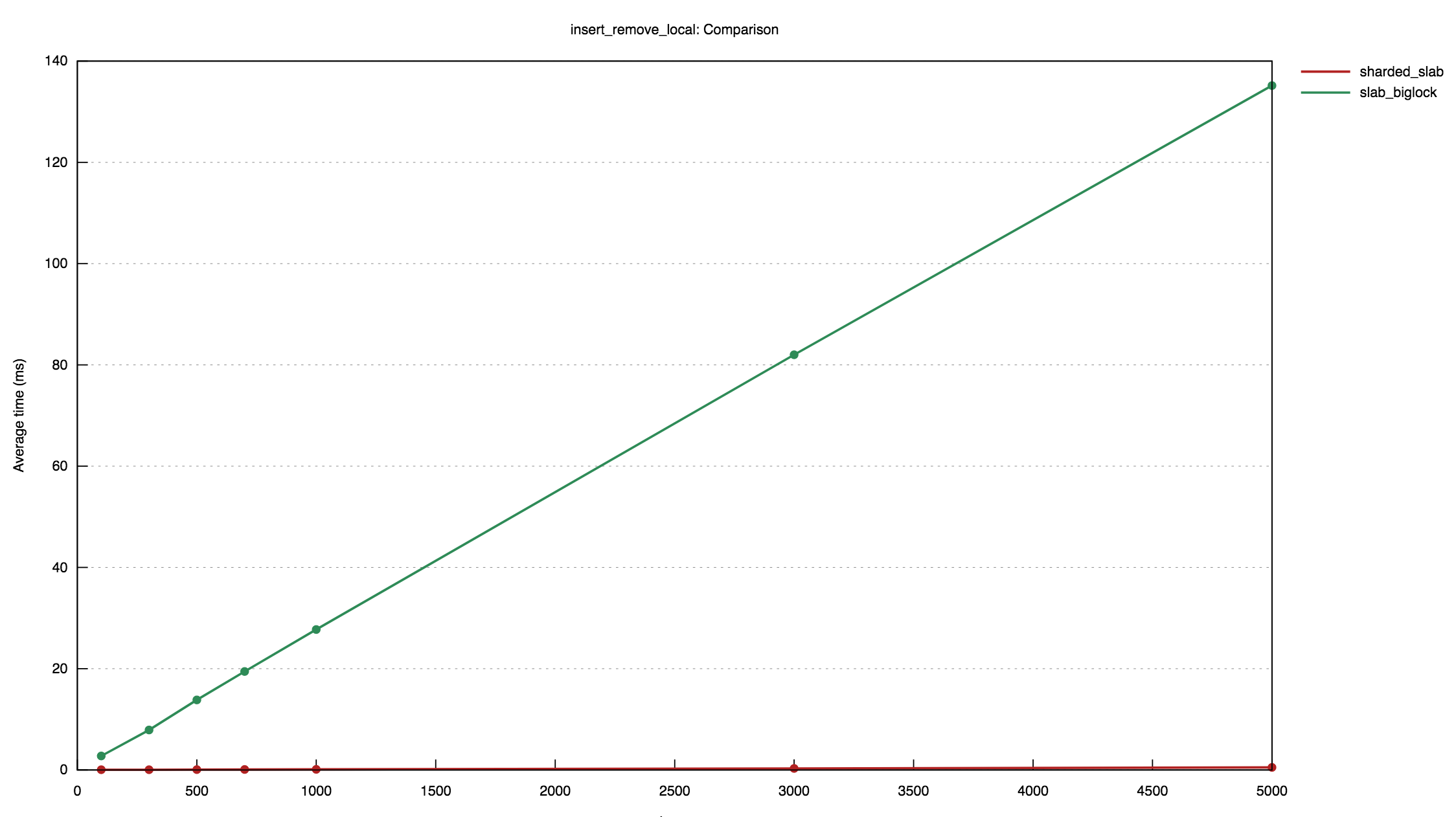
The first shows the results of a benchmark where an increasing number of
items are inserted and then removed into a slab concurrently by five
threads. It compares the performance of the sharded slab implementation
with a RwLock<slab::Slab>:
The second graph shows the results of a benchmark where an increasing
number of items are inserted and then removed by a single thread. It
compares the performance of the sharded slab implementation with an
RwLock<slab::Slab> and a mut slab::Slab.
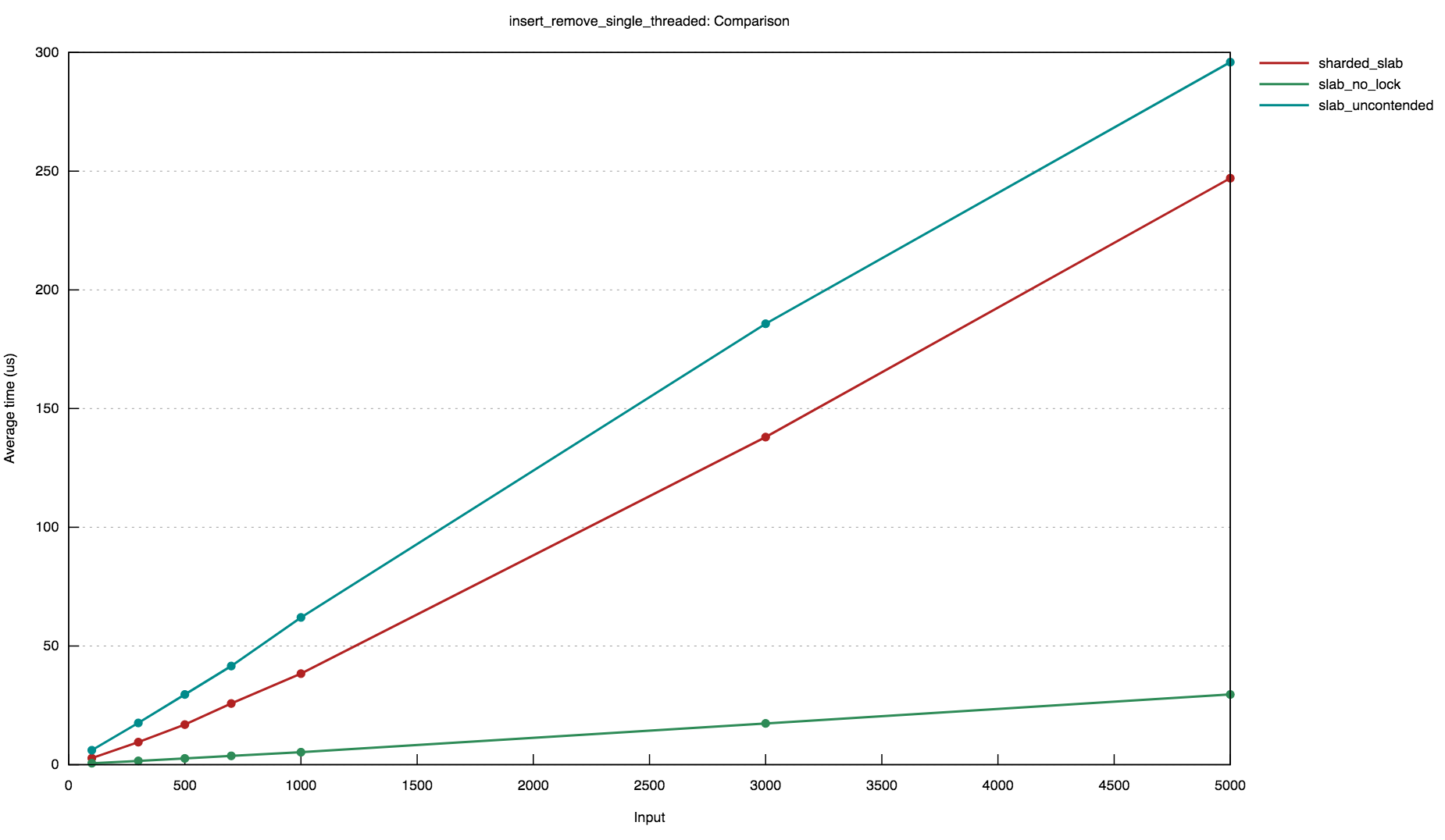
These benchmarks demonstrate that, while the sharded approach introduces a small constant-factor overhead, it offers significantly better performance across concurrent accesses.
This project is licensed under the MIT license.
Unless you explicitly state otherwise, any contribution intentionally submitted for inclusion in this project by you, shall be licensed as MIT, without any additional terms or conditions.