{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
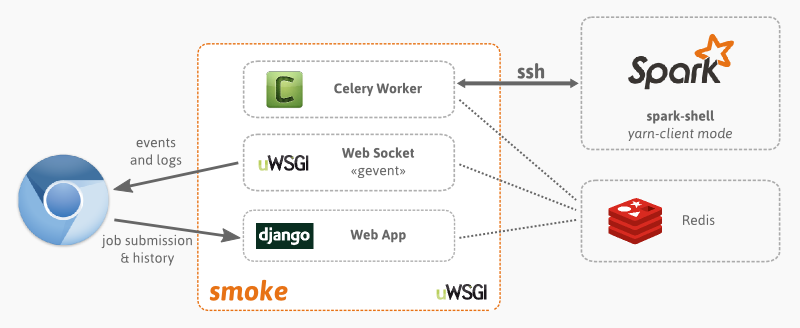
Web interface to execute Scala jobs in Spark. The output generated by spark-shell is sent to the browser while it is being generated using websockets. Requires passwordless connection to the cluster using ssh (for launching the job). Uses spark-shell in yarn client mode.
This is at an early development stage, but it's functional and easy to install (at least in Ubuntu 14.04).
Looking for screenshots? See at the bottom of the page.
$ git clone https://github.com/data-tsunami/smoke
$ cd smoke
$ virtualenv -p python2.7 virtualenv
$ ./virtualenv/bin/pip install -r requirements.txt
$ cp smoke_settings_local_SAMPLE.py smoke_settings_local.py
$ vim smoke_settings_local.py
$ ./run_uwsgi.sh
This script will run Django's syncdb, migrate and collectstatic. Then will start uWSGI and the Celery worker.
Go to http://localhost:8077/ and enjoy!
Smoke is developed and tested with:
- Python 2.7
- Hadoop 2.4.1
- Spark 1.0.2
- Redis
- Ubuntu 14.04, with at least:
- python-dev
- libssl-dev
- openssh-client
- python-virtualenv
Use the environment variable SMOKE_UWSGI_HTTP. For example:
$ env SMOKE_UWSGI_HTTP=127.0.0.1:7777 ./run_uwsgi.sh
You get a lot of this in your console:
[2014-08-22 23:44:02,232: ERROR/MainProcess] consumer: Cannot connect to redis://127.0.0.1:6379/4: Error 111 connecting to 127.0.0.1:6379. Connection refused..
Trying again in 2.00 seconds...
Install and start Redis! On Ubuntu 14.04, you must run:
$ sudo apt-get install -y redis-server
$ sudo service redis-server start
You forgot to install the required packages. Install libssl-dev and reinstall the virtualenv requirements.
If you are brave enough, see instructions at Dockerfile!.
As Smoke is currently in its initial development, security isn't the main goal yet.
- Load Spark results on IPython Notebook
- Kill running jobs
- Better integratoin with Yarn API
- Save & edit scripts
Refactor parser of console outputRefactor actions to reuse code- Document and fix security issues!
- Create a 'check' script, to be used to check configuration after install
- Add Scala utilities to be used in scripts
- Add pagination to job history
- Evaluate paramiko instead of Popen + ssh. See: http://www.paramiko.org/
- Evaluate 'load'. See: https://github.com/apache/spark/blob/master/repl/src/main/scala/org/apache/spark/repl/SparkILoop.scala
- Docker: mount SQlite database in volume
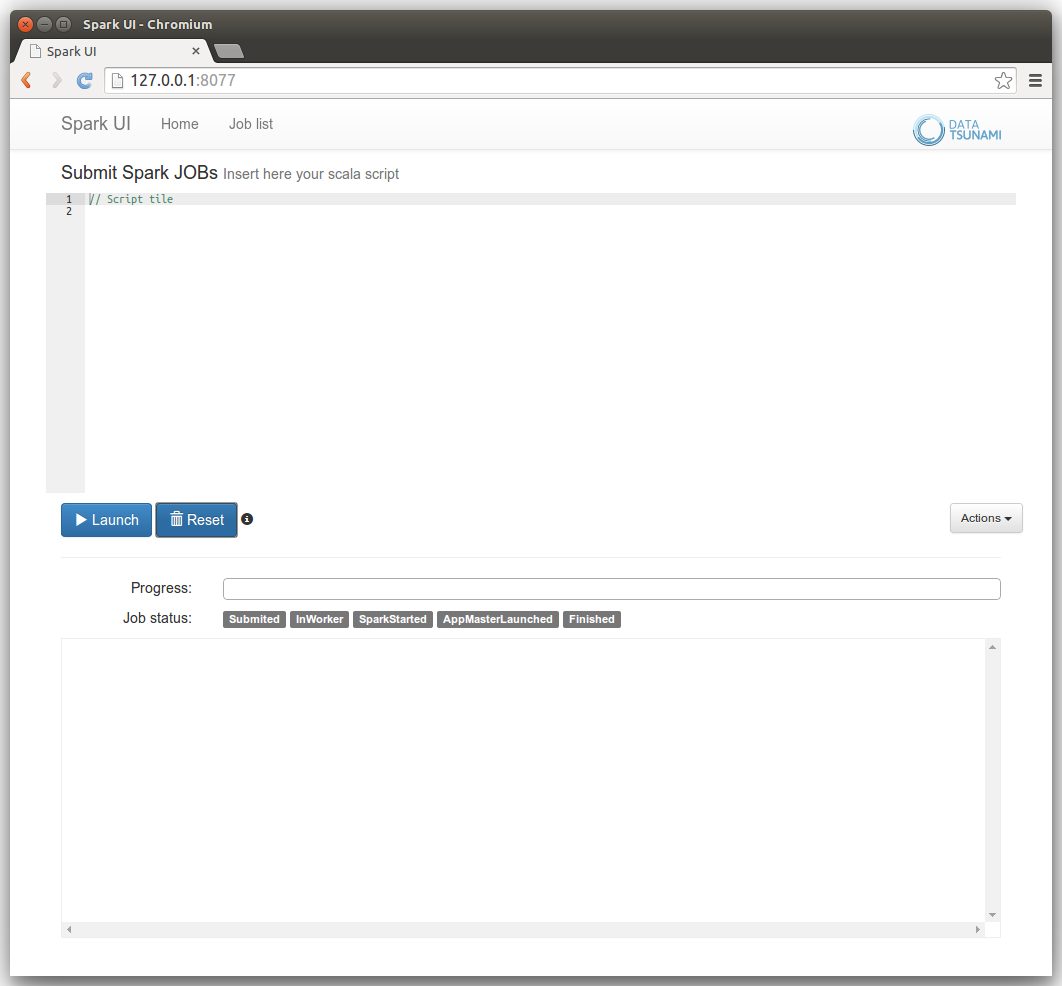




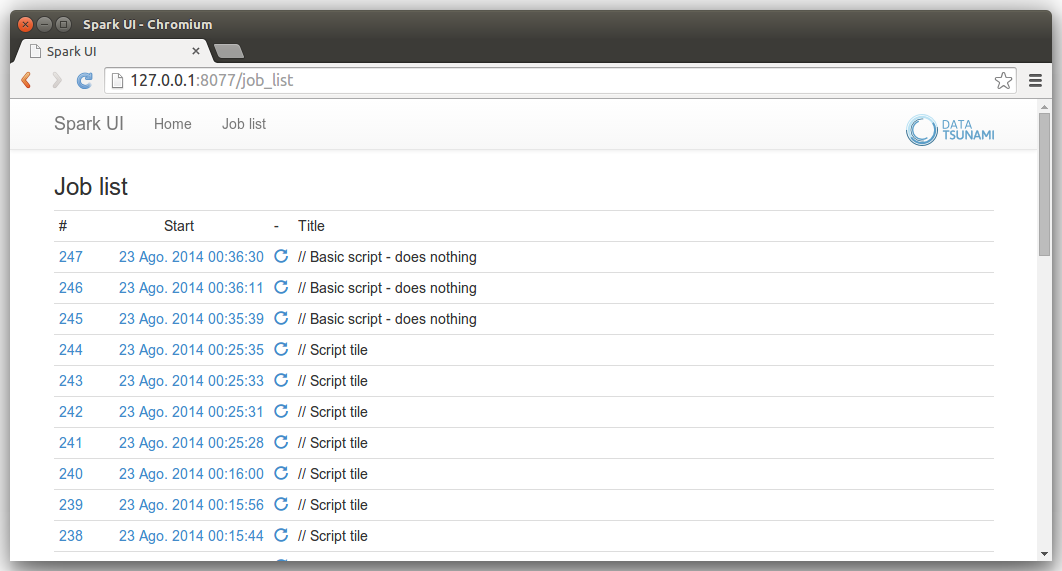
The logs lines are parsed looking for TaskSetManager and Finished TID, and the progress is parsed and reported (in this case, progress was 4 task finished of 10):
14/08/23 12:48:53 INFO scheduler.DAGScheduler: Completed ShuffleMapTask(1, 0)
14/08/23 12:48:53 INFO scheduler.TaskSetManager: Finished TID 0 in 7443 ms on hadoop-hitachi80gb.hadoop.dev.docker.data-tsunami.com (progress: 4/10)

Smoke - Run Spark jobs interactively from the web
Copyright (C) 2014 Horacio Guillermo de Oro <[email protected]>
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.