Introduction
Computer vision combines many fields from computer science to extract (high-level) information from (low-level) image data.
Many computer vision systems use the pipeline pattern. This pipeline can usually be broken down into the following steps:
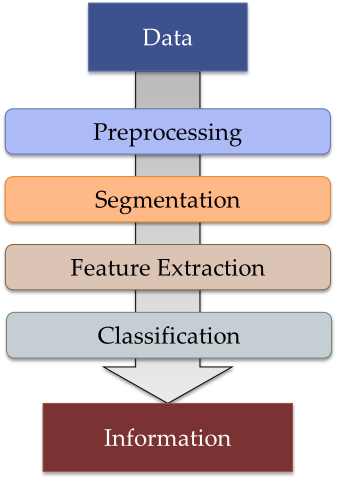
When preprocessing the image you usually apply remove noise, hot pixels, etc. Think of it as preparing the image with GIMP and G'MIC. It's all about making life easier for algorithms that follow.
Formally speaking segmentation is a process where you assign each pixel to a group. When working with text this is usually "text is black" and "paper is white" - this is also called binarization.

When working with complex images usually more than two segments get extracted - this is usually done using algorithms such as region growing and statistical region merging.

In the end it's all about making life easier for algorithms that follow by dropping useless information.
During feature extraction, features such as lines, shapes, motion, etc. get extracted from a single segmented image or a series of segmented images (note: here be dragons!). To name some particularly popular algorithms: the Canny edge detector and Hough transform can be used to extract edges and lines.

During classification, all extracted features get classified to useful information, such as "this is an 'X' with a confidence of 90% or an 'x' with a confidence of 60%". This step usually involves some kind of decision tree and lots of statistics and sometimes machine learning.
Since we're talking about real world images and real world is tricky, it's good to have some kind of confidence involved. Think of it as insurance or trust factor that prevents your application from fatal misapprehension.
Since DocumentVision isn't about soccer robots or augmented reality games, let's get down to business. Documents are usually printed on paper and get scanned under controlled conditions. Information that can be found on paper is ranging from figures and tables to barcodes, form elements and text.
Luminance won't be a big issue, since it's pretty much controlled by the scanning device. Sometimes you have to do background normalization (bad scanner, bad copy). Segmentation depends on what you want to do. If you're interested in simple text, Otsu's algorithm applied to the whole page will usually do the job. When the printing is bad on a shiny form paper it might be a good idea to use an adaptive version of Otsu or remove to form paper (e.g. form paper is red, printed text is black) from the image. After that you can simply throw Tesseract or ZXing at it to get your information.
You should continue with one of the tutorials and start solving your problem.