Support of groups in CF #144
Comments
Further resources:
|
|
This issue is implemented in #145 |
|
Dear Daniel and Charlie Thanks for this proposal. I think it's a sensible way to support groups, and I agree with it, except that I'm not convinced about the lateral search. You don't sound convinced about it either, in saying that it's allowed for backward-compatibility and may be deprecated in future. Why not deprecate it now (meaning that the CF-checker would give a warning)? Why allow it at all? Is there a more specific extra search rule you could provide instead of your general lateral algorithm to deal with the existing datasets you have in mind? I think that at the meeting we talked about how you would flatten a file, if you didn't want groups. Could we include that aspect in the proposal? If it's reversible, that would be neat. I feel that the text could be made simpler and easier to understand, and most of my suggestions below are along those lines. Although I think I get the spirit of your search rules, I have to say I don't properly follow them in detail. The text seems obscure to me - maybe you could say it more plainly, and diagrams would help, I expect.
I hope that helps. Best wishes Jonathan |
|
Dear Jonathan, Thanks for reviewing this. Inline responsesI'm responding to your comments inline and abridging as I determine relevant; if there's anything you're missing, let me know.
I have to agree with you on this, and this is in line with my understanding of the discussion at the meeting in Reading. @czender could you say a few words on this?
@czender has some nice material on this in the original proposal which I omitted for brevity. Would you propose importing this section (possible in edited form) into the pull request? I struggled with not adding too much text to the Conventions themselves, but we could include it as an appendix chapter. I do worry about overloading people new to the game with text.
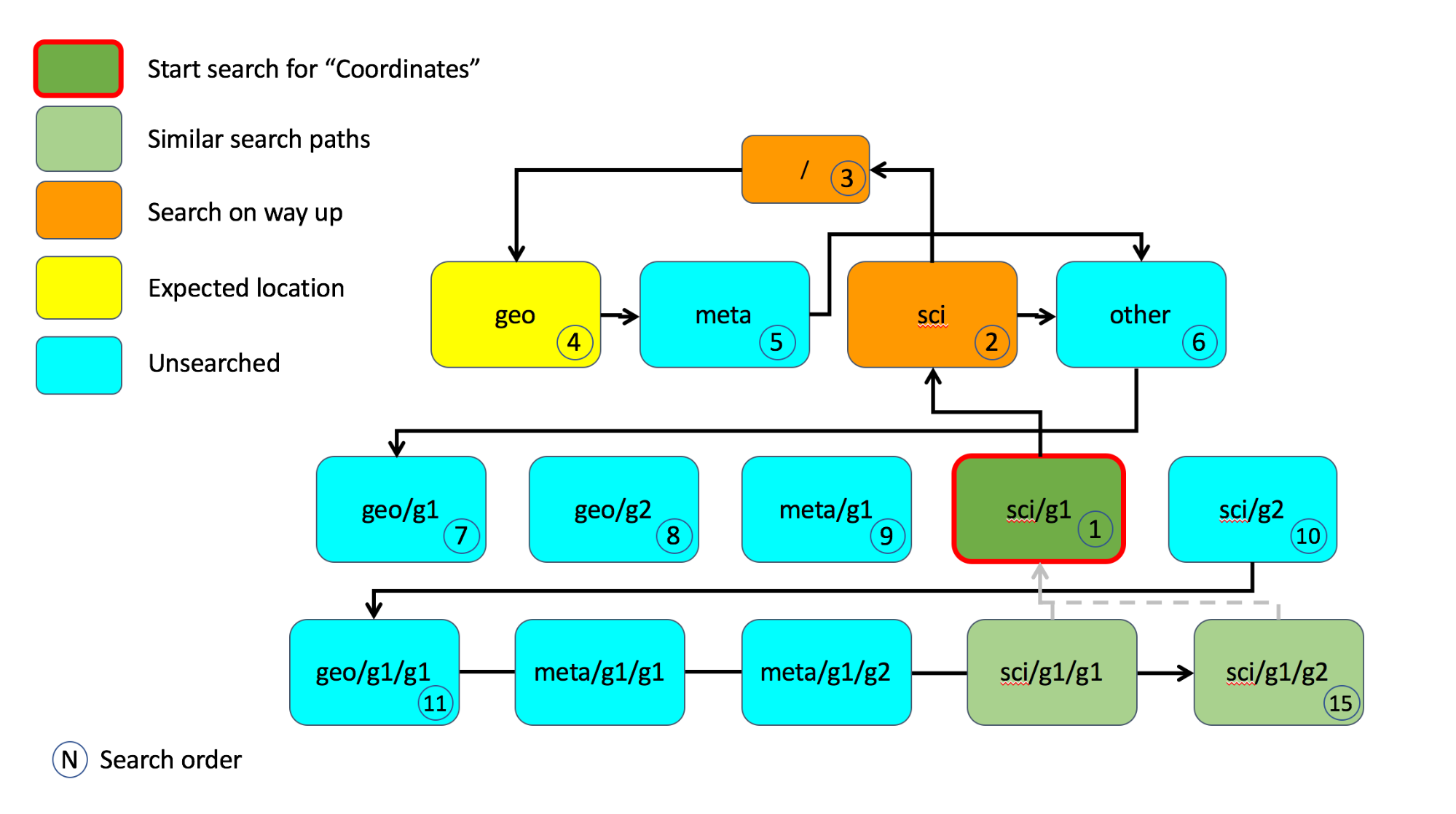
Diagrams are always good. In the original proposal we had:
To my knowledge it would be the only diagram in the whole of the Conventions. As a new contributor I didn't want to snub current practices, but I see no problem with including it, if the community is happy with that.
I don't really agree with this - having multiple glossaries scattered throughout the document only makes the terms easy to find if everybody is reading them in electronic form, and in that case we could just as well define terms next to their first use. So I prefer to keep all definitions together, as has been done for all the other definitions thus far.
I think it would be a good idea to add these to the glossary. @czender, do you have an opinion on "nearest" vs. "most proximal"?
@czender I see no difference here and propose adopting "element". Please correct me if I'm overlooking something.
I understand what you're saying here, but since we say that paths are treated as UNIX paths, I think it would be overredundant to describe how to follow a path according to the UNIX conventions. Do you think it would be valuable to link to the POSIX pathname resolution specification? The same comment applies to your following bullet point, which I have omitted.
You're right, this should be noted at the beginning of the chapter, since it applies to all out of group references. For our reference I note that it's in
Agreed, I think we can describe this more clearly in the next update.
I agree with that too.
I agree that precedence should be clearly stated when group attributes conflict with global attributes. Next stepsWe'll update the PR to address the points as noted above and ping again when that's been done. In addition to the items noted explicitly, I propose placing the following new terms in the glossary:
|
|
In response to Jonathan's question on paths (or full names)
I just wanted to mention that full names are supported (to varying degrees) by the netCDF C and Java libraries and the ncdump and nccopy utilities. Documentation, as far as I've found, is a bit sparse and scattered. In the C library, you can find a group given its full name, and with a group (ncid) you can get its full name. But that doesn't work for variables or dimensions. The Java library provides similar functionality for groups, variables, and dimensions. The ncdump and nccopy utilities support full paths in the |
|
Given that, would that call for search by proximity as the only approach in section 5, Scope? Having all potential approaches complicates interpretation of the data and building services on top of them. Stating absolute or relative relations explicitly would be beneficial although I see the point of all being a C user. |
|
Dear Daniel Thanks for your responses and comments. Answers to a few questions:
I look forward to the next version. Thanks for your work. Cheers Jonathan |
|
All, |
|
Dear Charlie
All the GitHub postings are distributed to everyone on the CF email list, so
that it shouldn't be necessary to make individual arrangements for particular
issues.
Best wishes
Jonathan
|
|
It appears that these github hub messages are going to the cf-convention mail list rather than the cf-metadata mail list, so perhaps @czender is not on the cf-convetion mailing list? |
|
Yes, I only learned there was a cf-convention mail list (distinct from cf-metadata) yesterday :) |
Merge Daniel's Groups branch into my Groups branch on 20180907, preparatory to more work to submit and updated PR that address recent discussions at CF cf-convention#144
|
FYI I'm finally making progress on this and expect to have a full response and update PR next week. Thank you for your patience. |
… tomorrow after sleeping on it.
|
All, the changes described below were just submitted as a PR to Daniel's tree, which hopefully means they will modify #145 once accepted. I'm non-expert at Github, so perhaps that is inefficient. The original is viewable in my tree at https://github.com/czender/cf-conventions/tree/groups
I must use many words. I wish I had been at the Reading conference to say this in person: I may be the only defender of the lateral search feature so it falls on me to make the case for it. The one word that best summarizes why I think lateral search would be good for CF is "User-base". Geoscience researchers use an enormous amount of satellite-retrieved data stored with groups by providers notably including NASA and ESA. These agencies use HDF5EOS or netCDF4 to store data from dozens of platforms/instruments (Aura, MLS, OMI, S5P, TES, etc) and quite often data fields are in sibling (not ancestor) groups to the coordinates. For example, S5P has geophysical variables in This state of affairs developed over many years, and indicates that dataset producers like having coordinates in sibling groups of data fields. I doubt that NASA/ESA/etc. will start putting coordinates in ancestor groups rather than sibling groups just because CF recommends it, and even it they do, there will remain a decades-high mountain of data with the current organization. If/once CF adopts this groups proposal, one of three things is likely to happen:
To me "nearest" and "most proximal" mean the same thing. "Nearest" seems more vernacular, perhaps too vernacular? Nevertheless, I changed to "nearest" in the current PR and added to the glossary.
See immediately below.
I think there is no difference in the way we use "element" and "object" in the text for Groups proposal. However, "element" is already frequently used in CF to refer to elements of an array, definitely not the meaning that Groups intends to convey. In practice "objects" as used in the Groups proposal can only be variables (including coordinate variables, of course), and dimensions. In theory a group could itself be an "object", however the proposal does not at this point need to do that. Off-hand, I can't think of an instance where an out-of-group (OOG) attribute needs to be explicitly referred to. Attributes of OOG variables can be important, yet they are always referred to via the OOG variable, and there is never a direct reference to an OOG attribute. It's the variable's scope that matters, an attribute is always locally attached to a variable or group. Are there any counter-examples to this? If not, I think it is clearer and more precise to eliminate the use of both "element" and "object" in the Groups proposal, and replace those words with what they actually stand for, i.e., "variable" and/or "dimension". I modified the PR to do that. Similarly, I eliminated "identifier". We could instead have defined "identifier" to mean "a variable or dimension". That would be possible. Nevertheless, I think it's clearer to just say "variable or dimension" everywhere in the text. A group could also be considered an "identifier", thought this proposal does not need to do so.
The updated (by CZ) PR eliminates "element", "object", "identifier", and "Resolves to". The updated glossary now defines "Nearest dimension", "location", and Ancestor, sibling, and descendant groups. |
|
Dear Charlie If you're not an expert in GitHub, I'm an ignoramus, and I can't work out where to view the modifications you are proposing to the document. Perhaps you or someone else can lead me straight to the right place with a URL. Your comments above are helpful. Thanks for making the changes. I can't remember the detail of the lateral search algorithm, which Daniel showed us at the meeting. It was hard to remember, I thought, suggesting it's not obvious. I appreciate your reasons for wanting to retain it, though. Is there a more general and easily memorable algorithm which would include the present lateral-search as a subset? For example, you could accept any variable of the right name, wherever it can be found in the entire file, if it's not found in the ancestry of the reference. That would imply that it should be an error to include more than one variable of that name in the file, and if there is more than one, there's no rule about which one to choose. The data-reader could implement any search algorithm they want to find an acceptable variable. Best wishes Jonathan |
|
Jonathan, My CF-Groups "tree", i.e., my fork of CF with the Groups modifications in them, is viewable at https://github.com/czender/cf-conventions/tree/groups |
|
Jonathan, |
|
As an FYI, if you want to compare two branches or forks, you can view a pull request without actually creating it for others to see and comment on. So in this case, we can compare @czender's "groups" branch against the current cf-conventions master by going to "Pull Requests" in either repository and clicking "New Pull Request" you can select "compare across forks" and select the fork / branch(es) you want to compare. In this case you get a comparison page with a URL like this: If you scroll down you can switch to "Rich Diff" with the button that looks like a page in the upper left of a given asciidoc document. As long as you don't click "Create Pull Request" -- you are able to just look over the diffs. Carry on. |
|
Sorry about the long silence everyone, I've been traveling for the past several weeks and simply hadn't seen the notifications. As Charlie noted, he's made several changes to address the changes we've been discussing and I've incorporated them into the Pull Request. You can see the full set of changes here and the changes relative to the original PR here. As @dblodgett-usgs notes the rich diff function is really helpful for getting an overview of the changes. I have the impression that we're nearing conversion, is this shared by the rest of the group? I'd like to add my thoughts to what @czender has written concerning the lateral search: Although I do think that it is a bit confusing, especially for people who are used to object-oriented paradigms using inheritance and classes, there are a plethora of data in the wild which implement this and I think that it's good to describe how things should be found. I also agree that there are many data out there which reuse variable names when referencing coordinates, and the amount of such data is set to grow. It is likely that EUMETSAT is producing such data, as we will be disseminating products which contain observations from multiple instruments, all of which use different viewing geometries. Therefore they would have different |
|
Dear Daniel and Charlie Thanks to you for the changes, and to Dave for reminding me where to find the "rich diff". I had forgotten which icon it is. Here are some comments on the latest version.
I am keen on the approach in general and most of the details! I hope we will agree soon. Thanks for your efforts and patience. Best wishes Jonathan |
|
Hi Jonathan, Thanks for this input - I share your sentiment and also hope that we can reach a positive conclusion soon. I'll respond to your points inline below. All of these changes are reflected in the updated PR.
I see what you mean about the use of "element" in other parts of the Convention, particularly in reference to individual items within an array. I've reviewed our proposal and don't see a reason to define "element" specifically, and thus I've removed the definition from the glossary.
This is true. I've also modified the wording in that section of the proposal; you can find it in the updated version. @czender please correct this if I have misunderstood how the lateral search works.
I hope to have resolved this by changing the "Search by proximity" text as follows: "A variable or dimension specified with no path is the variable or dimension of the same name which can be found via a search of direct ancestor groups with the shortest number of intermediate groups. Do you find this clearer?
I see what you mean here, actually I think this is just a byproduct of text being moved around a lot. I've changed those three sentences to read: "When referencing out-of-group variables, it is the responsibility of the dataset producer to ensure that the dimension(s) utilized by the out-of-group variable are the same as those used by the referring variable." The intent here is to make sure that you don't refer to e.g. an auxiliary coordinate variable which uses different dimensions than the referring variable. If a data producer were to do this, it would not be possible to match the coordinates to the variable calling them up; the original text was designed to prevent this. However, the two sentences you referred to were in the wrong spot, and in my opinion they're not needed anyway, as the scoping rules clearly explain how that should work anyway, so I've deleted them and moved the whole block into the "Scope" section.
Right. I think that the newest version is clearer and reflects this unambiguously.
@czender I'll pass this to you, as the King of Lateral Search :)
What would you suggest for the appendix? Correct me please if I'm wrong, but I don't think that the appendix is prescriptive - the title is "Recommended Practices and Annotated Examples for Using Groups" so I see no danger that people would see this as a prescription. At the last meeting in Reading my feeling was that the community felt that having examples as guidance for different data types would be helpful; we've included them in the appendix with the intent of providing such examples without being prescriptive. I'm happy to discuss this in greater detail, and I don't want to regard your reservations, but I need more information about what they are in order to try to address them :) Best regards, |
|
Dear Daniel Thanks. This is much better. "Search by absolute path" should start with "A" not "An". In "Search by relative path" I would say "(i.e. containing a slash but not with a leading slash e.g. I think "Search by proximity" can be stated more concisely and perhaps more clearly with less repetition, thus: "A variable or dimension specified with no path (for example, "For coordinate variables that are not found in the referring group or its ancestors, a further strategy is provided, called lateral search. The lateral search proceeds downwards from the root group width-wise through each level of groups until the sought coordinate is found. This placement of coordinates and lateral search strategy to find them are discouraged. They are allowed mainly for backwards-compatibility with existing datasets, and may be deprecated in future versions of the standard." I didn't understand the justification "Because coordinate variables must share dimensions with the variables that reference them", which I have omitted above. However, it made me realise that the lateral search algorithm may have problems with dimensions. It could find a coordinate variable with a dimension that has the right name e.g. The section on "Application of attributes" would be simpler and more compatible with the conventions if it referred to Appendix A. Maybe I've said that before? It seems to me that global atts mentioned in Appendix A should be allowed as group atts, with some exceptions e.g. Sorry to be vague about Appendix I. Yes, I understand and appreciate the intention of it. Please could we talk about that once we've agreed about the text of the main conventions? Best wishes and thanks Jonathan |
|
Hi All, |
|
Dear Charlie You're right, I had not understood that from the current wording, but indeed, this is something that has to be addressed, which I hadn't thought of. Also, does this algorithm apply to multidimensional auxiliary coordinate variables? It's possible that their dimensions might be defined in different levels of group, which is trickier. The upward search can proceed only as far as the group in which the dimension (or any of the dimensions) of the coordinate (or auxiliary coordinate) variable is defined. Best wishes Jonathan |
- explore recursively all nested groups to create the subdatasets list
- subdatasets in nested groups use the /group1/group2/.../groupn/var standard
NetCDF-4 convention, excepting for variables in the root group which do not
have a leading slash for backward compatibility with the NetCDF-3 driver
- when accessing a subdataset using NETCDF:$file:$path, the leading slash is optional
- global attributes of each nested group are also collected in the GDAL dataset
metadata, using the same convention /group1/group2/.../groupn/NC_GLOBAL#attr_name,
excepting for the root group which do not have a leading slash for backward compatibility
- when searching for a variable containing auxiliary information on the selected subdataset,
like coordinate variables or grid_mapping, we now also search in parent groups (using NCDFResolveVar).
- reference to coordinate variables using the "coordinates" attribute support now also absolute paths,
this allow for example to specify coordinate variables located outside the group of the selected variable
or its parents. Relative paths could be implemented if needed.
WARNINGS/TODOS:
- all this work must be consolidated with current CF discussion about
adding groups support to the convention: cf-convention/cf-conventions#145
- I think "lateral search" should be added to the driver for better
support of existing NetCDF-4 files from NASA and ESA angencies, even
if this will not be included in future CF convention: this point is currently
discussed by the CF team here: cf-convention/cf-conventions#144 (comment)
- for the moment the NetCDF vector support is disabled because I failed to
merge it with the groups support for raster (I work on it but it's very complex)
- at this time I did not check current GDAL autotests, and new ones must
be added to validate groups support (covering all the changes)
- maybe some config variable should be added to be able to disable
the new groups support
- driver documentation must be updated
|
The way I do it is to go to the pull request - #145 in this case - and then click on the "Files changed" tab. This then shows all the files changed as raw diffs, and you can choose to view the Rich diff, or view the whole file. If there's a different/better way - I'd like to know, too! |
|
I usually do it the way David describes. However, if that doesn't work, you could download the files and diff them using your favorite tool. |
|
Dear Daniel, Charlie and others Regarding my novice question, the point (for me) to remember is that the pull request number can't be discovered automatically from an issue. Hence it's convenient for readers to have it restated it in an issue whenever it's relevant, I suppose. Thanks for your work on this, and for the clarifications and compromises. I am almost content with this proposal now! I realise I'm still contributing just now as a reviewer rather than a moderator, but don't be concerned. I can be objective and tell myself when the debate has been concluded satisfactorily. :-) Also let me emphasise that I think this proposal fits well into CF and will be a valuable addition.
I am sure we can adopt this proposal soon. As soon as we have, we should consider your appendix on best practice for groups as a separate addition, if you don't mind - only because otherwise I'm worried about delaying the main proposal. Best wishes Jonathan |
|
Thank you for refreshing this proposal with your new questions and comments, Jonathan. Regarding "underlying": I agree that it is synonymous with and could be replaced by "of" in this context. Regarding |
|
Hi @JonathanGregory and all, sorry for spamming with multiple force pushes but I was having trouble with table formatting and didn't have access to an offline renderer. I've implemented the comments as requested. Jonathan, do you still feel good about summarising the discussion or should we reach out to somebody else from the governance panel when the 3 weeks are up? I feel you're pretty objective but I don't want to put you in an uncomfortable spot ;) |
|
Dear all Thanks for the latest changes, Daniel. Personally I am happy with this now. I am willing to be moderator still as well! Speaking in that capacity, my summary of this discussion is that there are apparently no unanswered comments or questions. Does anyone have any further comment to make on the proposal as currently shown in #145? Note that this pull request does not contain the new appendix on best practice for groups, which we'll consider separately when this one is agreed. Daniel, is there a corresponding pull-request for the conformance document? Best wishes Jonathan |
|
Thanks @JonathanGregory ! Currently there is no corresponding pull request for the conformance document - I'm a bit swamped right now but I'll see if I can find a willing partner in crime so we can produce one ;) Best regards, |
|
@erget and @JonathanGregory , I drafted a test netCDF file: I tried to make it succinct, yet able to test numerous Groups features, including global/group attributes, absolute/relative/ancestor searches for out-of-group coordinates in an ancestor group, absolute/relative/ancestor searches for out-of-group coordinates in a sibling group, distinct coordinates with the same name yet different dimensions in the same file, incorporating ensemble realization in both the group name and as metadata. Feedback welcome. Is this too much? too little? Feedback welcome. If it looks good I'll create a PR for it. Charlie |
|
Hi @JonathanGregory - we've passed the three week boundary again. Should we freeze the proposal as it stands? What are the next steps? My thoughts are that now that the content of the change is agreed we might move on to "implementing" it as rules in the conformance document. |
|
Dear Daniel |
|
@erget I suggest that this text be incorporated into a PR for the Conformance document. These points are relatively easy to test for conformance. I could not think of any other points that the Groups feature allows, forbids, or recommends that could be easily tested for. Do you think this is complete? 2.7 Groups: Requirements: Auxiliary coordinate variables must reside in the referring group or one of its direct ancestors. The attributes Per-variable attributes including Recommendations: NUG-coordinate variables that are not in the referring group or one of its direct ancestors should be referenced by absoulute or relative paths rather by relying on the lateral search algorithm. |
|
@czender @JonathanGregory forgot to update on this - I've proposed a corresponding update to the Conformance document in this PR. Next steps? |
|
Daniel @erget, yes, I will look at the proposed update to the conformance document. I will do that next week. Ros has had a look at it and commented by email as well. |
|
@JonathanGregory thanks very much! |
|
Dear Daniel et al. |
|
Dear All,
Best Regards, |
Yes. The NASA Dataset Interoperability Recommendations for Earth Science: Part 2 recommends exactly that. |
Yes. Cell boundaries, cell measures, ancillary_variables, climatology, formula_terms, etc. may reference out-of-group (OOG) variables with the same restrictions that apply to coordinates (which are the focus of the OOG portion of the Groups documentation). Since OOG coordinates are allowed, we must allow OOG bounds variables, for example, and the reasoning for the whole menagerie like anvillary_variables, climatology, formula_terms, etc. follows suit. |
Agreed. |
|
@erget -- can we identify a moderator for this? I haven't been following this closely enough to play that roll unfortunately. Maybe @JonathanGregory? |
|
Jonathan moderated (very helpfully and patiently!). I'm closing this as the PR has been merged. |
As discussed in CF meeting on 20 June 2018 in Reading, UK, we'd like to add support for the use of groups in CF files. Charlie and I have drafted an appropriate pull request containing the suggestions we'd like to implement.
Basically, the idea is to allow elements in CF files to refer to others which are not in the same group. The proposal defines ways of locating variables in this situation and tries to capture current ways of doing so "in the wild".
I'll update this issue with further material on this (Pull Request reference, summary presentation discussed at the meeting last June, and the proposal as drafted up till that point) as soon as the PR has an URL.
We haven't updated the conformance rules and checker yet, as we want to agree on the content first.
The text was updated successfully, but these errors were encountered: