This directory contains all the scripts necessary to train and execute pose recognition based on frame extraction from a live video feed.

The work presented in this directory is based on dongdv95's hand-gesture-recognition repository, and makes use of the mediapipe pose detection framework.
Requirements to run the scripts in this repository can be found in the requirements.txt file
pip install -r requirements.txt
Training is done in a Jupyter Notebook. To install Jupyter Notebook, run:
pip install notebook
To run the notebook:
jupyter notebook
A complete overview of the workflow can be found here: YMCA_Training_Screen_Record.mp4
-
A) We use the get_image.py script to generate the image dataset. The image dataset is divided in subfolders, each containing pictures of a person in the specified position. To generate the example above, we trained the 5 following data classes : "Y", "M", "C", "A", "wandering". Each data class contains about 65 pictures.
-
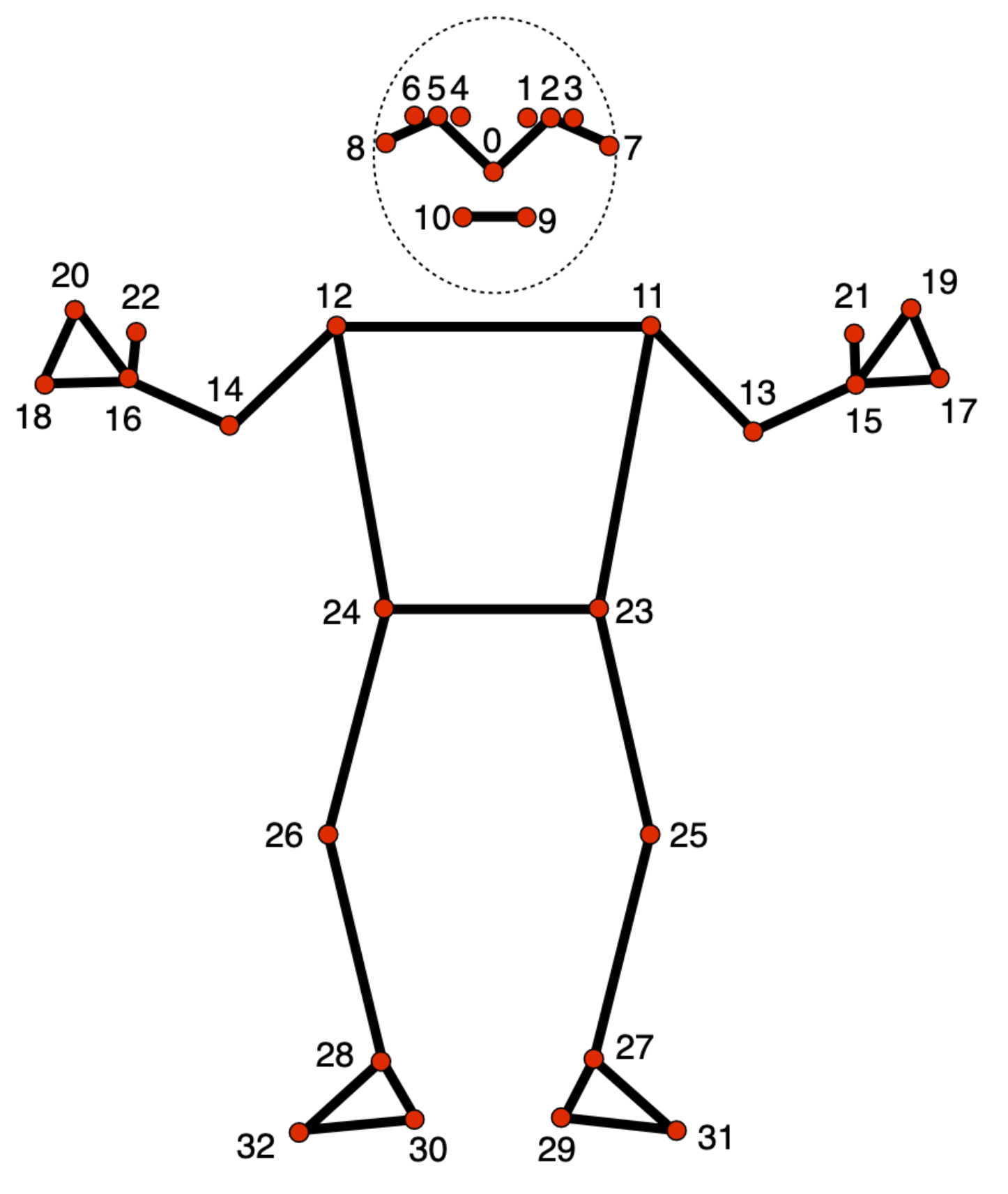
B) We use the get_data.py script to generate the csv dataset that will be used for training the SVM model. For each image in the dataset we have generated, we obtain skeleton keypoints using mediapipe pose detection. We then associate keypoints coordinates (
$(x,y)\in[0,1]^2$ ) and their visibility factor ($v\in[0,1]$ ) to the name of the data class. -
C) We train a support vector classification model using the train.ipynb script. We further use the training script to assess whether the model has been properly trained on the dataset (see the confusion matrix at the end of the file, for instance). Finally, we can export the svm model using the
pickle.dump methodin a file called model.pkl. -
D) Once training is done, we can run the main script, pose_gesture_recog.py. This script takes webcam frames as input by default, so we can assess the detection time it takes for the model to recognize poses on live stream, and whether the detection is accurate or not.