Copyright (C) 2021 AutoML Groups Freiburg and Hannover
While early AutoML frameworks focused on optimizing traditional ML pipelines and their hyperparameters, another trend in AutoML is to focus on neural architecture search. To bring the best of these two worlds together, we developed Auto-PyTorch, which jointly and robustly optimizes the network architecture and the training hyperparameters to enable fully automated deep learning (AutoDL).
Auto-PyTorch is mainly developed to support tabular data (classification, regression) and time series data (forecasting). The newest features in Auto-PyTorch for tabular data are described in the paper "Auto-PyTorch Tabular: Multi-Fidelity MetaLearning for Efficient and Robust AutoDL" (see below for bibtex ref). Details about Auto-PyTorch for multi-horizontal time series forecasting tasks can be found in the paper "Efficient Automated Deep Learning for Time Series Forecasting" (also see below for bibtex ref).
Also, find the documentation here.
From v0.1.0, AutoPyTorch has been updated to further improve usability, robustness and efficiency by using SMAC as the underlying optimization package as well as changing the code structure. Therefore, moving from v0.0.2 to v0.1.0 will break compatibility.
In case you would like to use the old API, you can find it at master_old.
The rough description of the workflow of Auto-Pytorch is drawn in the following figure.
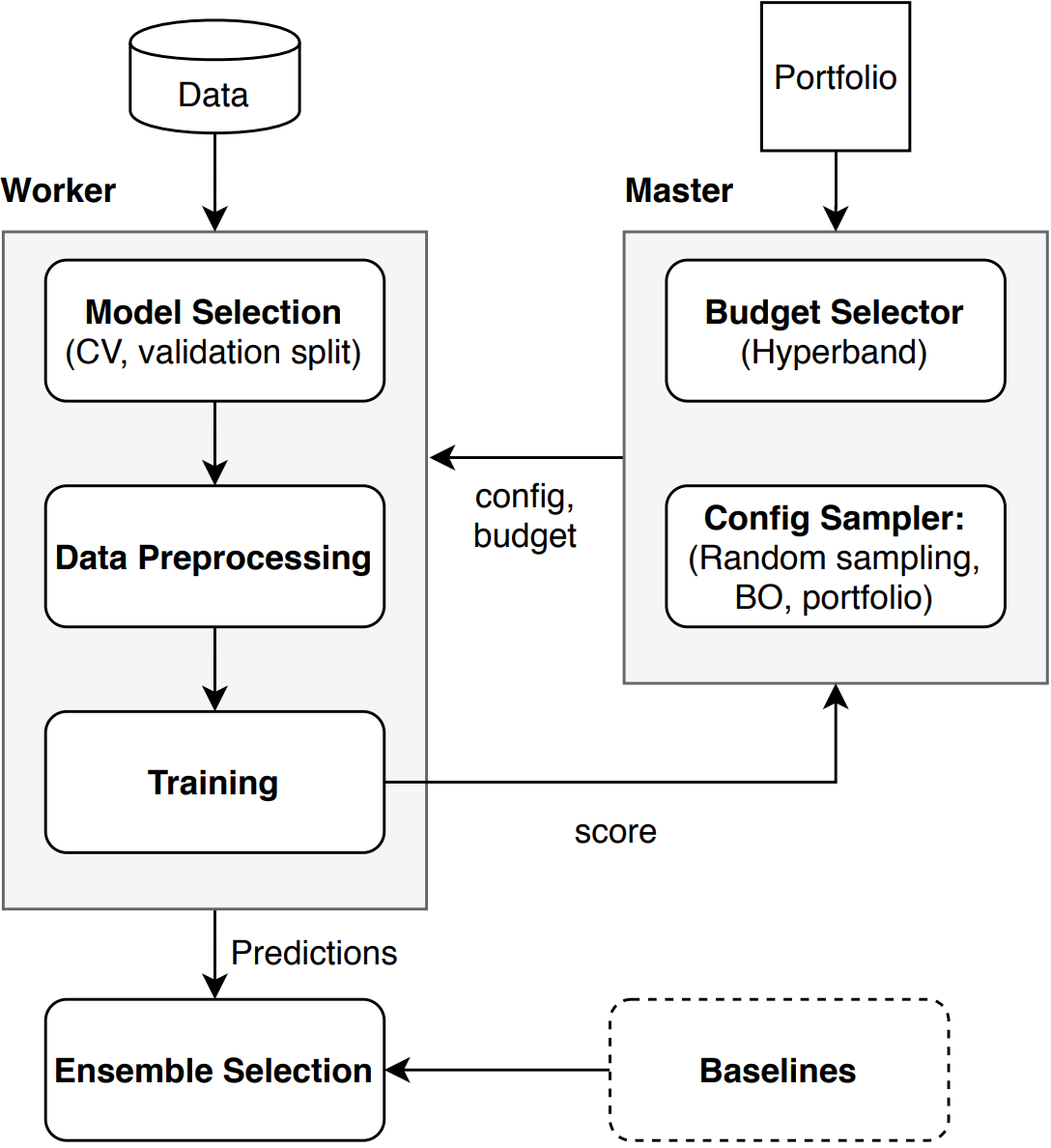
In the figure, Data is provided by user and Portfolio is a set of configurations of neural networks that work well on diverse datasets. The current version only supports the greedy portfolio as described in the paper Auto-PyTorch Tabular: Multi-Fidelity MetaLearning for Efficient and Robust AutoDL This portfolio is used to warm-start the optimization of SMAC. In other words, we evaluate the portfolio on a provided data as initial configurations. Then API starts the following procedures:
- Validate input data: Process each data type, e.g. encoding categorical data, so that Auto-Pytorch can handled.
- Create dataset: Create a dataset that can be handled in this API with a choice of cross validation or holdout splits.
- Evaluate baselines
- Tabular dataset *1: Train each algorithm in the predefined pool with a fixed hyperparameter configuration and dummy model from
sklearn.dummythat represents the worst possible performance. - Time Series Forecasting dataset : Train a dummy predictor that repeats the last observed value in each series
- Tabular dataset *1: Train each algorithm in the predefined pool with a fixed hyperparameter configuration and dummy model from
- Search by SMAC:
a. Determine budget and cut-off rules by Hyperband
b. Sample a pipeline hyperparameter configuration *2 by SMAC
c. Update the observations by obtained results
d. Repeat a. -- c. until the budget runs out - Build the best ensemble for the provided dataset from the observations and model selection of the ensemble.
*1: Baselines are a predefined pool of machine learning algorithms, e.g. LightGBM and support vector machine, to solve either regression or classification task on the provided dataset
*2: A pipeline hyperparameter configuration specifies the choice of components, e.g. target algorithm, the shape of neural networks, in each step and (which specifies the choice of components in each step and their corresponding hyperparameters.
pip install autoPyTorch
Auto-PyTorch for Time Series Forecasting requires additional dependencies
pip install autoPyTorch[forecasting]
We recommend using Anaconda for developing as follows:
# Following commands assume the user is in a cloned directory of Auto-Pytorch
# We also need to initialize the automl_common repository as follows
# You can find more information about this here:
# https://github.com/automl/automl_common/
git submodule update --init --recursive
# Create the environment
conda create -n auto-pytorch python=3.8
conda activate auto-pytorch
conda install swig
python setup.py install
Similarly, to install all the dependencies for Auto-PyTorch-TimeSeriesForecasting:
git submodule update --init --recursive
conda create -n auto-pytorch python=3.8
conda activate auto-pytorch
conda install swig
pip install -e[forecasting]
In a nutshell:
from autoPyTorch.api.tabular_classification import TabularClassificationTask
# data and metric imports
import sklearn.model_selection
import sklearn.datasets
import sklearn.metrics
X, y = sklearn.datasets.load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = \
sklearn.model_selection.train_test_split(X, y, random_state=1)
# initialise Auto-PyTorch api
api = TabularClassificationTask()
# Search for an ensemble of machine learning algorithms
api.search(
X_train=X_train,
y_train=y_train,
X_test=X_test,
y_test=y_test,
optimize_metric='accuracy',
total_walltime_limit=300,
func_eval_time_limit_secs=50
)
# Calculate test accuracy
y_pred = api.predict(X_test)
score = api.score(y_pred, y_test)
print("Accuracy score", score)For Time Series Forecasting Tasks
from autoPyTorch.api.time_series_forecasting import TimeSeriesForecastingTask
# data and metric imports
from sktime.datasets import load_longley
targets, features = load_longley()
# define the forecasting horizon
forecasting_horizon = 3
# Dataset optimized by APT-TS can be a list of np.ndarray/ pd.DataFrame where each series represents an element in the
# list, or a single pd.DataFrame that records the series
# index information: to which series the timestep belongs? This id can be stored as the DataFrame's index or a separate
# column
# Within each series, we take the last forecasting_horizon as test targets. The items before that as training targets
# Normally the value to be forecasted should follow the training sets
y_train = [targets[: -forecasting_horizon]]
y_test = [targets[-forecasting_horizon:]]
# same for features. For uni-variant models, X_train, X_test can be omitted and set as None
X_train = [features[: -forecasting_horizon]]
# Here x_test indicates the 'known future features': they are the features known previously, features that are unknown
# could be replaced with NAN or zeros (which will not be used by our networks). If no feature is known beforehand,
# we could also omit X_test
known_future_features = list(features.columns)
X_test = [features[-forecasting_horizon:]]
start_times = [targets.index.to_timestamp()[0]]
freq = '1Y'
# initialise Auto-PyTorch api
api = TimeSeriesForecastingTask()
# Search for an ensemble of machine learning algorithms
api.search(
X_train=X_train,
y_train=y_train,
X_test=X_test,
optimize_metric='mean_MAPE_forecasting',
n_prediction_steps=forecasting_horizon,
memory_limit=16 * 1024, # Currently, forecasting models use much more memories
freq=freq,
start_times=start_times,
func_eval_time_limit_secs=50,
total_walltime_limit=60,
min_num_test_instances=1000, # proxy validation sets. This only works for the tasks with more than 1000 series
known_future_features=known_future_features,
)
# our dataset could directly generate sequences for new datasets
test_sets = api.dataset.generate_test_seqs()
# Calculate test accuracy
y_pred = api.predict(test_sets)
score = api.score(y_pred, y_test)
print("Forecasting score", score)For more examples including customising the search space, parellising the code, etc, checkout the examples folder
$ cd examples/Code for the paper is available under examples/ensemble in the TPAMI.2021.3067763 branch.
If you want to contribute to Auto-PyTorch, clone the repository and checkout our current development branch
$ git checkout developmentThis program is free software: you can redistribute it and/or modify it under the terms of the Apache license 2.0 (please see the LICENSE file).
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
You should have received a copy of the Apache license 2.0 along with this program (see LICENSE file).
Please refer to the branch TPAMI.2021.3067763 to reproduce the paper Auto-PyTorch Tabular: Multi-Fidelity MetaLearning for Efficient and Robust AutoDL.
@article{zimmer-tpami21a,
author = {Lucas Zimmer and Marius Lindauer and Frank Hutter},
title = {Auto-PyTorch Tabular: Multi-Fidelity MetaLearning for Efficient and Robust AutoDL},
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
year = {2021},
note = {also available under https://arxiv.org/abs/2006.13799},
pages = {3079 - 3090}
}@incollection{mendoza-automlbook18a,
author = {Hector Mendoza and Aaron Klein and Matthias Feurer and Jost Tobias Springenberg and Matthias Urban and Michael Burkart and Max Dippel and Marius Lindauer and Frank Hutter},
title = {Towards Automatically-Tuned Deep Neural Networks},
year = {2018},
month = dec,
editor = {Hutter, Frank and Kotthoff, Lars and Vanschoren, Joaquin},
booktitle = {AutoML: Methods, Sytems, Challenges},
publisher = {Springer},
chapter = {7},
pages = {141--156}
}@article{deng-ecml22,
author = {Difan Deng and Florian Karl and Frank Hutter and Bernd Bischl and Marius Lindauer},
title = {Efficient Automated Deep Learning for Time Series Forecasting},
year = {2022},
booktitle = {Machine Learning and Knowledge Discovery in Databases. Research Track
- European Conference, {ECML} {PKDD} 2022},
url = {https://doi.org/10.48550/arXiv.2205.05511},
}Auto-PyTorch is developed by the AutoML Groups of the University of Freiburg and Hannover.