Sorting search results #21
Comments
|
@corbanbrook AFAIK this issue should be filed against the fuzzaldrin library which is used by fuzzy-finder to filter and score results. |
|
fuzzaldrin simply does scoring and sorting of arrays of strings or objects. Some of my above recommendations might be outside the scope of the project. One solution would be for the fuzzaldrin to add option for custom filter/sorting callbacks. |
|
Would also be nice if the fuzzy finder could have the results filtered in terms of importance for type of project. For instance, a Ruby on Rails project, if I start typing a model's name, have the first result usually be '/app/models/model_name.rb', instead of having the first result be 'spec/models/model_name_spec.rb'. Most times I want to deal with the model, not the spec. |
|
It would be nice as well to have more recency to the find logic, although it will mainly (it does seem intermittent especially of you switch to another app and back again) suggest the last file accessed to allow quick switching between files, it would be good if it always gave precedence on the file based on last access allowing to easily work between several files. A good example of where this works well is Textmate's implementation of cmd-t find file. The sorting there works well. |
|
Here's an example where the order isn't great. The second result is what I want, and it's a much closer match, so I don't know why it's second.
|

|
Even worse:
I wanted the last result in this instance. (I hope these examples are useful, apologies if they're noise) |

|
Another one
|

|
Coming from ST3, the fuzzy matcher really drives me crazy that it lists the specs before the actual controllers I want.
Is there any config which changes how the fuzzy finder works, or do we need to improve the underlying fuzzy finding library to improve the searching? |

|
+1 for this |
|
I decided to play with Atom for the first time this weekend; I immediately found myself frustrated with the strange fuzzy ordering in Atom's select list views. If we're going to improve fuzzy matching in Atom, there are lots of things to consider:
Alright — hopefully this is useful/interesting to someone. I plan to slowly work on improvements to both (For fun, I started by replacing |
|
👍 as the current solution is rather useless - and can even be faster to find the file manually |
|
👍 Would be great if we could get some progress on this. |
|
Improved sorting / scoring: The above pull request addresses at least some of the issues raised here. |
|
Since I'm working on a lot of Rails projects with ActiveAdmin, I'm often annoyed when I end up in an ActiveAdmin file for a particular resource instead of a model file. I was thinking about improving this by sorting the fuzzy-finder results by usage. I.e. if a files in some folder are worked on more often, they are ranked higher. I'm happy to implement this experimentally and make a pull request if other people approve of this idea also. |
|
👍 for some improvements that make finding commonly used files easier. sublime seemed to have done a better job putting the file i actually want to open at the top (using rails here as well) |
|
Just in case further examples are helpful:
|

|
There's now an "use Alternate Scoring" option in fuzzy finder that use it. But it does not cover any knowledge about the file themselves, such as preference for recent / frequent / certain files. |
|
I just tried the Atom Beta with "Use Alternate Scoring" enabled and it's a huge improvement, though still not as good as Sublime Text. I have a project with a huge number of files, including Doxygen generated html files that I rarely want to look at. I tried to find a file named "matchOptimisticB.h". In SublimeText I can type "mob.h" and get the right file as the first suggestion. In Atom Beta it is the ninth choice, preceded by eight html files I have no interest in. One thing that might help Atom: if the user provides a file type suffix, prefer names that match that suffix exactly over names that use that suffix as a prefix. Another thing that might help (though I really hope it won't come to this, and it's not needed by Sublime) is to allow the user to disable directory patterns. In my case I might eliminate searches of Doxygen-generated html files and would definitely elimiate .os files (why in the world is it showing binary libraries?). |
|
Ok please open an issue on fuzzaldrin-plus I can give it a look. I'd need On Thu, Dec 3, 2015, 13:51 Russell Owen [email protected] wrote:
|
|
I just submitted this issue. I hope it helps. Thank you very much for trying to improve Atom’s fuzzy search. — Russell On Dec 3, 2015, at 10:56 AM, Jean Christophe Roy [email protected] wrote:
|
|
Does anyone know if there is an equivalent issue open discussing the Cmd-Shift-P search algorithm? |
|
you're speaking of command palette? Should already be integrated. If you On Tue, May 3, 2016, 20:22 Thomas Rich [email protected] wrote:
|
|
This is a pretty ancient issue, so I have little hope of improvement arriving any time soon, but here's my two cents:
Two things wrong with the way the fuzzy finder currently works both illustrated with the above example.
But with the full So scoring should somehow take into account how close the search terms are to each other in the filename, and prioritize
These two tweaks would make the search algorithm a lot stronger. |


|
hi @adamreisnz , as a curiosity, is this happening with alternate scoring turned on ? There was a strong preference for word "togetherness" in that version. From screenshot I'm guessing it's not, but if it is I'll add a few of those to test benchmark. |
|
@jeancroy thanks for looking into it, but yes, it's in fact enabled:
The version I'm using is 1.18.0-dev-f4a83b238 |

|
Another possibility is that alternate score is used for ranking while classic is used for highlighting. One feature of the new one is a bias toward file name (vs whole path) when we match file extension exactly I think you are batling against that when you are using keyword from the path but end with extensions To sum up your request, you want the htm behavior to happens even in html case ? I'm not sure what the algorithm does because of how scambled the higligth is. |
|
Well, my use case as you might deduce from my example is that in a large project, there will be many components. Each component might have an So the way I tend to quickly open the file I want, is by specifying the parent component This usually works fine, but in the above case it was messing it up due to the existence of another similar file in the same path ( I think my use case is fairly common, so I wouldn't expect to be "battling" against the fuzzy finder's system with it.
|
|
You're right on all account, in this case it seems the algorithm just like the Good news is that the issue is more constrained than say lack of prioritizing "full word matches". (Here
I'll open a different issue for highlight regression it should group |

|
Yeah that looks better in your screenshot, highlighting member properly. And interesting that it likes the |
|
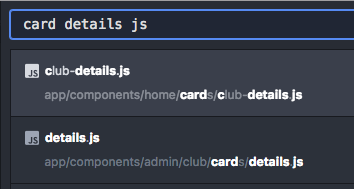
Looks like in the latest version (just built Atom from master yesterday) there's still some scoring issues. For example this result:
It should not prioritise I did not type a Note that when I type
I think once a search term has been used/matched in the path, it should not try to match it again for another part of the path. In addition, results with the least amount of non-matching characters between the matches should probably score highest. |

|
Another example in Atom 1.20 dev where prioritisation is not what one would expect;
|

|
Guys, any activity on this issue please? It's infuriating to keep opening the wrong files because the fuzzy finder sorting logic is off. VSCode manages to do it correctly, why not Atom? Perhaps it would be worthwhile looking at their algorithm.
|


|
@adamreisnz looks like this was fixed a month ago by @jeancroy but we're running an outdated version of fuzzaldrin-plus. Will create a PR. |
Multiple schemes can be employed to achieve results which are most relevant to the user. Predicting which file a user wants out of a long list of possible matches and presenting it first can help speed up development time/maintain flow and train of thought. Here are some ideas to discuss:
The text was updated successfully, but these errors were encountered: