Asp.net Core not Collecting Garbage #3409
Comments
|
Are you still waiting from us to make progress on this issue? |
|
Hi, That project was abandoned but it's very important for us to get to the bottom of this issue. I could use the info how to record more info on GC. Also, please describe what exactly I can provide that will help got to the bottom of this issue. |
|
@sinapis are you trying to find out the issue you described above or just interested in recording more info in general? for the former, are you in a position to build a private coreclr.dll and use that in your project that's showing the symptom you described? if so I can just give you a commit with proper logging enabled. |
|
@Maoni0 Yes, I can build a private coreclr.dll and use it. If there is are additional logging you would like me to add, I'd be more than happy to do so. In general, tell me what you need. I'll do whatever I can. |
EnvironmentWe are currently on .NET Core, version DetailsWe are seeing this at Stack Overflow with our canary .NET Core web socket server as well. We are observing 2 behaviors:
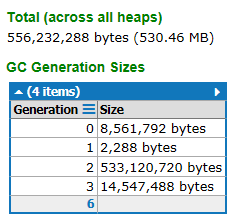
Here's a before and after of a forced all-generations GC run:
Note that gen 0 is cleared, the long-lived websocket object trees (expected) are moved to gen 2, and overall memory usage drops to 530MB. However, overall process memory was at 2.8GB and remains at 2.8GB. Even though only 530MB is used internally. We currently have a timer running inside the application forcing GC to get by for other testing, but that's not a great idea and really shouldn't be necessary. I currently consider this a blocker to deploying Stack Overflow on .NET Core. What can we do to help? We have memory dumps and can readily do analysis and testing to assist. |

|
How's the fragmentation? That can cause symptoms like this when there's lots of pinned buffers. |
|
How much memory is on the system? |
|
There should be no new pinned buffers when using ASP.NET Core. The only pinned buffers are the ones Kestrel uses. |
|
What we'll need:
|
|
@Tratcher Attaching @sebastienros Specs:
I don't think we can provide memory dumps here as they contain user cookies due to the nature of the application and that's a security issue, but we're more than happy to assist as best we can. On the perfview front: send instructions and happy to help. |
Looking at the dump doesn't look huge? |
When you say "grow to gigabytes", this is not something that is unexpected. I understand you are aware that the Server GC will be triggered by memory pressure. If there is no pressure (you have 64GB) it doesn't have to be triggered. So it's all about how much available memory was left when you decided to kill it. Are these numbers the ones you shared before or were they higher that that? Quoting the documentation:
These explanations are very fuzzy: "acceptable threshold". It doesn't tell what is acceptable or not, and you might have other acceptance thresholds ;)
Same. I assume that's an expected behavior, though it doesn't mean it's what should have happened, but nothing tells me it shouldn't behave this way from the data you shared. @Maoni0 is this is an expected behavior based on the numbers that were provided? I have never tried to run an ASP.NET app and experience how the GC behaves with such an amount of RAM to see what these thresholds look like. |
Oh no, it just takes a while to grow (due to the long-lived nature of sockets, connections ramp up slowly). It grows well beyond what's here. I understand being lazy and using available memory...but that's way beyond anything I've ever seen in Gen 0. With every .NET full framework application we have today: GC runs as expected, and memory is freed instantaneously or very shortly after a run. This is critical behavior for a shared web tier. If every app only runs GC when there's memory pressure, you're lighting 8 sticks of dynamite at once all to go off at the same time and pegging CPU when they do get a pressure signal. I'm really hoping this is a GC bug, because if it's expected behavior we have legitimate concerns and blockers with such behavior. Standing by to run whatever diagnostics will help. And we're more than happy to run a custom build with better logging, etc. Whatever we can do - this is my highest priority to fix. I'm happy to force a GC and get numbers, but will await feedback here before doing so - lest we lose data you'd like to see. |

|
My assumption; perhaps incorrect, was a Gen0 would be triggered if it needed to allocate more from the OS (or after xN OS allocations)? |
|
Would you like to try the workstation GC as a mitigation for now? |
|
@sebastienros we have a mitigation (GC on a timer), but are more concerned with solving the root issue. I'm loading the latest dump up now to see what state the GC itself is in and see if I can find anything. Potentially relevant: we're using libuv as the base layer here, which may or may not be common to the other issues? I'll update with more info as I dig here. |
|
Thread dump for the curious: SocketServerThreads.txt |
|
@NickCraver are you on Windows? |
|
and @sinapis I apparently completely dropped the ball on the logging part...really sorry about that! I dunno if it still helps to give you a commit to log now... |
|
@Maoni0 Yep, Windows Server 2016 - happy to test a custom build if it'll give you more data. |
|
@NickCraver could you please collect some GC ETW traces? you can use this commandline for perfview: perfview /GCCollectOnly /nogui /accepteula /NoV2Rundown /NoNGENRundown /NoRundown /merge:true /zip:true /BufferSize:3000 /CircularMB:3000 /MaxCollectSec:7200 collect this collects for 7200s. you can start it right before you start your process. if 2 hours isn't enough feel free to replace it with longer. please share the resulting trace. |
|
@Maoni0 A few qeustions:
|
|
You can't restrict to a single process, but share the process id and/or the startup dll name. |
|
Alrighty - capture is running now, I'll have results in a few hours - can we please arrange a secure/NDA (we already have NDA in place) upload in the mean time? craver at stackoverflow on my end |
|
capturing it running while it already has a big gen0 is not going to help. GC is not a point in time thing, in order to figure out why you are in a situation, we need to see the history. so we need a trace to capture enough history that led up to that point. so if it takes 2 hours before the gen0 gets to be a couple of GB, we need those 2 hours captured. or you could capture at least a while before it got to that point. |
|
Understood - restarting the process and capture here. Edit: Now restarted. I set the capture to 3 hours for a few GB (lower traffic at night...takes longer), and I received the folder invite to upload to - thanks! |
|
@sebastienros @Maoni0 The Process details:
|
Well, OneDrive you mean? ;) |
|
@sebastienros or you can run it in a container if you simply want to limit that process's memory usage. on Windows this is a job object. |
As in windows still sees the overall memory usage, it doesn't go down any. The GC behavior here would be good if it was a dedicated machine. But it's not great behavior in a shared server situation (which we have a lot of). This includes local development on Windows 10 (our only option for Visual Studio). As servers get more and more cores (Intel is going to double the amount of cores soon), are users expected to absorb double gen0 budgets as a result? It seems at some point we need this to be adjustable or the inherent defaults to account for overall limits. Core counts are adjusting fast, and with that variable in play without a corresponding control...things will get hairy. It's increasingly difficult to manage things on shared systems as a result, and the more cores that are in play, the more sharing that's likely...or likely to be more complex at least. On the dumps front: we have sensitive data in there, but I'm happy to pull the data from the existing dumps if you've got any WinDBG pointers or other such that that's reasonable to convey (understandable if not). |
|
@NickCraver: increasing the number of cores should come with a RAM increase. The sizing of servers stays a complicated problem. At work, we are going to linux containers managed by Mesos and I'm not sure that terminating a process when a threshold is detected is the right solution (it would be the same with a Windows Job). @Maoni0: do you have a timeframe for having in .NET Core the settings you described in https://blogs.msdn.microsoft.com/maoni/2018/10/02/middle-ground-between-server-and-workstation-gc/? At Windows level, the memory manager is able to deal with a lot of applications consuming "memory" beyond the available RAM; especially if the heaps contain objects that are no more accessed (would be easily paged out on very fast SSD). I don't have exact numbers about how many complete 4KB pages of gen0 are not accessed at all before a collection but could be important. |
|
We have very few pinned objects (only what Kestrel pins) - and my demo app above demonstrates that this happens with or without. Assuming servers come with RAM increases is not safe. Intel releases X performance with new cores (or AMD, whatever floats your boat!) but we don't need more RAM. We get no benefit from it. As an SRE and the person who specs most of our server hardware, I'm going to have a hard time justifying "because the GC doesn't run" as the cause for needing to spend thousands more per box on memory. Intel is planning on doubling the number of cores coming up, we don't need double the RAM. At least, not in the foreseeable future. I think any assumption that RAM goes with cores is not a valid one we should be basing technical decisions on here, FWIW. |
|
@NickCraver: my point was more related to the number of applications you want to run on a machine (hence my Mesos example). The more apps, the more RAM. |
|
Maybe I'm just being obtuse in this case, but is there any reason the GC doesn't just run every so often? Not running in hours is our case. Is there a way to tell it to run on an interval, regardless of usage? That's effectively what our workaround way, a timer with a GC call...but that seems pretty silly for every application to do. It seems like a sanity check of: Let's say once every 5 minutes: "have I run in 30 minutes? No? Okay run", otherwise do nothing. Is that an insane idea? I'd be surprised if such a thing hadn't been discussed before...I'm curious what the thinking is there. |
|
Can bring down the SOH segment size via environment variable; prior to startup? COMPlus_GCSegmentSizeIs hex value in bytes and > 4MB & multiple of 1MB, so 1000000, 2000000, 4000000, etc According to docs it defaults are the following: 64bit: > 8 CPUs its 1GB on server; whereas 256MB on workstation [Credits to @kevingosse on twitter, for working out units and that its hex.] That base level will be then multiplied by the number of heaps? Which leads also to the other knobs:
Should be able to set them via the environment variables; prior to execution COMPlus_GCHeapCount // starts at core count
COMPlus_GCNoAffinitize
COMPlus_GCHeapAffinitizeMask |
|
@NickCraver We've implemented basically that in our base framework for WAS hosted services. There's some periodic handle usage by WAS or IIS to monitor the service (something like 3 Event, 1 Thread, and 1 something else handle if I remember correctly) that will eventually get released when the finalizer runs so it eventually gets cleaned up when GC happens. Having the GC run "every so often" would eliminate the need for us to have this timer code. |
|
Thinking about what's different... Running raw Kestrel (without a Job object or cglmits) is going to behave to the GC defaults; though I assume @NickCraver is using IIS. So question is does IIS use Job objects; where the GC maximums would be obeyed; however a difference with ASP.NET Core 2.x is it spawns a second dotnet process to run (2.2 will allow in-proc). Does that second process then still obey the limits set by IIS? |
|
In this case - no IIS (though we will be elsewhere). The web socket server is |
|
ANCM uses job objects when creating a new dotnet.exe process: https://github.com/aspnet/AspNetCore/blob/master/src/IISIntegration/src/AspNetCoreModuleV2/OutOfProcessRequestHandler/serverprocess.cpp#L74. @benaadams I'm confused about:
IIS doesn't have a GC. How would these maximums be set by IIS? Environment variables would be respected if WAS is restarted. |
I'd assume it would use these settings?
|

|
Hitting those app pool limits just cause an app pool recycle ( spawns a new w3wp.exe while the existing finishes serving the current requests). IIS worker processes don't use job objects, the ASP.NET Core IIS module seems to be, but that's different. I've seen Job objects mentioned here and at the parent issue as well and did a quick test and it does not seem that setting lets say a 100Mb memory limit on dotnet.exe via adding it to a job object is triggering GC's either. ( I could be doing it wrong). |
|
Wanted to share my related experience, Hopefully it is relevant to this discussion. Over the last one year we moved to a more micro servicey architecture and have 20+ containerized applications deployed on many XXL instances in AWS ECS. Each deployable unit based on microsoft/dotnet:2.1-aspnetcore-runtime image We do a lot of caching, and work offloading via queues and workers, hence more than 50% of our http services, except for the user facing ones , are hit at avg ~200 requests per minute. Keeping this is mind we had set our resource allocation for these sparsely hit services very modestly. 128mb memory soft limit and 512mb hard limit. As soon as we released, we noticed that the memory graph was consistently at 400%, and the CPU was extremely spikey, perf was also erratic. Since we have hard limits set on our containers, unlike what OP observed, we consistently ran into memory pressure which caused GC, which caused CPU spikes, alerts, restarts, hairloss. After noticing that other users have had a similar experience , we decided to allocate each service with 1024MB memory limit. Which felt too excessive given what these services do. However, as soon as we did that, everything stabilized. Stable lines, no spikes, no restarts. Even if we turned off caching, the services handled the load flawlessly 👏 . However, this is not sustainable. We are enjoying the small small many independent services, but giving each service minimum 1GB becomes a bottleneck. Our solution so far has been to add more instances to our cluster to accommodate new services. Its getting too expensive :( . I love C# and .Net, so please forgive me for calling this out, but we recently deployed 3 of our new services in Go, and they have been chugging along fine with just 128mb hard memory limit. For this reason primarily, it is becoming hard to justify using aspnet core for our newer services. |
|
@arishlabroo could that be this bug - https://github.com/dotnet/coreclr/issues/19060 and corresponding PR dotnet/coreclr#19518 ? |
|
@kierenj 🤔, seems possible, but wouldn't the latest microsoft/dotnet:2.1-aspnetcore-runtime image include that fix? Since the bug was closed 3 months ago. |
|
@arishlabroo I think that fix landed in 2.1.5 that was released month ago October 2, 2018. |
|
@arishlabroo IMO this kind of many small services that are limited in memory should use the workstation GC. The processes would then hardly go over 100MB, and most probably less than 50MB. |
|
@arishlabroo as @sebastienros pointed out, have you tried Workstation GC? if not, would you mind trying it out? |
|
also I've seen this WindowsJobLock tool used by folks - this is NOT going to work for limiting GC heap usage because the physical limit is read when the runtime is loaded. if you wait till the process is already running and then specify the limits they are not going to get read, period. I'm actually looking at processes running within a job with small memory limits this week so I will publish a blog entry to talk about my findings. for folks who want to specify a small limit, Workstation GC is certainly a good starting point if you are currently using Server GC. |
|
@Maoni0 @sebastienros is it possible to provide some recommendations? |
|
@tmds for sure...I will be providing guidelines in my blog entry. thanks for your patience! |
|
Sharing the link to the blog post |
Copied from #1976
@sinapis commented on Dec 19, 2017
Hi,
I have the same issue with ASP.NET Core 2. I've took a memory dump and tried analyzing. From what I see the problem is exactly as the OP said. My application starts with allocation about 75 MB, and very quickly it goes all the way to ~750MB, out of it 608MB is "Unused memory allocated to .NET".
First snapshot at app start:
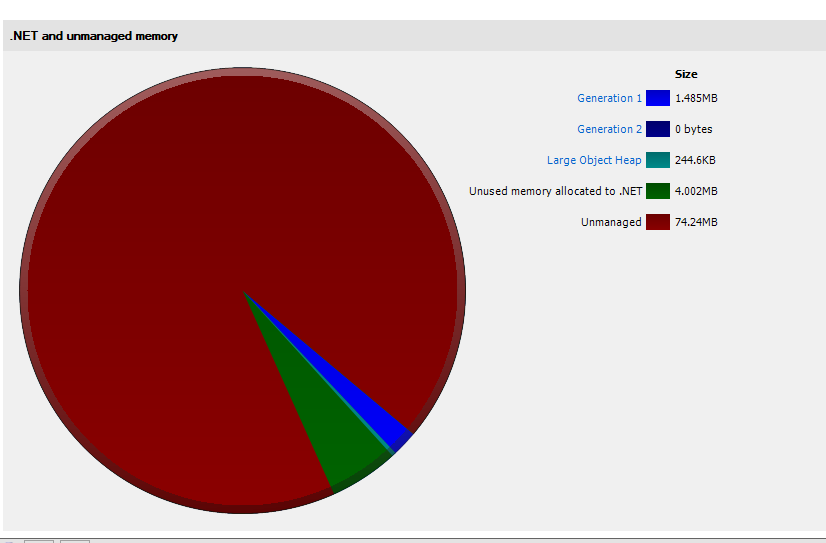
Second snapshot after 3 minutes and 100 requests:

@sebastienros commented on Apr 5
@sinapis commented on Apr 8
@sebastienros, several questions:
@davidfowl commented on Apr 8
We personally haven't seen any evidence that the issue is in Kestrel. It still looks like an application problem.
@sebastienros commented on Apr 10
@sinapis
Would any of you be able to share an app that shows the issue? If I could repro it we would be able to find the reason, or at least remove some code piece by piece and isolate a minimal repro.
@sinapis commented on Apr 10
@sebastienros I can't share the app, but I can share the session from PerfView session + memory dump.
Some description: I have a ASP.NET Core 2 Web API, I've created a load test of 200 users all sending the same request over 10 seconds. Overall 775 requests were processed.
This app jumped to almost 1 GB memory usage in task manager and stayed like that. Looking at the dump I can count about 18 MB:
So the questions is where did almost 1 GB go?
@sebastienros commented on Apr 10
@sinapis Thanks
The behavior you are describing is not unexpected, the GC will allocated some memory as necessary on the peak load, and just release it over time. It's the GC Server mode, and usually wait for idle periods to release it and not affect your app perf. The amount of memory it will reserve depends of the total memory available on the system.
We would definitely see an issue if it kept increasing. I assume that if you don't send anymore requests and let your app run you will see the memory usage going down.
Could you run the same thing until it consumes most of your system memory? Or at least long enough with the same load that it will show it growing continuously? I will still get a look at your current dumps.
@sebastienros commented on Apr 10
Also can you take dumps during and at the end of the jobs, so we can see the detals.
@Maoni0 commented on Apr 11
@sinapis I looked at your ETW trace. it is puzzling to me - you survived very little in the last induced gen2 GC yet we still chose to keep that much memory committed. your application seems edge case (you mostly just did only background GCs due to LOH allocations) - I wonder if we have some accounting errors there (another possibility is errors in the numbers reported but if you already verified that you have that much committed that's a smaller possibility). if you could repro with something you can share with me, that'd be fantastic; otherwise if it's possible to run your app with some logging from GC (I can give you a commit that does that) that'd be helpful too.
@sinapis commented on Apr 11
@Maoni0 please share how should I enable GC logging
If there is some other data you would like me to provide in order to disprove accounting error please let me know what should I provide you with and how (maybe tell perfview to collect more data?)
I'll try creating a minimum repro, but not sure I'll succeed since I don't know where the problem is.
@sebastienros hopefully I will provide another dump with more memory consumption today
The text was updated successfully, but these errors were encountered: