-
Notifications
You must be signed in to change notification settings - Fork 82
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
[SDK-parquet] add parquet version tracker (#609)
### Description **1. Added Parquet Version Tracker Functionality** - Updated steps to include set_backfill_table_flag logic for selective table processing. - added a processor status saver for parquet **2. Schema and Table Handling Updates** - Updated the logic for handling backfill tables: - Renamed the tables field with backfill_table in - ParquetDefaultProcessorConfig. - Adjusted validations and logic to ensure only valid tables are processed. ParquetTypeEnum improvements: - Added mappings and validations for table names. - Enhanced schema initialization and writer creation. **3. Tests updated** - Modified tests to reflect changes in backfill_table handling and validation. - Updated table name checks to ensure compatibility with the new logic. - Added test coverage for: Invalid backfill tables. **4. General Code Improvements** - Removed redundant logic in ParquetDefaultProcessor. - Moved shared functionality (e.g., writer creation) to reusable helper functions. - initialize_database_pool centralizes database pool setup for Postgres. - Handles error cases cleanly. - initialize_gcs_client abstracts GCS client setup using provided credentials. - Consolidated initialization of schemas, writers, and GCS uploaders into modular functions. Enhanced comments for better readability and maintainability. Test Plan   backfill DQ check on number of rows for Move_resources 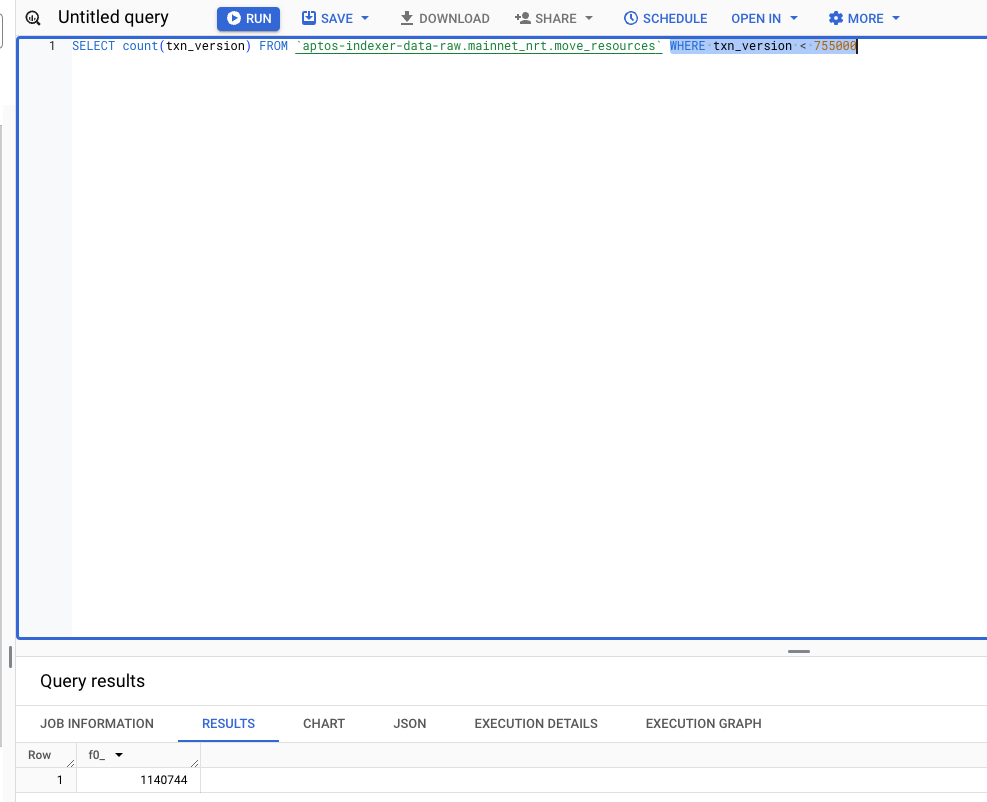 
{kind=link}
- Loading branch information
Showing
24 changed files
with
682 additions
and
330 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.