Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
[SPARK-49072][DOCS] Fix abnormal display of text content which contai…
…ns two $ in one line but non-formula in docs ### What changes were proposed in this pull request? There are some display exceptions in some documents currently, for examples: - https://spark.apache.org/docs/3.5.1/running-on-kubernetes.html#secret-management  - https://spark.apache.org/docs/latest/sql-migration-guide.html  The reason is that the `MathJax` javascript package will display the content between two $ as a formula. This PR aims to fix abnormal display of text content which contains two $ in one line but not non-formula in docs. ### Why are the changes needed? Fix doc display exceptions. ### Does this PR introduce _any_ user-facing change? Yes, Improve user experience about docs. ### How was this patch tested? Local manual tests with command `SKIP_API=1 bundle exec jekyll build --watch`. The new results after this PR: 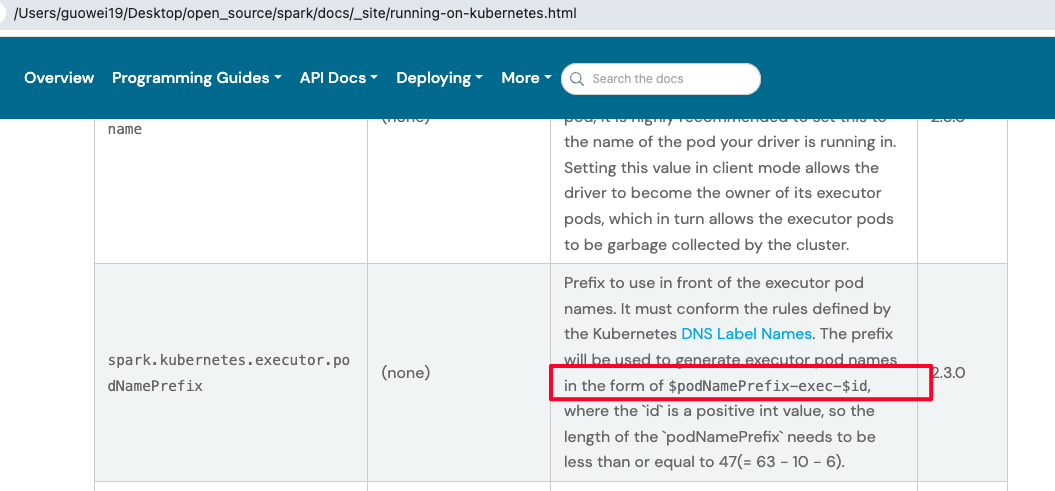  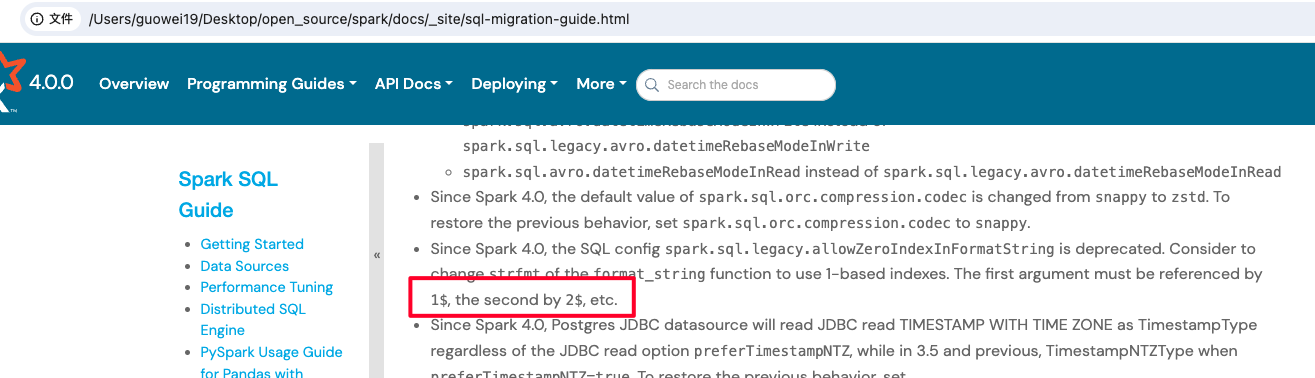  ### Was this patch authored or co-authored using generative AI tooling? No. Closes #47548 from wayneguow/latex_error. Authored-by: Wei Guo <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]>
- Loading branch information
1 parent
a9daed1
commit cbe3633