Z by HP Unlocked Challenge 3 - Audio Recognition - Special thanks to Hunter Kempf for helping create this challenge! Watch the tutorial video here: https://youtu.be/9Txxl0FJZas

The Challenge is to build a Machine Learning model and code to count the number of Capuchinbird calls within a given clip. This can be done in a variety of ways and we would recommend that you do some research into various methods of audio recognition.
Unlocked is an action-packed interactive film made for data scientists. Sharpen your skills and solve the data driven mystery here: https://www.hp.com/us-en/workstations/industries/data-science/unlocked-challenge.html
The Data is split into Training and Testing Data. For Training Data we have provided enough clips to get a decent model but you can also find, parse, augment and use additional audio clips to improve your model performance.
In order to download and properly build our Training sets we have provided details and some example code for how to interact with the files.
- Download Capuchinbird Calls:
def url_response(path_url_list):
path, url = path_url_list
r = requests.get(url, stream = True)
with open(path, 'wb') as f:
for ch in r:
f.write(ch)
def make_path_and_url(clip_id):
file_path = os.path.join("Raw_Capuchinbird_Clips",f"XC{clip_id} - Capuchinbird - Perissocephalus tricolor.mp3")
url = f"https://xeno-canto.org/{clip_id}/download"
return file_path, url
clip_ids = ['114131', '114132', '119294', '16803', '16804', '168899', '178167', '178168', '201990', '216010', '216012',
'22397', '227467', '227468', '227469', '227471', '27881', '27882', '307385', '336661', '3776', '387509',
'388470', '395129', '395130', '401294', '40355', '433953', '44070', '441733', '441734', '456236', '456314',
'46077', '46241', '479556', '493092', '495697', '504926', '504928', '513083', '520626', '526106', '574020',
'574021', '600460', '65195', '65196', '79965', '9221', '98557', '9892', '9893']
paths_and_urls = list(map(make_path_and_url, clip_ids))
ThreadPool(4).imap_unordered(url_response, paths_and_urls)
Parsing_Single_Call_Timestamps.csv- Clip Timestamps where Capuchinbird Calls are audible- id: xeno-canto.org clip id
- start: Start time of single call in seconds
- end: End time of single call in seconds
def parse_capuchinbird_clips(clip_tuple):
"""
Parses the audio clips described by the clip_tuple into the Parsed_Capuchinbird_Clips folder
"""
clip_id, starts_and_ends = clip_tuple
ms_to_seconds = 1000
mp3_filename = os.path.join("Raw_Capuchinbird_Clips",f"XC{clip_id} - Capuchinbird - Perissocephalus tricolor.mp3")
sound = AudioSegment.from_mp3(mp3_filename)
count = 0
for start, end in starts_and_ends:
sub_clip = sound[start*ms_to_seconds:end*ms_to_seconds]
sub_clip_name = f"XC{clip_id}-{count}"
sub_clip.export(os.path.join("Parsed_Capuchinbird_Clips",f"{sub_clip_name}.wav"), format="wav")
count += 1
def df_to_list_of_call_tuples(df):
"""
Extracts a list of tuples from the provided Parsing_Single_Call_Timestamps csv file
"""
output = []
for clip_id in df["id"].unique():
clip_df = df[df["id"]==clip_id].copy()
starts = clip_df["start"].tolist()
ends = clip_df["end"].tolist()
clip_list = []
for i in range(len(starts)):
clip_list.append((starts[i],ends[i]))
output.append((clip_id,clip_list))
return output
calls_df = pd.read_csv("Parsing_Single_Call_Timestamps.csv")
calls_list = df_to_list_of_call_tuples(calls_df)
ThreadPool(4).imap_unordered(parse_capuchinbird_clips, calls_list)
Other_Sound_Urls.csv- Other Birds, Animals and Forest Noises- id: Sequentially increasing clip id
- url: Link to freesoundslibrary.com zip file of clip
def download_and_unzip_sounds(id_url_list):
"""
Downloads and Unzips into the correct folder all of the Raw Not Capuchin Clips
a user inputs in the id_url_list.
"""
clip_id, url = id_url_list
path = os.path.join("Raw_Not_Capuchinbird_Clips",f"{clip_id}.zip")
destination_path = "Raw_Not_Capuchinbird_Clips"
url_response((path,url))
with zipfile.ZipFile(path, 'r') as zip_ref:
zip_ref.extractall(destination_path)
os.remove(path)
def df_to_list_of_url_tuples(df):
"""
Extracts a list of tuples from the provided Sound_Urls csv file
"""
output = []
ids = df["id"].tolist()
urls = df["url"].tolist()
for i in range(len(ids)):
output.append((ids[i],urls[i]))
return output
urls_df = pd.read_csv("Other_Sound_Urls.csv")
url_list = df_to_list_of_url_tuples(urls_df)
ThreadPool(4).imap_unordered(download_and_unzip_sounds, url_list)
- Parse Other Sounds:
def parse_not_capuchinbird_clips(raw_file_name):
raw_audio_folder_path = "Raw_Not_Capuchinbird_Clips"
selected_clips_folder_path = "Parsed_Not_Capuchinbird_Clips"
full_path = os.path.join(raw_audio_folder_path, raw_file_name)
sound = AudioSegment.from_mp3(full_path)
# Get Count of ~ 3 second clips from file
ms_to_s = 1000
num_clips = math.floor(len(sound)/ms_to_s)//3
if num_clips>0:
array_vals = np.array_split(np.array(range(len(sound))),num_clips)
count = 0
for clip in array_vals:
start = int(clip[0])
end = int(clip[-1])
clip = sound[start:end]
clip.export(os.path.join(selected_clips_folder_path,f"{raw_file_name}-{count}.wav"), format="wav")
count += 1
else:
sound.export(os.path.join(selected_clips_folder_path,f"{raw_file_name}-0.wav"), format="wav")
ThreadPool(4).imap_unordered(parse_not_capuchinbird_clips, os.listdir("Raw_Not_Capuchinbird_Clips"))
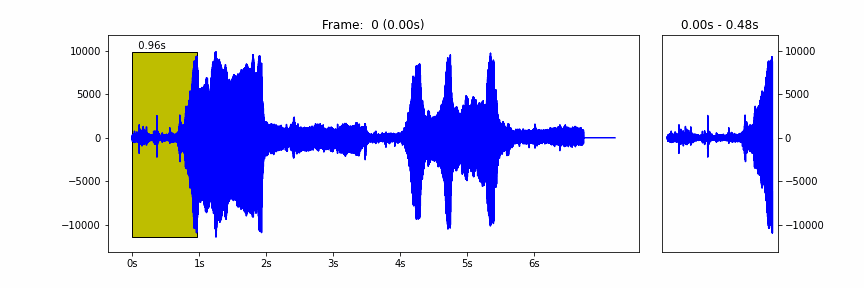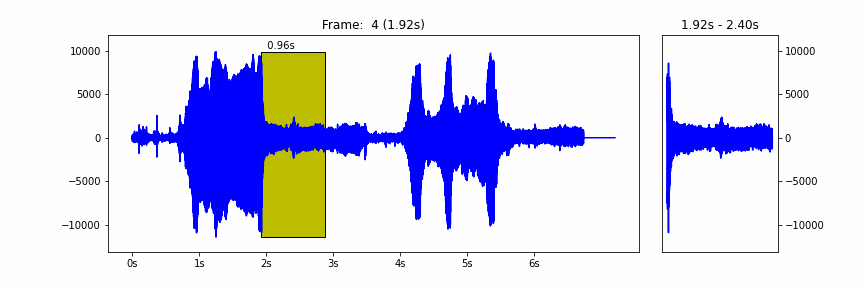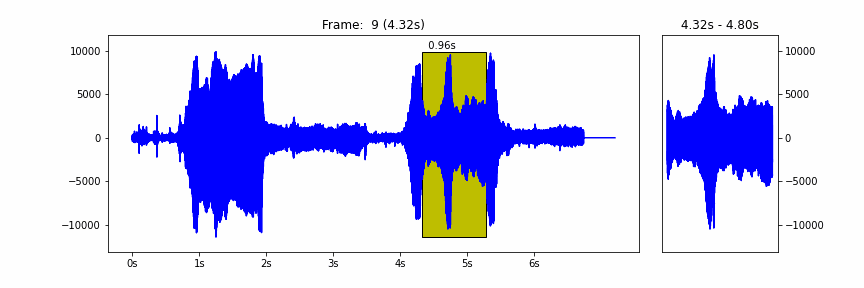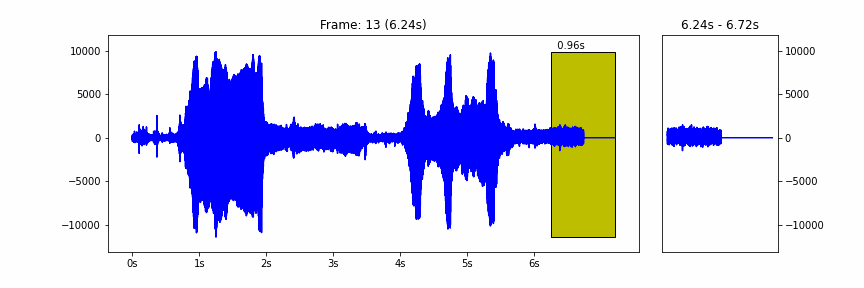
Forest Recordings- Folder of audio clips to predict count of bird calls in (Your Goal to Predict)
We have provided some starter code that downloads the training set, builds a simple model and arrives at a simple count of calls per clip. All three phases can be tweaked and improved from including additional audio clips in the training set to building more complex models to more complex Capuchinbird call counting code. More generally there are some good resources that we would suggest to learn more about audio recognition which will be provided below.