经常从github克隆别人的项目,加上自己的数据来训练模型,但是每个人的代码风格又非常的不一致。搞得我现在写代码就 跟印度军备万国造一样,非常混乱,搞得代码可读性非常差,移植性也不好。下次碰到新的算法,又得从头到尾全部重新来一遍,实在是浪费时间。
正好,网上碰到一个项目,就是一个pytorch模板项目github,挺不错的,但是里面用到了一个pytorch的高级封装库ignite。这个我有点驾驭不了,只好改一改,自己仿照着来一套自己的模板。
我的设计原则:
- 设计模板各模块时最好能将各模块完全分离,不要耦合,模块调用规则要简单。
- 不使用第三方库。
- 模型设计模块
- 数据加载模块
- 日志系统
- 配置文件模块
- 训练
- 从配置中获取参数进行训练
- 从上次断开处继续训练模型
- 意外断开时能保存模型
- 测试
- 用测试数据评估模型性能
- 推理
- 单张图像展示效果
配置文件库用的比较多的主要有两个库:yacs和yaml。各有各的特色,各有各的优点吧。但是我都不喜欢。所谓配置参数,还是使用字典数据类型比较方便,以键值对的形式方便增、删、改、查。我在一个开源项目yolact中看到了 配置文件系统的另一种解决方案,作者自定义了一种配置类型:
class Config(object):
def __init__(self, config_dict):
for key, val in config_dict.items():
self.__setattr__(key, val)
def copy(self, new_config_dict={}):
ret = Config(vars(self))
for key, val in new_config_dict.items():
ret.__setattr__(key, val)
return ret
def replace(self, new_config_dict):
if isinstance(new_config_dict, Config):
new_config_dict = vars(new_config_dict)
for key, val in new_config_dict.items():
self.__setattr__(key, val)
def print(self):
for k, v in vars(self).items():
print(k, ' = ', v)这个类使用起来也很方便,使用一个字典就能初始化了。
想要改变当前对象的值,使用replace就行了,可以传一个字典,也可以传一个Config对象。
想要创建一个新的Config对象,可以使用当前对象的copy方法,可以传值(字典类型),也可以不传值.
我自定义了一个日志类,简单方便。而且可以多日志运行。可以设置日志打印格式,可以设置日志按天打印,每天一个日志文件。简单的使用方法如下:
from utils import Plog
if __name__ == '__main__':
log1 = Plog("train")
log2 = Plog("test")
log1.debug("ceshi")
log2.info("train")数据加载无非分两块,一个是数据读取,另一个是数据变换。下面是我读取数据的模块。
├── __init__.py
├── build.py
├── datasets
│ ├── Caltech256.py
│ └── voc_dataset.py
└── transforms
├── augmentations.py
└── customTransforms.pydatasets文件夹是数据读取,transforms文件夹是数据变换。build.py定义对外的接口。
模型我全放在modeling文件夹下了。里面还有个layer文件夹,这里是pytorch没有的自定义的一些网络层。
modeling/
├── EfficientNet.py
├── alexnet.py
├── densenet.py
├── googlenet.py
├── inception.py
├── layers
│ ├── MBlock.py
│ ├── SEBlock.py
│ ├── activation.py
│ └── conv_layer.py
├── mnasnet.py
├── mobilenet.py
├── resnet.py
├── shufflenetv2.py
├── squeezenet.py
└── vgg.py1000类的ImageNet数据集实在是太大了,hold不住。而100类的数据集cifar100感觉有点小,我选的是包含257类(包含一个背景类)的Caltech数据集,共有30000多张图片。 使用各模型进行训练测试,训练10轮。这里目的仅在测试模型,就不多做精细化处理了,也不求训练到最佳效果。
| 模型名称 | top1准确率 | 模型大小 | batch-size |
|---|---|---|---|
| Alexnet | 64.04059933133415 | 222MB | 256 |
| Resnet50 | 84.40470179709448 | 92Mb | 64 |
| EfficientNetB0 | |||
| wide_resnet101_2 | 80.74754309035815 | 479Mb | 16 |
关于上面结果说明下, Alexnet训练到第8轮的时候loss和top1基本趋于稳定了,top1在60左右。而且训练集上和验证集上的准确率是差不多的,也就是刚好比较拟合。
Resnet50第一轮训练完验证集top1就已经65.67了,比Alexnet训练10轮的效果还要好。在第八轮的时候,训练集上的top1基本上到98——100了,这时候的验证集上top1是82左右。模型表达能力太强,已经过拟合了。
wide_resnet101_2模型太大,我的batch-size只能设置在16了,这时候其实训练的时候非常不稳定,第一轮中每个batch的top1在0-60之间震荡,第一轮结束验证集上top1为43,在第10轮结束的时候,top1验证集上是80.2。loss还比较大,感觉继续训练的话准确率还能继续提升。
感受:不同的batch-size对模型的影响比我想象中的要大的多。这里有篇文章对batch-size大小有比较详细的说明。
看下下面这个图,当batch-size过小时,可能梯度收敛比较震荡,需要更长的时间才能收敛甚至不收敛。
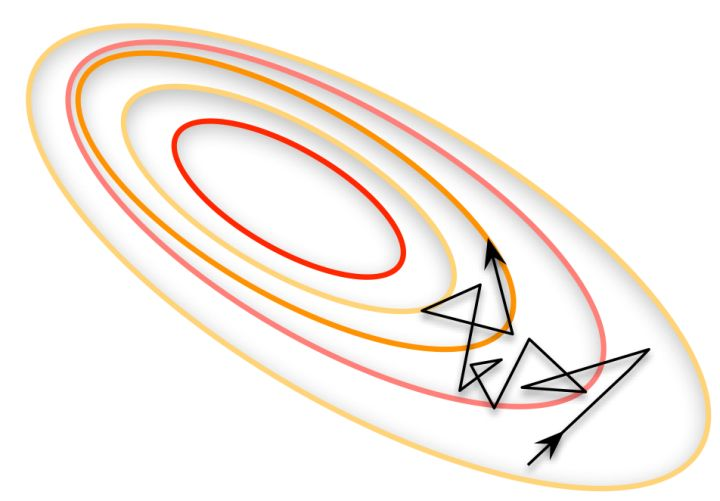

如果GPU显存不够的话,可以尝试多个batch之后再进行梯度计算。