MILABOT : A Deep Reinforcement Learning Chatbot
paper : https://arxiv.org/abs/1709.02349
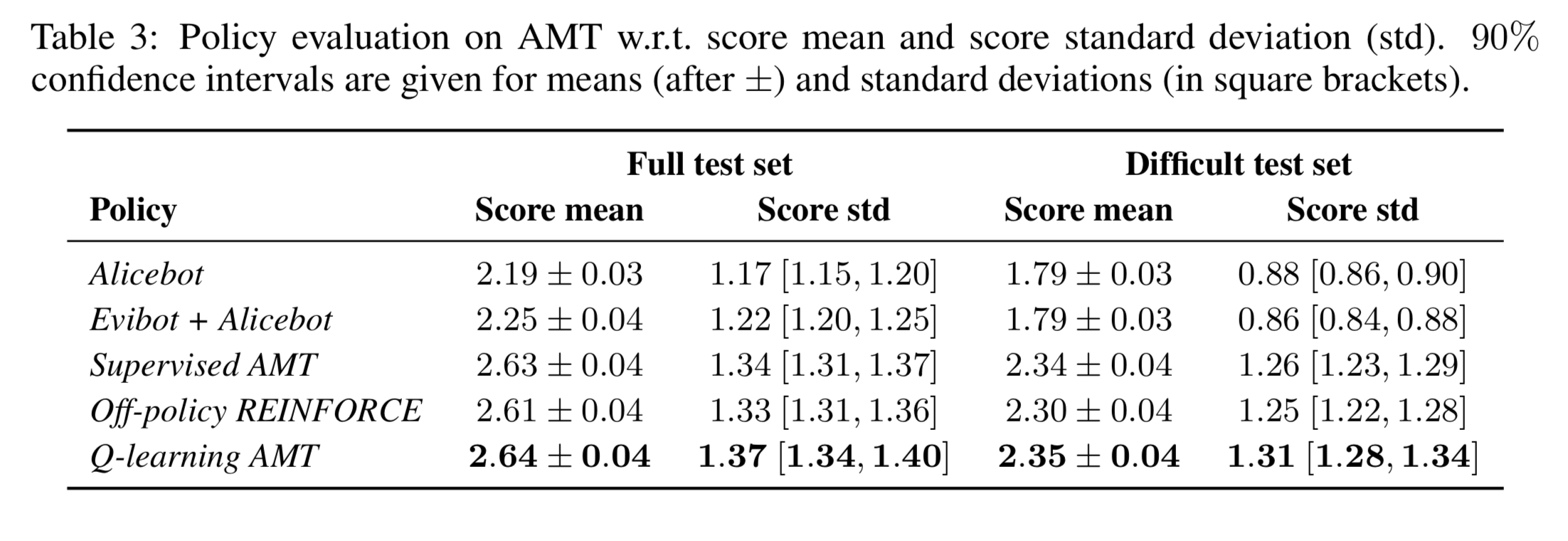
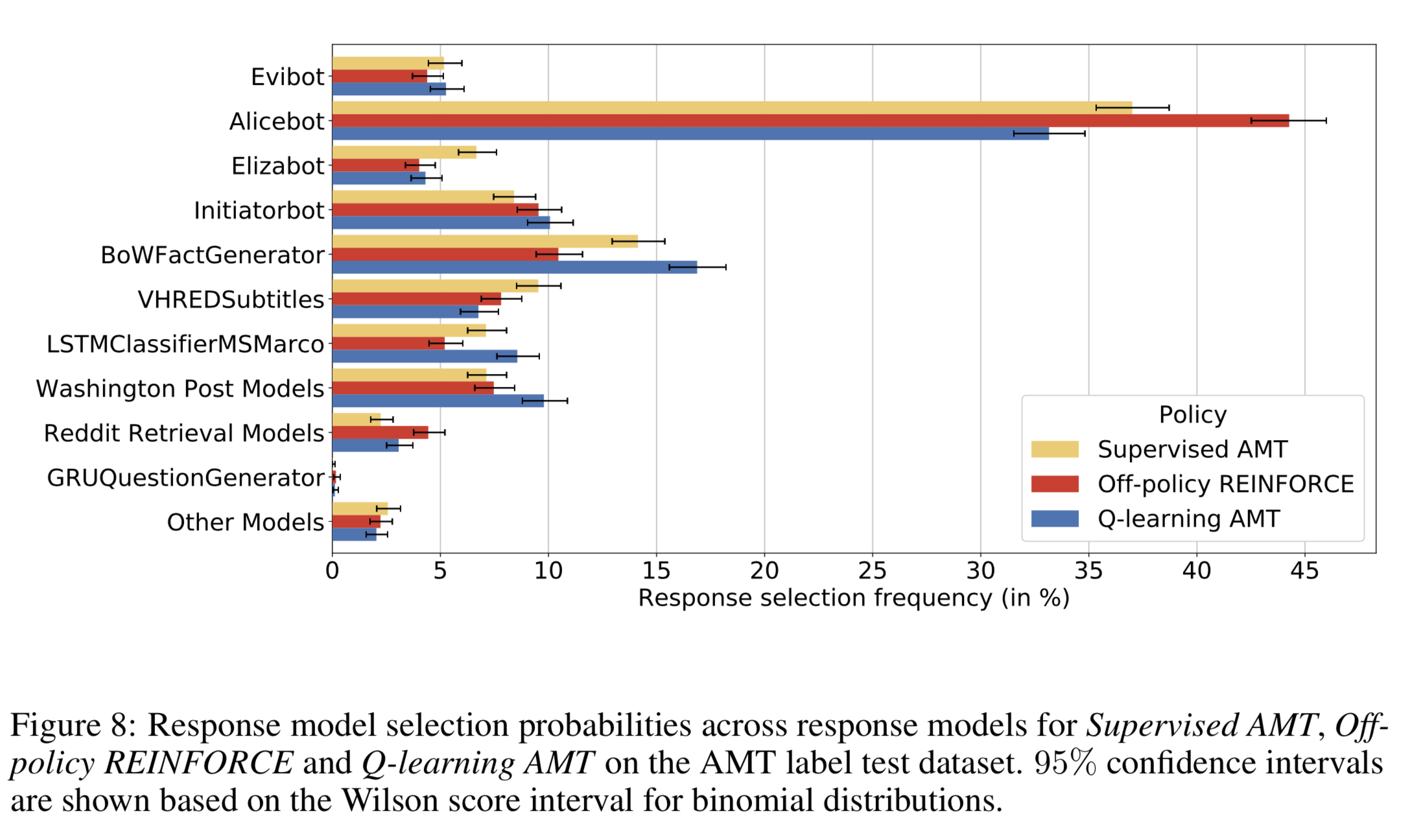
2017 Amazon Alexa Prize competition에 참가한 팀. 22개의 response model로 응답을 만든 뒤, response selection policy로 가장 적절한 응답을 선택했다. 응답 선택 모델은 AMT에서 수집한 데이터로 학습한 MLP, REINFORCE을 변형한 Off-policy REINFORCE, Abstract Discourse MDP를 이용한 Q-learning 등을 실험했다.
https://www.youtube.com/watch?v=aUwJKCMdqmo
-
Process
- Sponsored & unsponsored teams
- First customer feedback period
- Semifinals
- Final customer feedback period
-
2017 result : https://developer.amazon.com/alexaprize/2017-alexa-prize
-
2018 competition began : https://developer.amazon.com/alexaprize
- Alicebot : www.alicebot.org API
- Elizabot : Eliza system, designed to mimic a Rogerian psychotherapist.
- Initiatorbot : 40 question phrases. "What did you do today?", "Do you have pets?", "Did you know that ?"
- Storybot : if a user requests a story
- "Alright, let me tell you the story <story_title> <story_body> by <story_author>".
- request word (e.g. say, tell.) and story-type word in the utterance (e.g. story, tale)
- www.english-for-students.com
- Evibot : Amazon’s question-answering web-service Evi: www.evi.com. handle factual questions.
- BoWMovies : template-based response model, which handles questions in the movie domain.
- entity names and tags (e.g. movie plot and release year)
- uses word embeddings to match tags
- VHRED models : A Hierarchical Latent Variable Encoder-Decoder Model for Generating Dialogues
- 6 variants
- SkipThought Vector Models
- semantic relatedness score
- compares the user’s last utterance to a set of trigger phrases
- 315 trigger phrases
- 35 response sets.
- If the model did not find a match in the first step, the model selects its response from among all Reddit dataset responses
- Dual Encoder Models
- two sequence encoders ENC_Q and ENC_R
- encode the dialogue history and a candidate response
- 2 variants
- Bag-of-words Retrieval Models
- bag-of-words retrieval models based on TF-IDF Glove word embeddings and Word2Vec embeddings
- retrieve the response with the highest cosine similarity.
- BoWWashingtonPost, BoWTrump, BoWFactGenerator, BoWGameofThrones
- 35 topic-independent, generic pre-defined responses
- logistic regression classifier to select its response based on a set of higher-level features.
- "Could you repeat that again", "I don’t know" and "Was that a question?"
- LSTMClassifierMSMarco
- searches the web
- retrieves the first 10 search snippets
- bidirectional LSTM to embed the last dialogue utterance and the snippet
- concatenated and passed through an MLP
- predict a scalar-value between 0 − 1 indicating how appropriate the snippet is as a response
- classifier trained on Microsoft Marco dataset
- GRUQuestion- Generator
- two GRU layers
- generate follow-up questions


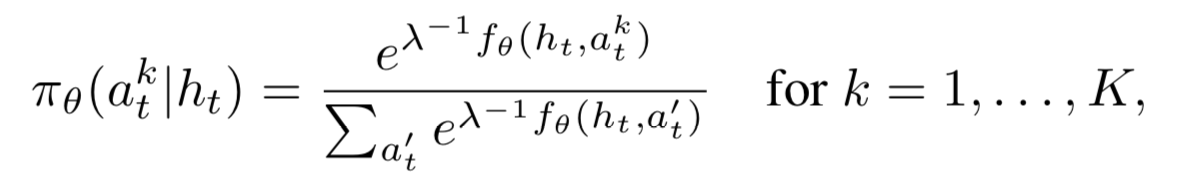
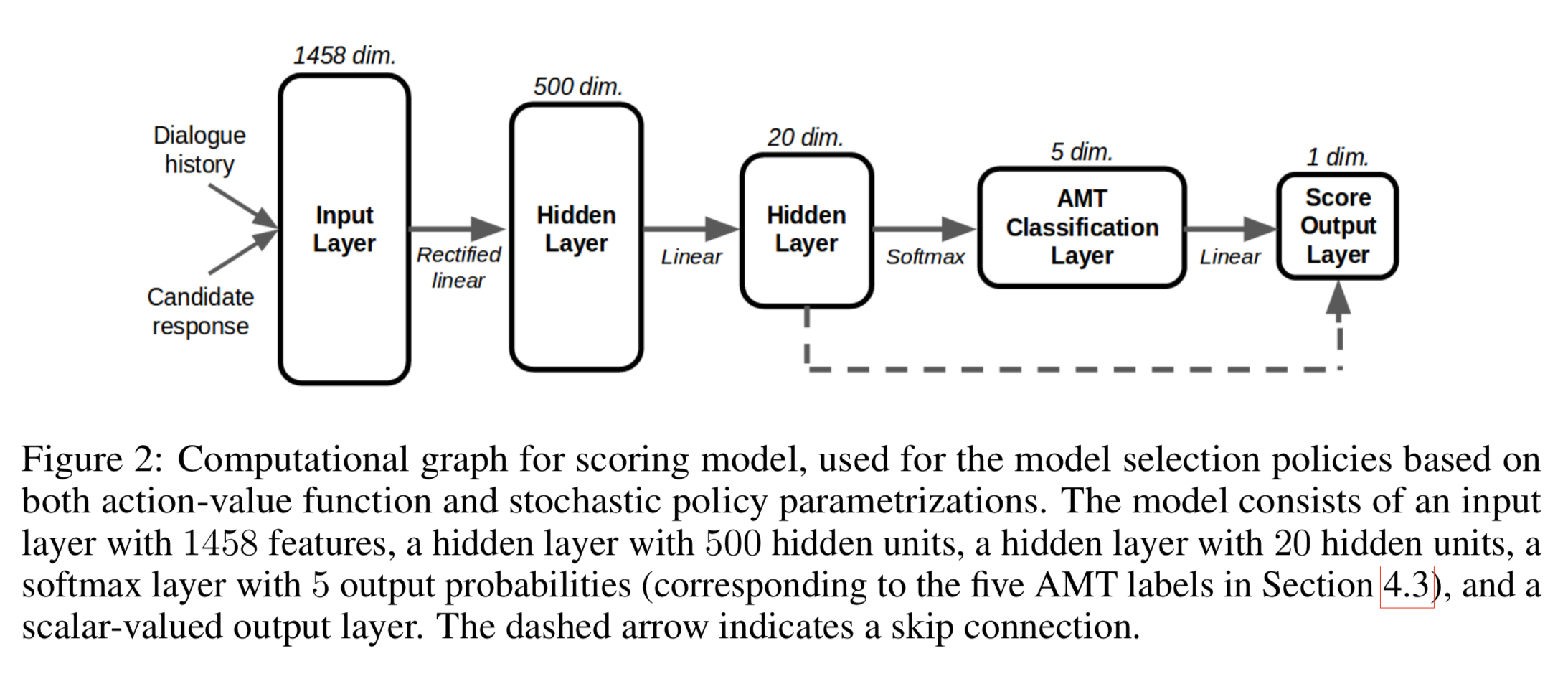
both scoring model Q, f have the same parametrization
1458 features based on the given dialogue history
- combination of word embeddings : Average of the word embeddings
- dialogue acts
- part-of-speech tags
- unigram word overlap : 1.0 when one or more non-stop-words overlap between candidate response and last user utterance
- bigram word overlap
- model-specific features
- No RNN
-
Amazon Mechanical Turk (AMT)
-
collected 199, 678 labels.
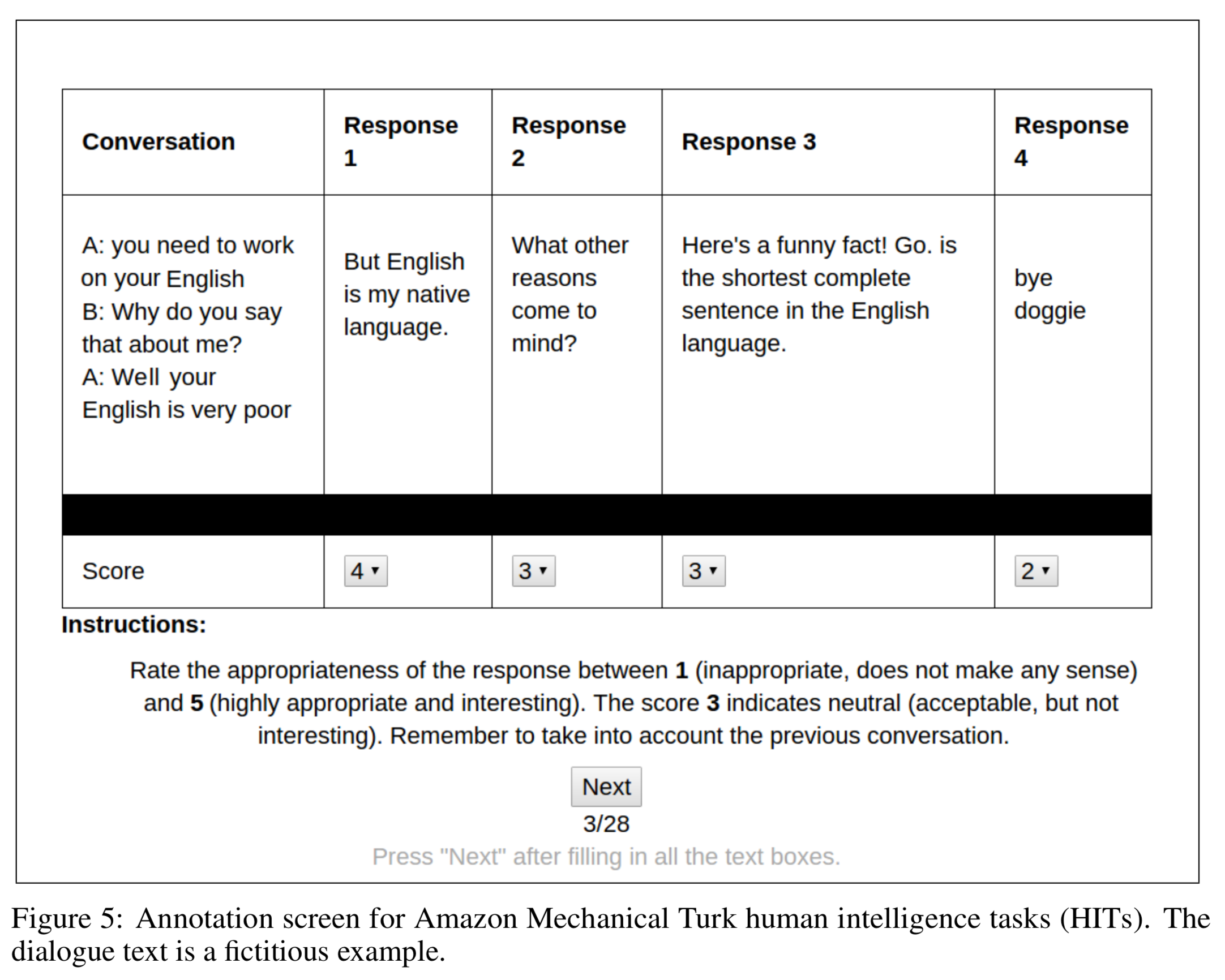
-
not clear whether AMt score is correlated with scores given by real-world Alexa users
-
learning to predict the Alexa user scores based on previously recorded dialogues.
-
linear regression
-
23 features
- AMT label class
- Generic response
- Response length
- Dialogue act (request, a question, a statement or contains profanity)
- Sentiment class
- Generic user utterance
- User utterance length
- Confusion indicator
- Dialogue length
-
As training data is scarce, we use only higher-level features
-
4340 dialogues

first initialize the model with the parameters of the Supervised AMT scoring model, and then fine-tune it with the reward model outputs
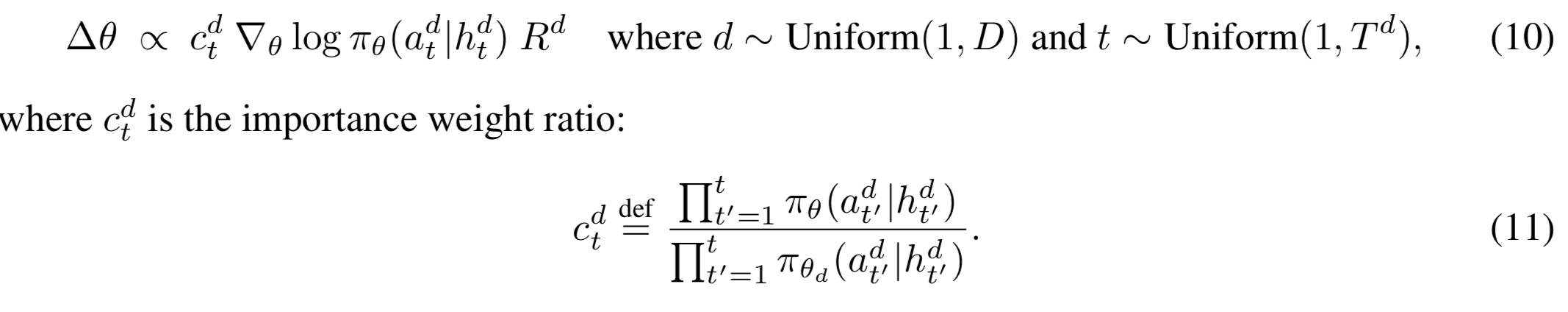

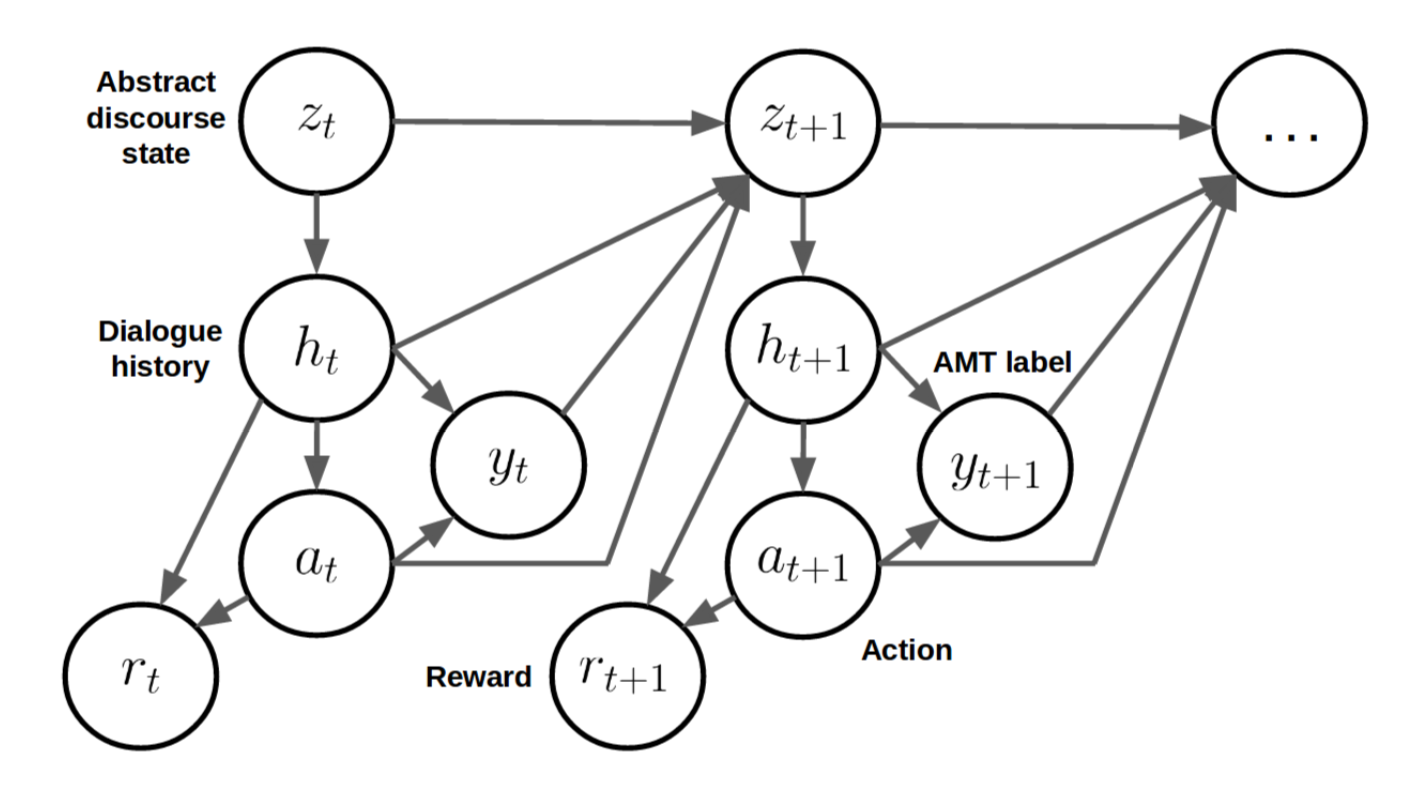



-
Z = ZDialogue act × ZUser sentiment × ZGeneric user utterance
-
Dialogue act : {Accept, Reject, Request, Politics, Generic Question, Personal Question, Statement, Greeting, Goodbye,Other}.
-
The transition distribution is parametrized by three independent two-layer MLP models, which take as input the same features as the scoring function
-
has the potential to learn to take into account future states of the dialogue when selecting its action. This is in contrast to policies learned using supervised learning, which do not consider future dialogue states.