比赛名称: 第四届工业大数据创新竞赛-赛题二 注塑成型工艺的虚拟量测
比赛链接: http://www.industrial-bigdata.com/Title
代码链接: https://github.com/chuangwang1991/VirtualMeasurement_molding
比赛类型: 结构化,时序,回归
关键词: 工业大数据,虚拟量测,智能制造
比赛概况: 该比赛由中国信息通讯研究院和深圳宝安区人民政府联合主办,注塑机赛题共870余只参赛队伍,最终该算法得分排名第5,决赛总排名第5。
由于注塑成型系统较为复杂并且对环境较为敏感,注塑成型加工过程中的不稳定因素很容易导致产品不良的发生,造成经济损失。所以我们建立注塑成型大数据,来感知这些不可见的干扰因素,然后通过分析建模解决甚至避免现场痛点问题。比如成型过程的异常检测预警及不良品的识别,有助于减少甚至避免不合格品的产生,对于管控产品质量、降低生产成本有重要的作用。
我们团队为Micro_i,上海微亿智造,一家致力于通过大数据和人工智能技术帮助制造企业实现智能化改造。
- 队员 王闯,2017年上海交大硕士毕业,进入吉利汽车研究院从事流体力学仿真、CAE二次开发及数据分析工作,2020年初加入微亿智造从事机器学习算法工作;
- 队员 顾徐波,2020年上海交通大学硕士毕业,加入微亿智造从事算法工作,MIT PhD student gap year, 研究方向为AI for Nuclear Engineering;
- 队员 宋怡然,2020年上海交通大学本科毕业,美国北卡教堂山分校生物统计硕士gap year,于2020年加入微亿智造从事机器学习和深度学习算法。
本次注塑成型虚拟量测任务,主要是对注塑产品的尺寸进行预测,尤其是准确预测出尺寸超规产品,考察选手对于工艺参数、时序传感器数据理解及处理,评分标准为官方定义函数,评分规则根据预测值与实际值偏差,偏差越小,惩罚分数越低,最分评分数值越小说明预测结果越准确。
我们最终方案选择模型Lightgbm,数据缺失情况不严重,因此对数据中缺失及单一值进行删除,特征构造整体思路是充分利用官方所提供数据,并创建部分衍生特征来提高预测精度,特征创建部分,因为机台工艺参数仅在参数变化时记录,条目较少,无法反应尺寸波动情况,因此利用这部分数据对其他生产数据进行工况划分和打标,传感器高频数据尝试过按照工艺段抽取上千维特征,但模型过拟合较严重,最终对传感器高频数据只取均值,鲁棒性较强,并将训练集中的尺寸中位数作为输入特征,之后对于特性根据重要性和分布筛选,从500多维特征中进行筛选,最终使用22维特征。
最终初赛得分,total:2.872543877e+04; size1:2.264462354e+04; size2:4.407043113e+03; size3:1.673772117e+03
最终决赛得分,total:3.132480968e+04; size1:7.591678629e+03; size2:1.837020916e+04; size3:5.362921897e+03





根据机台工艺参数创建调机段标识Id,对其他数据进行打标分组,创建Id_len表示调机段的生产模次,另尝试创建一个特征,表示对应模次产品与调机记录的距离,因为通常在调机刚开始或结束时可能会出现尺寸较明显波动,但该特征最终效果不佳;
对尺寸数据,根据调机段分组后取出不同调机段尺寸中位数,均值,特定百分位数值(1/4,3/4等),极值,经过测试后选择鲁棒性最强的中位数特征,这个特征对于结果稳定性和精度提升显著,尺寸中位数特征在测试集会有部分缺失,尝试过使用SVR,和其他模型对不同调机段中位数预测,但效果不佳,最终测试集中仍有部分该特征缺失,如若能找到较好的方法预测填充测试集中尺寸中位数的缺失值,相信对于分数和实际部署都会对模型有进一步提升;
对高频传感器数据,曾尝试使用tsfresh对不同工艺段的均值,峰度,极值,标准差等,共提取各个工艺阶段特征1000多维参数,再次基础上尝试过多个模型stacking融合,发现使用此类特征会容易产生过拟合,因此最后只对高频数据取均值处理,最终也能够找到较有效特征,从一定程度也能说明,产品尺寸对于多数传感器数据波动并不敏感。 之后在答辩中,发现前几名只对保压,冷却等重点阶段做特征提取,能够发现较好的特征,因此可能是我之前做法抽取特征过多,筛选过程做的不好所致;
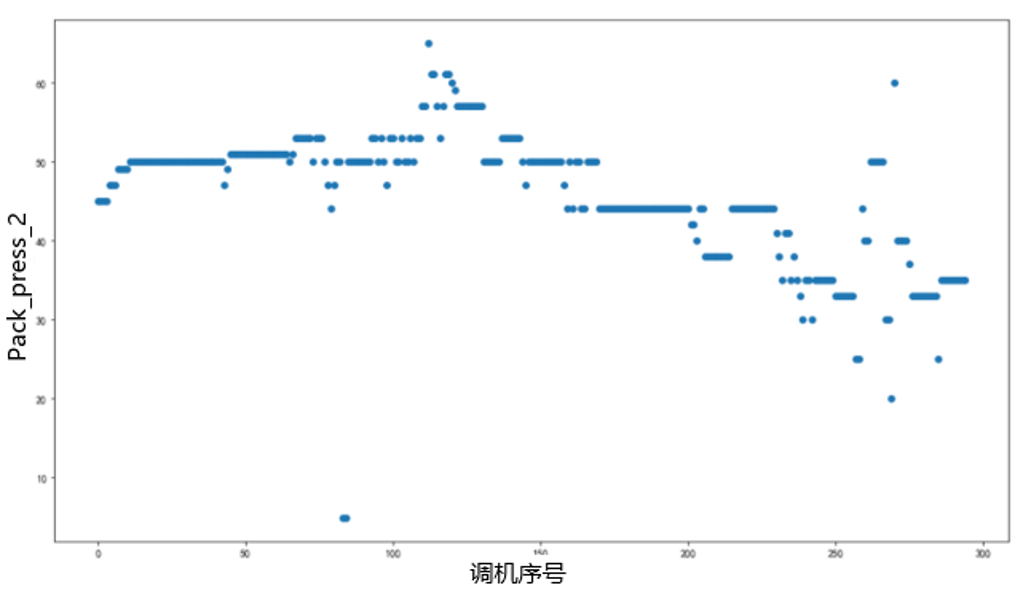
特征筛选,在早期上千维特征时,特征先使用重要性和基于模型重要性方法筛选,最终方案因为特征较少,使用筛选方法为重要性和分布性方法,即先删除特征重要性低的特征,再删除测试集和训练集上特征分布差异大的特征,如下图中我们就保留了sensor1_mean特征而删除pack_press_2,尽管我们发现pack_press_2从实际生产角度和相关性角度都非常重要,分布性筛选可以提高模型在测试集的泛化能力,因此对于分数提升非常重要。


对于最终选择的22列特征,使用lgbm单模型即可得e4量级得分,使用模型融合时,对尺寸中位数特征缺失值使用前值填充,分数从e4次方恶化至e6,出现了过拟合,最终选择单模型。
另外尝试过使用多个模型对同一尺寸分段预测,因为训练数据中尺寸超规主要集中在Id在80000多的产品,因此对该段单独建模,对于size3分数由e4提高至e3。
由于线上测试集得分波动较大,在做local cv时除了考虑mse,和自定义函数得分之外,也需要关注预测结果的分布情况是否合理。

之前从事流体仿真分析工作三年,对工程研发过程和需求有一定了解,接触机器学习半年有余,发现这两个工作其实有很多逻辑相同的地方,流体仿真是我们通过已经建立好的数学物理方程来预测不同工况输入下流场情况,对不同情况使用不同湍流模型,预测结果准确性取决于湍流模型中是否考虑到了所预测问题中关键流动过程,而机器学习(有监督学习)则更多是先通过数学方法建立输入数据和输出之间的映射(即模型训练过程),之后通过所建立的映射关系去预测新的情况,预测结果是否准确,泛化能力是否强,取决于训练的映射关系是否考虑到了测试工况会出现的种种可能。在制造业中往往对于分析方法的可解释性有强烈需求,算法可解释意味着预测结果的风险和局限性可以被工程师评估,如何将机器学习像流体仿真一样在制造业广泛应用从而实现更高效的研发、设计和生产,道阻且长,吾将上下而求索。 第一次写比赛分享,有不足和理解有误之处还请各位大佬多多包涵,批评指正。