FLGo is a library to conduct experiments about Federated Learning (FL). It is strong and reusable for research on FL, providing comprehensive easy-to-use modules to hold out for those who want to do various federated learning experiments.
- Install FLGo through pip. It's recommended to install pytorch by yourself before installing this library.
pip install flgo --upgrade- Install FLGo through git
git clone https://github.com/WwZzz/easyFL.gitWelcome to our FLGo's WeChat group/QQ Group for more technical discussion.

Group Number: 838298386
Tutorials in Chinese can be found here
[2024.9.20] We present a comprehensive benchmark gallery here
[2024.8.01] Improving efficiency by sharing datasets across multiple processes within each task in the shared memory
import flgo
import flgo.benchmark.mnist_classification as mnist
import flgo.benchmark.partition as fbp
import flgo.algorithm.fedavg as fedavg
# Line 1: Create a typical federated learning task
flgo.gen_task_by_(mnist, fbp.IIDPartitioner(num_clients=100), './my_task')
# Line 2: Running FedAvg on this task
fedavg_runner = flgo.init('./my_task', fedavg, {'gpu': [0,], 'num_rounds':20, 'num_epochs': 1})
# Line 3: Start Training
fedavg_runner.run()We take a classical federated dataset, Federated MNIST, as the example. The MNIST dataset is splitted into 100 parts identically and independently.
Line 1 creates the federated dataset as ./my_task and visualizes it in ./my_task/res.png

Lines 2 and 3 start the training procedure and outputs information to the console
2024-04-15 02:30:43,763 fflow.py init [line:642] INFO PROCESS ID: 552206
2024-04-15 02:30:43,763 fflow.py init [line:643] INFO Initializing devices: cuda:0 will be used for this running.
2024-04-15 02:30:43,763 fflow.py init [line:646] INFO BENCHMARK: flgo.benchmark.mnist_classification
2024-04-15 02:30:43,763 fflow.py init [line:647] INFO TASK: ./my_task
2024-04-15 02:30:43,763 fflow.py init [line:648] INFO MODEL: flgo.benchmark.mnist_classification.model.cnn
2024-04-15 02:30:43,763 fflow.py init [line:649] INFO ALGORITHM: fedavg
2024-04-15 02:30:43,774 fflow.py init [line:688] INFO SCENE: horizontal FL with 1 <class 'flgo.algorithm.fedbase.BasicServer'>, 100 <class 'flgo.algorithm.fedbase.BasicClient'>
2024-04-15 02:30:47,851 fflow.py init [line:705] INFO SIMULATOR: <class 'flgo.simulator.default_simulator.Simulator'>
2024-04-15 02:30:47,853 fflow.py init [line:718] INFO Ready to start.
...
2024-04-15 02:30:52,466 fedbase.py run [line:253] INFO --------------Round 1--------------
2024-04-15 02:30:52,466 simple_logger.py log_once [line:14] INFO Current_time:1
2024-04-15 02:30:54,402 simple_logger.py log_once [line:28] INFO test_accuracy 0.6534
2024-04-15 02:30:54,402 simple_logger.py log_once [line:28] INFO test_loss 1.5835
...
- Show Training Result (optional)
import flgo.experiment.analyzer as fea
# Create the analysis plan
analysis_plan = {
'Selector':{'task': './my_task', 'header':['fedavg',], },
'Painter':{'Curve':[{'args':{'x':'communication_round', 'y':'val_loss'}}]},
}
fea.show(analysis_plan)Each training result will be saved as a record under ./my_task/record. We can use the built-in analyzer to read and show it.

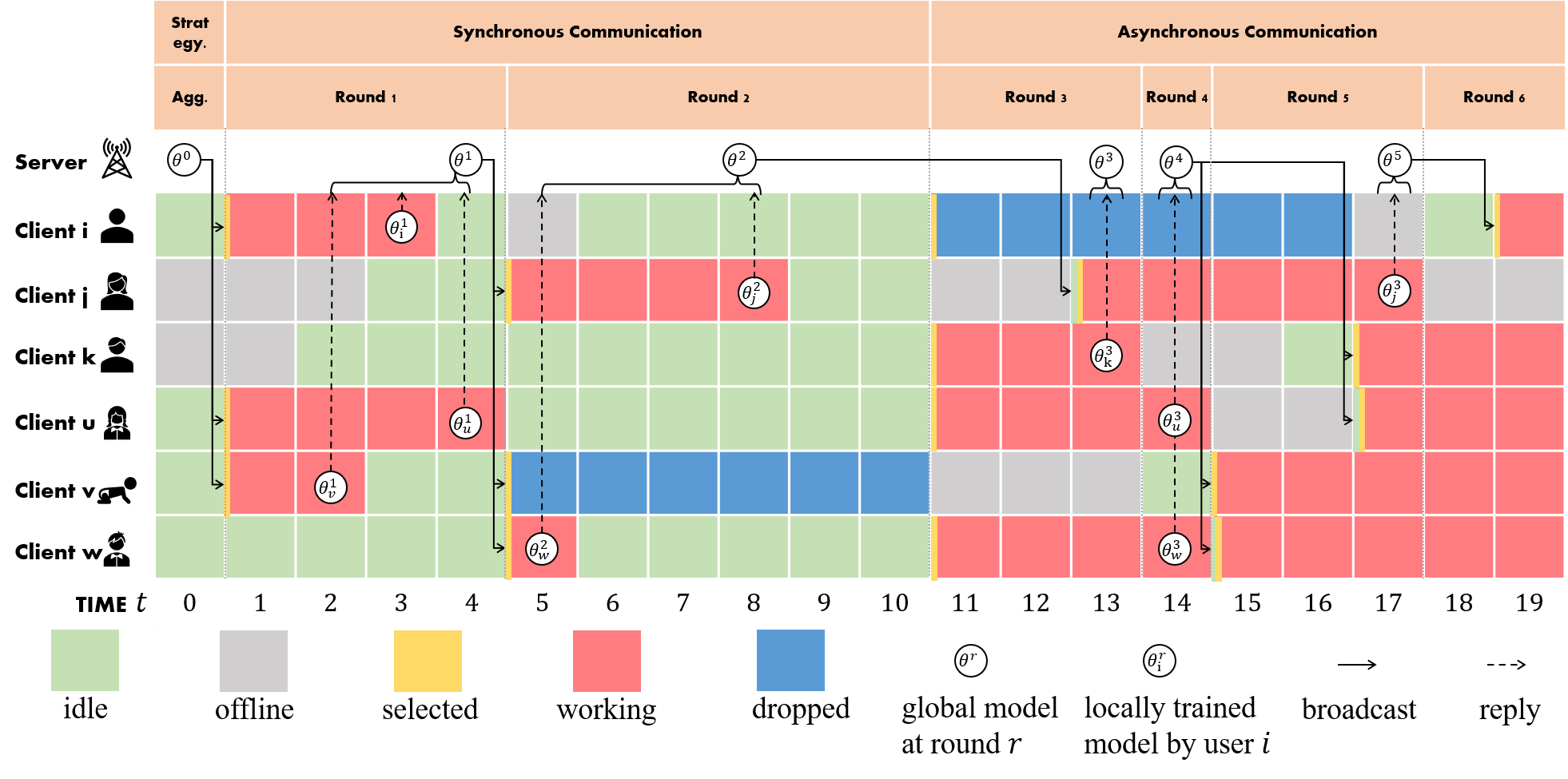 Our FLGo supports running different algorithms in virtual environments like real-world. For example, clients in practice may
Our FLGo supports running different algorithms in virtual environments like real-world. For example, clients in practice may
- be sometime inavailable,
- response to the server very slow,
- accidiently lose connection,
- upload incomplete model updates,
- ...
All of these behavior can be easily realized by integrating a simple Simulator to the runner like
import flgo
from flgo.simulator import ExampleSimulator
import flgo.algorithm.fedavg as fedavg
fedavg_runner = flgo.init('./my_task', fedavg, {'gpu': [0,]}, simulator=ExampleSimulator)
fedavg_runner.run()Simulator is fully customizable and can fairly reflect the impact of system heterogeneity on different algorithms. Please refer to Paper or Tutorial for more details.
FLGo provides more than 50 benchmarks across different data types, different communication topology,...
| Task | Scenario | Datasets | ||
| CV | Classification | Horizontal & Vertical | CIFAR10\100, MNIST, FashionMNIST,FEMNIST, EMNIST, SVHN | |
| Detection | Horizontal | Coco, VOC | ||
| Segmentation | Horizontal | Coco, SBDataset | ||
| NLP | Classification | Horizontal | Sentiment140, AG_NEWS, sst2 | |
| Text Prediction | Horizontal | Shakespeare, Reddit | ||
| Translation | Horizontal | Multi30k | ||
| Graph | Node Classification | Horizontal | Cora, Citeseer, Pubmed | |
| Link Prediction | Horizontal | Cora, Citeseer, Pubmed | ||
| Graph Classification | Horizontal | Enzymes, Mutag | ||
| Recommendation | Rating Prediction | Horizontal & Vertical | Ciao, Movielens, Epinions, Filmtrust, Douban | |
| Series | Time series forecasting | Horizontal | Electricity, Exchange Rate | |
| Tabular | Classification | Horizontal | Adult, Bank Marketing | |
| Synthetic | Regression | Horizontal | Synthetic, DistributedQP, CUBE |
Each benchmark can be used to generate federated tasks that denote distributed scenes with specific data distributions like
import flgo
import flgo.benchmark.cifar10_classification as cifar10
import flgo.benchmark.partition as fbp
import flgo.algorithm.fedavg as fedavg
task = './my_first_cifar' # task name
flgo.gen_task_by_(cifar10, fbp.IIDPartitioner(num_clients=10), task) # generate task from benchmark with partitioner
flgo.init(task, fedavg, {'gpu':0}).run()We realize data heterogeneity by flexible partitioners. These partitioners can be easily combined with benchmark to generate federated tasks with different data distributions.
import flgo.benchmark.cifar10_classification as cifar10
import flgo.benchmark.partition as fbpflgo.gen_task_by_(cifar10, fbp.DirichletPartitioner(num_clients=100, alpha=0.1), 'dir0.1_cifar')
flgo.gen_task_by_(cifar10, fbp.DirichletPartitioner(num_clients=100, alpha=1.0), 'dir1.0_cifar')
flgo.gen_task_by_(cifar10, fbp.DirichletPartitioner(num_clients=100, alpha=5.0), 'dir5.0_cifar')
flgo.gen_task_by_(cifar10, fbp.DirichletPartitioner(num_clients=100, alpha=10.0), 'dir10.0_cifar')
# set imbalance=0.1, 0.3, 0.6 or 1.0
flgo.gen_task_by_(cifar10, fbp.DirichletPartitioner(num_clients=100, alpha=1.0, imbalance=0.1), 'dir1.0_cifar_imb0.1')
flgo.gen_task_by_(cifar10, fbp.DirichletPartitioner(num_clients=100, alpha=1.0, imbalance=0.3), 'dir1.0_cifar_imb0.3')
flgo.gen_task_by_(cifar10, fbp.DirichletPartitioner(num_clients=100, alpha=1.0, imbalance=0.6), 'dir1.0_cifar_imb0.6')
flgo.gen_task_by_(cifar10, fbp.DirichletPartitioner(num_clients=100, alpha=1.0, imbalance=1.0), 'dir1.0_cifar_imb1.0')
flgo.gen_task_by_(cifar10, fbp.DiversityPartitioner(num_clients=100, diversity=0.1), 'div0.1_cifar')
flgo.gen_task_by_(cifar10, fbp.DiversityPartitioner(num_clients=100, diversity=0.3), 'div0.3_cifar')
flgo.gen_task_by_(cifar10, fbp.DiversityPartitioner(num_clients=100, diversity=0.6), 'div0.6_cifar')
flgo.gen_task_by_(cifar10, fbp.DiversityPartitioner(num_clients=100, diversity=1.0), 'div1.0_cifar')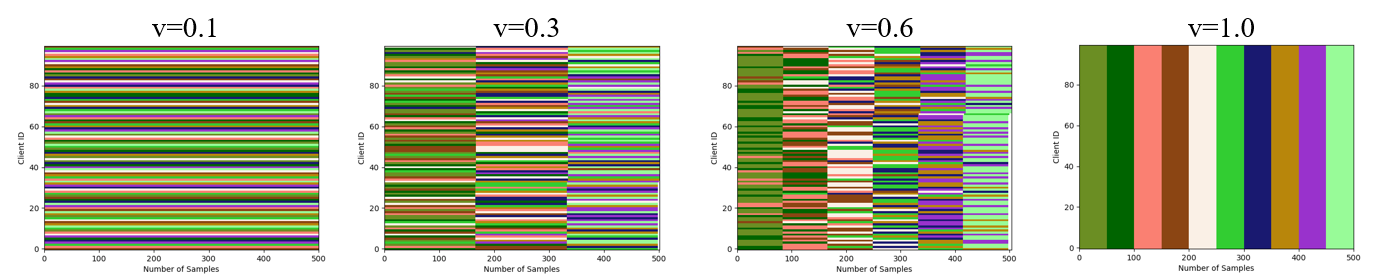
Partitioner is also customizable in flgo. We have provided a detailed example in this Tutorial.
We have realized more than 50 algorithms from TOP-tiers and Journals. The algorithms are listed as below
| Method | Reference | Publication |
|---|---|---|
| FedAvg | link | AISTAS2017 |
| FedProx | link | MLSys 2020 |
| Scaffold | link | ICML 2020 |
| FedDyn | link | ICLR 2021 |
| MOON | link | CVPR 2021 |
| FedNova | link | NIPS 2021 |
| FedAvgM | link | arxiv |
| GradMA | link | CVPR 2023 |
| Method | Reference | Publication |
|---|---|---|
| Standalone | link | - |
| FedAvg+FineTune | - | - |
| Ditto | link | ICML 2021 |
| FedALA | link | AAAI 2023 |
| FedRep | link | ICML 2021 |
| pFedMe | link | NIPS 2020 |
| Per-FedAvg | link | NIPS 2020 |
| FedAMP | link | AAAI 2021 |
| FedFomo | link | ICLR 2021 |
| LG-FedAvg | link | NIPS 2019 workshop |
| pFedHN | link | ICML 2021 |
| Fed-ROD | link | ICLR 2023 |
| FedPAC | link | ICLR 2023 |
| FedPer | link | AISTATS 2020 |
| APPLE | link | IJCAI 2022 |
| FedBABU | link | ICLR 2022 |
| FedBN | link | ICLR 2021 |
| FedPHP | link | ECML/PKDD 2021 |
| APFL | link | arxiv |
| FedProto | link | AAAI 2022 |
| FedCP | link | KDD 2023 |
| GPFL | link | ICCV 2023 |
| pFedPara | link | ICLR 2022 |
| FedFA | link | ICLR 2023 |
| Method | Reference | Publication |
|---|---|---|
| AFL | link | ICML 2019 |
| FedFv | link | IJCAI 2021 |
| FedFa | link | Information Sciences 2022 |
| FedMgda+ | link | IEEE TNSE 2022 |
| QFedAvg | link | ICLR 2020 |
| Method | Reference | Publication |
|---|---|---|
| FedAsync | link | arxiv |
| FedBuff | link | AISTATS 2022 |
| CA2FL | link | ICLR2024 |
| Method | Reference | Publication |
|---|---|---|
| MIFA | link | NeurIPS 2021 |
| PowerofChoice | link | arxiv |
| FedGS | link | AAAI 2023 |
| ClusteredSampling | link | ICML 2021 |
| Method | Reference | Publication |
|---|---|---|
| FederatedDropout | link | arxiv |
| FedRolex | link | NIPS 2022 |
| Fjord | link | NIPS 2021 |
| FLANC | link | NIPS 2022 |
| Hermes | link | MobiCom 2021 |
| FedMask | link | SenSys 2021 |
| LotteryFL | link | arxiv |
| HeteroFL | link | ICLR 2021 |
| TailorFL | link | SenSys 2022 |
| pFedGate | link | ICML 2023 |

FLGo supports flexible combinations of benchmarks, partitioners, algorithms and simulators , which are independent to each other and thus can be used like plugins. We have provided these plugins here , where each can be immediately downloaded and used by API
import flgo
import flgo.benchmark.partition as fbp
fedavg = flgo.download_resource(root='.', name='fedavg', type='algorithm')
mnist = flgo.download_resource(root='.', name='mnist_classification', type='benchmark')
task = 'test_down_mnist'
flgo.gen_task_by_(mnist,fbp.IIDPartitioner(num_clients=10,), task_path=task)
flgo.init(task, fedavg, {'gpu':0}).run()Each runned result will be automatically saved in task_path/record/. We provide an API to easily load and filter records.
import flgo
import flgo.experiment.analyzer as fea
import matplotlib.pyplot as plt
res = fea.Selector({'task': './my_task', 'header':['fedavg',], },)
log_data = res.records['./my_task'][0].data
val_loss = log_data['val_loss']
plt.plot(list(range(len(val_loss))), val_loss)
plt.show()import flgo.algorithm.fedavg as fedavg
import flgo.experiment.analyzer
task = './my_task'
ckpt = '1'
runner = flgo.init(task, fedavg, {'gpu':[0,],'log_file':True, 'num_epochs':1, 'save_checkpoint':ckpt, 'load_checkpoint':ckpt})
runner.run()We save each checkpoint at task_path/checkpoint/checkpoint_name/. By specifying the name of checkpoints, the training can be automatically recovered from them.
import flgo.algorithm.fedavg as fedavg
# the two methods need to be extended when using other algorithms
class Server(fedavg.Server):
def save_checkpoint(self):
cpt = {
'round': self.current_round, # current communication round
'learning_rate': self.learning_rate, # learning rate
'model_state_dict': self.model.state_dict(), # model
'early_stop_option': { # early stop option
'_es_best_score': self.gv.logger._es_best_score,
'_es_best_round': self.gv.logger._es_best_round,
'_es_patience': self.gv.logger._es_patience,
},
'output': self.gv.logger.output, # recorded information by Logger
'time': self.gv.clock.current_time, # virtual time
}
return cpt
def load_checkpoint(self, cpt):
md = cpt.get('model_state_dict', None)
round = cpt.get('round', None)
output = cpt.get('output', None)
early_stop_option = cpt.get('early_stop_option', None)
time = cpt.get('time', None)
learning_rate = cpt.get('learning_rate', None)
if md is not None: self.model.load_state_dict(md)
if round is not None: self.current_round = round + 1
if output is not None: self.gv.logger.output = output
if time is not None: self.gv.clock.set_time(time)
if learning_rate is not None: self.learning_rate = learning_rate
if early_stop_option is not None:
self.gv.logger._es_best_score = early_stop_option['_es_best_score']
self.gv.logger._es_best_round = early_stop_option['_es_best_round']
self.gv.logger._es_patience = early_stop_option['_es_patience']Note: different FL algorithms need to save different types of checkpoints. Here we only provide checkpoint save&load mechanism of FedAvg. We remain two APIs for customization above:
We show how to use customized Logger Here
We have provided comprehensive Tutorials and Document for FLGo.
Our FLGo is able to be extended to real-world application. We provide a simple Example to show how to run FLGo on multiple machines.
Basic options:
-
taskis to choose the task of splited dataset. Options: name of fedtask (e.g.mnist_classification_client100_dist0_beta0_noise0). -
algorithmis to choose the FL algorithm. Options:fedfv,fedavg,fedprox, … -
modelshould be the corresponding model of the dataset. Options:mlp,cnn,resnet18.
Server-side options:
-
sampledecides the way to sample clients in each round. Options:uniformmeans uniformly,mdmeans choosing with probability. -
aggregatedecides the way to aggregate clients' model. Options:uniform,weighted_scale,weighted_com -
num_roundsis the number of communication rounds. -
proportionis the proportion of clients to be selected in each round. -
lr_scheduleris the global learning rate scheduler. -
learning_rate_decayis the decay rate of the learning rate.
Client-side options:
-
num_epochsis the number of local training epochs. -
num_stepsis the number of local updating steps and the default value is -1. If this term is set larger than 0,num_epochsis not valid. -
learning_rateis the step size when locally training. -
batch_sizeis the size of one batch data during local training.batch_size = full_batchifbatch_size==-1andbatch_size=|Di|*batch_sizeif1>batch_size>0. -
optimizeris to choose the optimizer. Options:SGD,Adam. -
weight_decayis to set ratio for weight decay during the local training process. -
momentumis the ratio of the momentum item when the optimizer SGD taking each step.
Real Machine-Dependent options:
-
seedis the initial random seed. -
gpuis the id of the GPU device. (e.g. CPU is used without specifying this term.--gpu 0will use device GPU 0, and--gpu 0 1 2 3will use the specified 4 GPUs whennum_threads>0. -
server_with_cpuis set False as default value,.. -
test_batch_sizeis the batch_size used when evaluating models on validation datasets, which is limited by the free space of the used device. -
eval_intervalcontrols the interval between every two evaluations. -
num_threadsis the number of threads in the clients computing session that aims to accelerate the training process. -
num_workersis the number of workers of the torch.utils.data.Dataloader
Additional hyper-parameters for particular federated algorithms:
algo_parais used to receive the algorithm-dependent hyper-parameters from command lines. Usage: 1) The hyper-parameter will be set as the default value defined in Server.init() if not specifying this term, 2) For algorithms with one or more parameters, use--algo_para v1 v2 ...to specify the values for the parameters. The input order depends on the dictServer.algo_paradefined inServer.__init__().
Logger's setting
-
loggeris used to selected the logger that has the same name with this term. -
log_levelshares the same meaning with the LEVEL in the python's native module logging. -
log_filecontrols whether to store the running-time information into.loginfedtask/taskname/log/, default value is false. -
no_log_consolecontrols whether to show the running time information on the console, and default value is false.
To get more information and full-understanding of FLGo please refer to our website.
In the website, we offer :
- API docs: Detailed introduction of packages, classes and methods.
- Tutorial: Materials that help user to master FLGo.
We seperate the FL system into five parts:algorithm, benchmark, experiment, simulator and utils.
├─ algorithm
│ ├─ fedavg.py //fedavg algorithm
│ ├─ ...
│ ├─ fedasync.py //the base class for asynchronous federated algorithms
│ └─ fedbase.py //the base class for federated algorithms
├─ benchmark
│ ├─ mnist_classification //classification on mnist dataset
│ │ ├─ model //the corresponding model
│ | └─ core.py //the core supporting for the dataset, and each contains three necessary classes(e.g. TaskGen, TaskReader, TaskCalculator)
│ ├─ ...
│ ├─ RAW_DATA // storing the downloaded raw dataset
│ └─ toolkits //the basic tools for generating federated dataset
│ ├─ cv // common federal division on cv
│ │ ├─ horizontal // horizontal fedtask
│ │ │ └─ image_classification.py // the base class for image classification
│ │ └─ ...
│ ├─ ...
│ ├─ base.py // the base class for all fedtask
│ ├─ partition.py // the parttion class for federal division
│ └─ visualization.py // visualization after the data set is divided
├─ experiment
│ ├─ logger //the class that records the experimental process
│ │ ├─ basic_logger.py //the base logger class
│ | └─ simple_logger.py //a simple logger class
│ ├─ analyzer.py //the class for analyzing and printing experimental results
│ ├─ res_config.yml //hyperparameter file of analyzer.py
│ ├─ run_config.yml //hyperparameter file of runner.py
| └─ runner.py //the class for generating experimental commands based on hyperparameter combinations and processor scheduling for all experimental
├─ system_simulator //system heterogeneity simulation module
│ ├─ base.py //the base class for simulate system heterogeneity
│ ├─ default_simulator.py //the default class for simulate system heterogeneity
| └─ ...
├─ utils
│ ├─ fflow.py //option to read, initialize,...
│ └─ fmodule.py //model-level operators
└─ requirements.txt
We have added many benchmarks covering several different areas such as CV, NLP, etc
 This module is the specific federated learning algorithm implementation. Each method contains two classes: the
This module is the specific federated learning algorithm implementation. Each method contains two classes: the Server and the Client.
The whole FL system starts with the main.py, which runs server.run() after initialization. Then the server repeat the method iterate() for num_rounds times, which simulates the communication process in FL. In the iterate(), the BaseServer start with sampling clients by select(), and then exchanges model parameters with them by communicate(), and finally aggregate the different models into a new one with aggregate(). Therefore, anyone who wants to customize its own method that specifies some operations on the server-side should rewrite the method iterate() and particular methods mentioned above.
The clients reponse to the server after the server communicate_with() them, who first unpack() the received package and then train the model with their local dataset by train(). After training the model, the clients pack() send package (e.g. parameters, loss, gradient,... ) to the server through reply().
The experiment module contains experiment command generation and scheduling operation, which can help FL researchers more conveniently conduct experiments in the field of federated learning.
The system_simulator module is used to realize the simulation of heterogeneous systems, and we set multiple states such as network speed and availability to better simulate the system heterogeneity of federated learning parties.
Utils is composed of commonly used operations:
- model-level operation (we convert model layers and parameters to dictionary type and apply it in the whole FL system).
- API for the FL workflow like gen_benchmark, gen_task, init, ...
Please cite our paper in your publications if this code helps your research.
@misc{wang2021federated,
title={Federated Learning with Fair Averaging},
author={Zheng Wang and Xiaoliang Fan and Jianzhong Qi and Chenglu Wen and Cheng Wang and Rongshan Yu},
year={2021},
eprint={2104.14937},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
@misc{wang2023flgo,
title={FLGo: A Fully Customizable Federated Learning Platform},
author={Zheng Wang and Xiaoliang Fan and Zhaopeng Peng and Xueheng Li and Ziqi Yang and Mingkuan Feng and Zhicheng Yang and Xiao Liu and Cheng Wang},
year={2023},
eprint={2306.12079},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
Zheng Wang, [email protected]
Buy me a coffee if you'd like to support the development of this repo.

[Cong Xie. et al., 2019] Cong Xie, Sanmi Koyejo, Indranil Gupta. Asynchronous Federated Optimization.
[John Nguyen. et al., 2022] John Nguyen, Kshitiz Malik, Hongyuan Zhan, Ashkan Yousefpour, Michael Rabbat, Mani Malek, Dzmitry Huba. Federated Learning with Buffered Asynchronous Aggregation. In International Conference on Artificial Intelligence and Statistics (AISTATS), 2022.
[Mehryar Mohri. et al., 2019] Mehryar Mohri, Gary Sivek, Ananda Theertha Suresh. Agnostic Federated Learning.In International Conference on Machine Learning(ICML), 2019
[Zheng Wang. et al., 2021] Zheng Wang, Xiaoliang Fan, Jianzhong Qi, Chenglu Wen, Cheng Wang, Rongshan Yu. Federated Learning with Fair Averaging. In International Joint Conference on Artificial Intelligence, 2021
[Zeou Hu. et al., 2022] Zeou Hu, Kiarash Shaloudegi, Guojun Zhang, Yaoliang Yu. Federated Learning Meets Multi-objective Optimization. In IEEE Transactions on Network Science and Engineering, 2022
[Tian Li. et al., 2020] Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, Virginia Smith. Federated Optimization in Heterogeneous Networks. In Conference on Machine Learning and Systems, 2020
[Xinran Gu. et al., 2021] Xinran Gu, Kaixuan Huang, Jingzhao Zhang, Longbo Huang. Fast Federated Learning in the Presence of Arbitrary Device Unavailability. In Neural Information Processing Systems(NeurIPS), 2021
[Yae Jee Cho. et al., 2020] Yae Jee Cho, Jianyu Wang, Gauri Joshi. Client Selection in Federated Learning: Convergence Analysis and Power-of-Choice Selection Strategies.
[Tian Li. et al., 2020] Tian Li, Maziar Sanjabi, Ahmad Beirami, Virginia Smith. Fair Resource Allocation in Federated Learning. In International Conference on Learning Representations, 2020
[Sai Praneeth Karimireddy. et al., 2020] Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank J. Reddi, Sebastian U. Stich, Ananda Theertha Suresh. SCAFFOLD: Stochastic Controlled Averaging for Federated Learning. In International Conference on Machine Learning, 2020