Building a clone of sqlite from scratch in order to understand how does a database work.
Reading the blog
The SQLite has a documentation for your architecture on their website
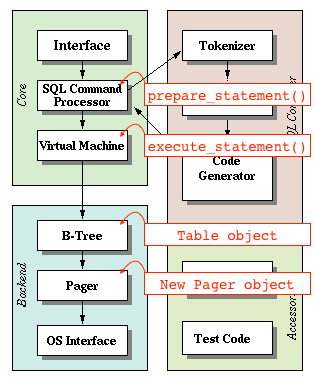
A query goes through a chain of components in order to retrieve or modify data. The front-end consists of the:
- tokenizer
- parser
- code generator
The input to the front-end is a SQL query. the output is sqlite virtual machine bytecode (essentially a compiled program that can operate on the database).
The back-end consists of the:
- virtual machine
- B-tree
- pager
- OS interface
The virtual machine takes bytecode** generated by the front-end as instructions. It can then perform operations on one or more tables or indexes, each of which is stored in a data structure called a B-tree. The VM is essentially a big switch statement on the type of bytecode instruction.
**Bytecode: Bytecode is computer object code that an interpreter converts into binary machine code so it can be read by a computer's hardware processor
Each B-tree consists of many nodes. Each node is one page in length. The B-tree can retrieve a page from disk or save it back to disk by issuing commands to the pager.
The pager receives commands to read or write pages of data. It is responsible for reading/writing at appropriate offsets in the database file. It also keeps a cache of recently-accessed pages in memory, and determines when those pages need to be written back to disk.
The pager receives commands to read or write pages of data. It is responsible for reading/writing at appropriate offsets in the database file. It also keeps a cache of recently-accessed pages in memory, and determines when those pages need to be written back to disk.
We’re making a clone of sqlite. The “front-end” of sqlite is a SQL compiler that parses a string and outputs an internal representation called bytecode.
This bytecode is passed to the virtual machine, which executes it.
Breaking things into two steps like this has a couple advantages:
Reduces the complexity of each part (e.g. virtual machine does not worry about syntax errors) Allows compiling common queries once and caching the bytecode for improved performance
Non-SQL statements like .exit are called “meta-commands”. They all start with a dot, so we check for them and handle them in a separate function.
Next, we add a step that converts the line of input into our internal representation of a statement. This is our hacky version of the sqlite front-end.
Lastly, we pass the prepared statement to execute_statement. This function will eventually become our virtual machine.
We’re going to start small by putting a lot of limitations on our database. For now, it will:
support two operations: inserting a row and printing all rows reside only in memory (no persistence to disk) support a single, hard-coded table
Our hard-coded table is going to store users and look like this:
| column | type |
|---|---|
| id | integer |
| username | varchar(32) |
| varchar(255) |
insert statements are now going to look like this:
insert 1 cstack [email protected]
Now we need to copy that data into some data structure representing the table. SQLite uses a B-tree for fast lookups, inserts and deletes. We’ll start with something simpler. Like a B-tree, it will group rows into pages, but instead of arranging those pages as a tree it will arrange them as an array.
Here’s my plan:
- Store rows in blocks of memory called pages
- Each page stores as many rows as it can fit
- Rows are serialized into a compact representation with each page
- Pages are only allocated as needed
- Keep a fixed-size array of pointers to pages
I’m making our page size 4 kilobytes because it’s the same size as a page used in the virtual memory systems of most computer architectures. This means one page in our database corresponds to one page used by the operating system. The operating system will move pages in and out of memory as whole units instead of breaking them up
I’m setting an arbitrary limit of 100 pages that we will allocate. When we switch to a tree structure, our database’s maximum size will only be limited by the maximum size of a file. (Although we’ll still limit how many pages we keep in memory at once)
Rows should not cross page boundaries. Since pages probably won’t exist next to each other in memory, this assumption makes it easier to read/write rows.
Like sqlite, we’re going to persist records by saving the entire database to a file.
We already set ourselves up to do that by serializing rows into page-sized memory blocks. To add persistence, we can simply write those blocks of memory to a file, and read them back into memory the next time the program starts up
To make this easier, we’re going to make an abstraction called the pager. We ask the pager for page number x, and the pager gives us back a block of memory. It first looks in its cache. On a cache miss, it copies data from disk into memory (by reading the database file).
The get_page() method has the logic for handling a cache miss. We assume pages are saved one after the other in the database file: Page 0 at offset 0, page 1 at offset 4096, page 2 at offset 8192, etc. If the requested page lies outside the bounds of the file, we know it should be blank, so we just allocate some memory and return it. The page will be added to the file when we flush the cache to disk later.
We’ll wait to flush the cache to disk until the user closes the connection to the database. When the user exits, we’ll call a new method called db_close(), which
- flushes the page cache to disk
- closes the database file
- frees the memory for the Pager and Table data structures
In our current design, the length of the file encodes how many rows are in the database, so we need to write a partial page at the end of the file. That’s why pager_flush() takes both a page number and a size. It’s not the greatest design, but it will go away pretty quickly when we start implementing the B-tree.

The first four bytes are the id of the first row (4 bytes because we store a uint32_t). It’s stored in little-endian byte order, so the least significant byte comes first (01), followed by the higher-order bytes (00 00 00). We used memcpy() to copy bytes from our Row struct into the page cache, so that means the struct was laid out in memory in little-endian byte order. That’s an attribute of the machine I compiled the program for. If we wanted to write a database file on my machine, then read it on a big-endian machine, we’d have to change our serialize_row() and deserialize_row() methods to always store and read bytes in the same order.
NOTE: If we wanted to ensure that all bytes are initialized, it would suffice to use strncpy instead of memcpy while copying the username and email fields of rows in serialize_row, like so:
Conclusion part5:
Alright! We’ve got persistence. It’s not the greatest. For example if you kill the program without typing .exit, you lose your changes. Additionally, we’re writing all pages back to disk, even pages that haven’t changed since we read them from disk. These are issues we can address later.