Create an easy Text Analytics in One-Line-Code
Main Features:
- Load
Excel,CSVandTXTfile types - Stemming
- Lemmatization
- Stopwords
- TD-IDF
- Sentimental Analysis
- Graphical interpretation
- Word Cloud
The TF-IDF was calculated by:

pip install BRWording
pip install pdfminer-sixsintax:
from brwording.brwording import wording
w = brwording.wording()
w.load_file('data/example.txt',type='txt')
w.build_tf_idf(lemmatizer=True,stopwords=True)
w.tfidfThe fields to load_file are:
3. file: the file path
3. type: file type, can be txt csv or excel
3. header: if you are reading a csv file, so you must tell if this file has a header or not (False or True)
0. sep: if you are reading a csv file, you must tell what kind field separator you want
0. column: if you read a csv or excelfile, you must tell what column you want to parse
The method build_tf_idf has a default Trueoption for both parameters.
Output

If want to see the sentimental Graphical interpretation
sintax:
w.sentimental_graf()You can rotate the graph if you pass rotate=True in argument
output
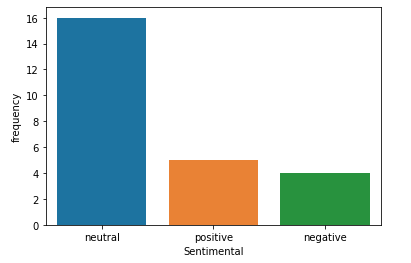
You can print the same information as a table using the follow command:
sintax:
w.sentimental_table()if you want to create a wordcloud, just strike the folowing command, but if you want to create a cloud with your own mask, just pass you image address as picture
sintax:
w.word_cloud(picture='none')output

Looking for a word into colection
if you want to see what files on your colection has a word, run look3word
sintax:
w.look3word('bonito')New features are incoming.
enjoi!