You shouldn't play video games all day, so shouldn't your AI! We built a virtual environment simulator, Gibson, that offers real-world experience for learning perception.

Summary: Perception and being active (i.e. having a certain level of motion freedom) are closely tied. Learning active perception and sensorimotor control in the physical world is cumbersome as existing algorithms are too slow to efficiently learn in real-time and robots are fragile and costly. This has given a fruitful rise to learning in the simulation which consequently casts a question on transferring to real-world. We developed Gibson environment with the following primary characteristics:
I. being from the real-world and reflecting its semantic complexity through virtualizing real spaces,
II. having a baked-in mechanism for transferring to real-world (Goggles function), and
III. embodiment of the agent and making it subject to constraints of space and physics via integrating a physics engine (Bulletphysics).
Naming: Gibson environment is named after James J. Gibson, the author of "Ecological Approach to Visual Perception", 1979. “We must perceive in order to move, but we must also move in order to perceive” – JJ Gibson
Please see the website (http://gibsonenv.stanford.edu/) for more technical details. This repository is intended for distribution of the environment and installation/running instructions.
"Gibson Env: Real-World Perception for Embodied Agents", in CVPR 2018 [Spotlight Oral].

This is the 0.3.1 release. Bug reports, suggestions for improvement, as well as community developments are encouraged and appreciated. change log file.
The full database includes 572 spaces and 1440 floors and can be downloaded here. A diverse set of visualizations of all spaces in Gibson can be seen here. To make the core assets download package lighter for the users, we include a small subset (39) of the spaces. Users can download the rest of the spaces and add them to the assets folder. We also integrated Stanford 2D3DS and Matterport 3D as separate datasets if one wishes to use Gibson's simulator with those datasets (access here).
- Installation
- Quick Start
- Coding your RL agent
- Environment Configuration
- Goggles: transferring the agent to real-world
- Citation
There are two ways to install gibson, A. using our docker image (recommended) and B. building from source.
The minimum system requirements are the following:
For docker installation (A):
- Ubuntu 16.04
- Nvidia GPU with VRAM > 6.0GB
- Nvidia driver >= 384
- CUDA >= 9.0, CuDNN >= v7
For building from the source(B):
- Ubuntu >= 14.04
- Nvidia GPU with VRAM > 6.0GB
- Nvidia driver >= 375
- CUDA >= 8.0, CuDNN >= v5
First, our environment core assets data are available here. You can follow the installation guide below to download and set up them properly. gibson/assets folder stores necessary data (agent models, environments, etc) to run gibson environment. Users can add more environments files into gibson/assets/dataset to run gibson on more environments. Visit the database readme for downloading more spaces. Please sign the license agreement before using Gibson's database.
We use docker to distribute our software, you need to install docker and nvidia-docker2.0 first.
Run docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi to verify your installation.
You can either 1. pull from our docker image (recommended) or 2. build your own docker image.
- Pull from our docker image (recommended)
# download the dataset from https://storage.googleapis.com/gibson_scenes/dataset.tar.gz
docker pull xf1280/gibson:0.3.1
xhost +local:root
docker run --runtime=nvidia -ti --rm -e DISPLAY -v /tmp/.X11-unix:/tmp/.X11-unix -v <host path to dataset folder>:/root/mount/gibson/gibson/assets/dataset xf1280/gibson:0.3.1- Build your own docker image
git clone https://github.com/StanfordVL/GibsonEnv.git
cd GibsonEnv
./download.sh # this script downloads assets data file and decompress it into gibson/assets folder
docker build . -t gibson ### finish building inside docker, note by default, dataset will not be included in the docker images
xhost +local:root ## enable display from dockerIf the installation is successful, you should be able to run docker run --runtime=nvidia -ti --rm -e DISPLAY -v /tmp/.X11-unix:/tmp/.X11-unix -v <host path to dataset folder>:/root/mount/gibson/gibson/assets/dataset gibson to create a container. Note that we don't include
dataset files in docker image to keep our image slim, so you will need to mount it to the container when you start a container.
Gibson Env supports deployment on a headless server and remote access with x11vnc.
You can build your own docker image with the docker file Dockerfile as above.
Instructions to run gibson on a headless server (requires X server running):
- Install nvidia-docker2 dependencies following the starter guide. Install
x11vncwithsudo apt-get install x11vnc. - Have xserver running on your host machine, and run
x11vncon DISPLAY :0. docker run --runtime=nvidia -ti --rm -e DISPLAY -v /tmp/.X11-unix/X0:/tmp/.X11-unix/X0 -v <host path to dataset folder>:/root/mount/gibson/gibson/assets/dataset <gibson image name>- Run gibson with
python <gibson example or training>inside docker. - Visit your
host:5900and you should be able to see the GUI.
If you don't have X server running, you can still run gibson, see this guide for more details.
If you don't want to use our docker image, you can also install gibson locally. This will require some dependencies to be installed.
First, make sure you have Nvidia driver and CUDA installed. If you install from source, CUDA 9 is not necessary, as that is for nvidia-docker 2.0. Then, let's install some dependencies:
apt-get update
apt-get install libglew-dev libglm-dev libassimp-dev xorg-dev libglu1-mesa-dev libboost-dev \
mesa-common-dev freeglut3-dev libopenmpi-dev cmake golang libjpeg-turbo8-dev wmctrl \
xdotool libzmq3-dev zlib1g-devInstall required deep learning libraries: Using python3.5 is recommended. You can create a python3.5 environment first.
conda create -n py35 python=3.5 anaconda
source activate py35 # the rest of the steps needs to be performed in the conda environment
conda install -c conda-forge opencv
pip install http://download.pytorch.org/whl/cu90/torch-0.3.1-cp35-cp35m-linux_x86_64.whl
pip install torchvision==0.2.0
pip install tensorflow==1.3Clone the repository, download data and build
git clone https://github.com/StanfordVL/GibsonEnv.git
cd GibsonEnv
./download.sh # this script downloads assets data file and decompress it into gibson/assets folder
./build.sh build_local ### build C++ and CUDA files
pip install -e . ### Install python librariesInstall OpenAI baselines if you need to run the training demo.
git clone https://github.com/fxia22/baselines.git
pip install -e baselinesUninstall gibson is easy. If you installed with docker, just run docker images -a | grep "gibson" | awk '{print $3}' | xargs docker rmi to clean up the image. If you installed from source, uninstall with pip uninstall gibson
First run xhost +local:root on your host machine to enable display. You may need to run export DISPLAY=:0 first. After getting into the docker container with docker run --runtime=nvidia -ti --rm -e DISPLAY -v /tmp/.X11-unix:/tmp/.X11-unix -v <host path to dataset folder>:/root/mount/gibson/gibson/assets/dataset gibson, you will get an interactive shell. Now you can run a few demos.
If you installed from source, you can run those directly using the following commands without using docker.
python examples/demo/play_husky_nonviz.py ### Use ASWD keys on your keyboard to control a car to navigate around Gates building
You will be able to use ASWD keys on your keyboard to control a car to navigate around Gates building. A camera output will not be shown in this particular demo.
python examples/demo/play_husky_camera.py ### Use ASWD keys on your keyboard to control a car to navigate around Gates building, while RGB and depth camera outputs are also shown.
You will able to use ASWD keys on your keyboard to control a car to navigate around Gates building. You will also be able to see the RGB and depth camera outputs.
python examples/train/train_husky_navigate_ppo2.py ### Use PPO2 to train a car to navigate down the hallway in Gates building, using visual input from the camera.
python examples/train/train_ant_navigate_ppo1.py ### Use PPO1 to train an ant to navigate down the hallway in Gates building, using visual input from the camera.
Below is Gibson Environment's framerate benchmarked on different platforms. Please refer to fps branch for the code to reproduce the results.
| Platform | Tested on Intel E5-2697 v4 + NVIDIA Tesla V100 | ||
|---|---|---|---|
| Resolution [nxn] | 128 | 256 | 512 |
RGBD, pre networkf |
109.1 | 58.5 | 26.5 |
RGBD, post networkf |
77.7 | 30.6 | 14.5 |
RGBD, post small networkf |
87.4 | 40.5 | 21.2 |
| Depth only | 253.0 | 197.9 | 124.7 |
| Surface Normal only | 207.7 | 129.7 | 57.2 |
| Semantic only | 190.0 | 144.2 | 55.6 |
| Non-Visual Sensory | 396.1 | 396.1 | 396.1 |
We also tested on Intel I7 7700 + NVIDIA GeForce GTX 1070Ti and Tested on Intel I7 6580k + NVIDIA GTX 1080Ti platforms. The FPS difference is within 10% on each task.
| Platform | Multi-process FPS tested on Intel E5-2697 v4 + NVIDIA Tesla V100 | |||||
|---|---|---|---|---|---|---|
| Configuration | 512x512 episode sync | 512x512 frame sync | 256x256 episode sync | 256x256 frame sync | 128x128 episode sync | 128x128 frame sync |
| 1 process | 12.8 | 12.02 | 32.98 | 32.98 | 52 | 52 |
| 2 processes | 23.4 | 20.9 | 60.89 | 53.63 | 86.1 | 101.8 |
| 4 processes | 42.4 | 31.97 | 105.26 | 76.23 | 97.6 | 145.9 |
| 8 processes | 72.5 | 48.1 | 138.5 | 97.72 | 113 | 151 |

When running Gibson, you can start a web user interface with python gibson/utils/web_ui.py python gibson/utils/web_ui.py 5552. This is helpful when you cannot physically access the machine running gibson or you are running on a headless cloud environment. You need to change mode in configuration file to web_ui to use the web user interface.


Gibson can provide pixel-wise frame-by-frame semantic masks when the model is semantically annotated. As of now we have incorporated models from Stanford 2D-3D-Semantics Dataset and Matterport 3D for this purpose. You can access them within Gibson here. We refer you to the original dataset's reference for the list of their semantic classes and annotations.
For detailed instructions of rendering semantics in Gibson, see semantic instructions. As one example in the starter dataset that comes with installation, space7 includes Stanford 2D-3D-Semantics style annotation.
Gibson provides a base set of agents. See videos of these agents and their corresponding perceptual observation here.

To enable (optionally) abstracting away low-level control and robot dynamics for high-level tasks, we also provide a set of practical and ideal controllers for each agent.
| Agent Name | DOF | Information | Controller |
|---|---|---|---|
| Mujoco Ant | 8 | OpenAI Link | Torque |
| Mujoco Humanoid | 17 | OpenAI Link | Torque |
| Husky Robot | 4 | ROS, Manufacturer | Torque, Velocity, Position |
| Minitaur Robot | 8 | Robot Page, Manufacturer | Sine Controller |
| JackRabbot | 2 | Stanford Project Link | Torque, Velocity, Position |
| TurtleBot | 2 | ROS, Manufacturer | Torque, Velocity, Position |
| Quadrotor | 6 | Paper | Position |
More demonstration examples can be found in examples/demo folder
| Example | Explanation |
|---|---|
play_ant_camera.py |
Use 1234567890qwerty keys on your keyboard to control an ant to navigate around Gates building, while RGB and depth camera outputs are also shown. |
play_ant_nonviz.py |
Use 1234567890qwerty keys on your keyboard to control an ant to navigate around Gates building. |
play_drone_camera.py |
Use ASWDZX keys on your keyboard to control a drone to navigate around Gates building, while RGB and depth camera outputs are also shown. |
play_drone_nonviz.py |
Use ASWDZX keys on your keyboard to control a drone to navigate around Gates building |
play_humanoid_camera.py |
Use 1234567890qwertyui keys on your keyboard to control a humanoid to navigate around Gates building. Just kidding, controlling humaniod with keyboard is too difficult, you can only watch it fall. Press R to reset. RGB and depth camera outputs are also shown. |
play_humanoid_nonviz.py |
Watch a humanoid fall. Press R to reset. |
play_husky_camera.py |
Use ASWD keys on your keyboard to control a car to navigate around Gates building, while RGB and depth camera outputs are also shown. |
play_husky_nonviz.py |
Use ASWD keys on your keyboard to control a car to navigate around Gates building |
More training code can be found in examples/train folder.
| Example | Explanation |
|---|---|
train_husky_navigate_ppo2.py |
Use PPO2 to train a car to navigate down the hallway in Gates building, using RGBD input from the camera. |
train_husky_navigate_ppo1.py |
Use PPO1 to train a car to navigate down the hallway in Gates building, using RGBD input from the camera. |
train_ant_navigate_ppo1.py |
Use PPO1 to train an ant to navigate down the hallway in Gates building, using visual input from the camera. |
train_ant_climb_ppo1.py |
Use PPO1 to train an ant to climb down the stairs in Gates building, using visual input from the camera. |
train_ant_gibson_flagrun_ppo1.py |
Use PPO1 to train an ant to chase a target (a red cube) in Gates building. Everytime the ant gets to target(or time out), the target will change position. |
train_husky_gibson_flagrun_ppo1.py |
Use PPO1 to train a car to chase a target (a red cube) in Gates building. Everytime the car gets to target(or time out), the target will change position. |
We provide examples of configuring Gibson with ROS here. We use turtlebot as an example, after a policy is trained in Gibson, it requires minimal changes to deploy onto a turtlebot. See README for more details.
You can code your RL agent following our convention. The interface with our environment is very simple (see some examples in the end of this section).
First, you can create an environment by creating an instance of classes in gibson/core/envs folder.
env = AntNavigateEnv(is_discrete=False, config = config_file)Then do one step of the simulation with env.step. And reset with env.reset()
obs, rew, env_done, info = env.step(action)obs gives the observation of the robot. It is a dictionary with each component as a key value pair. Its keys are specified by user inside config file. E.g. obs['nonviz_sensor'] is proprioceptive sensor data, obs['rgb_filled'] is rgb camera data.
rew is the defined reward. env_done marks the end of one episode, for example, when the robot dies.
info gives some additional information of this step; sometimes we use this to pass additional non-visual sensor values.
We mostly followed OpenAI gym convention when designing the interface of RL algorithms and the environment. In order to help users start with the environment quicker, we provide some examples at examples/train. The RL algorithms that we use are from openAI baselines with some adaptation to work with hybrid visual and non-visual sensory data. In particular, we used PPO and a speed optimized version of PPO.
Each environment is configured with a yaml file. Examples of yaml files can be found in examples/configs folder. Parameters for the file is explained below. For more informat specific to Bullet Physics engine, you can see the documentation here.
| Argument name | Example value | Explanation |
|---|---|---|
| envname | AntClimbEnv | Environment name, make sure it is the same as the class name of the environment |
| model_id | space1-space8 | Scene id, in beta release, choose from space1-space8 |
| target_orn | [0, 0, 3.14] | Eulerian angle (in radian) target orientation for navigating, the reference frame is world frame. For non-navigation tasks, this parameter is ignored. |
| target_pos | [-7, 2.6, -1.5] | target position (in meter) for navigating, the reference frame is world frame. For non-navigation tasks, this parameter is ignored. |
| initial_orn | [0, 0, 3.14] | initial orientation (in radian) for navigating, the reference frame is world frame |
| initial_pos | [-7, 2.6, 0.5] | initial position (in meter) for navigating, the reference frame is world frame |
| fov | 1.57 | field of view for the camera, in radian |
| use_filler | true/false | use neural network filler or not. It is recommended to leave this argument true. See Gibson Environment website for more information. |
| display_ui | true/false | Gibson has two ways of showing visual output, either in multiple windows, or aggregate them into a single pygame window. This argument determines whether to show pygame ui or not, if in a production environment (training), you need to turn this off |
| show_diagnostics | true/false | show dignostics(including fps, robot position and orientation, accumulated rewards) overlaying on the RGB image |
| ui_num | 2 | how many ui components to show, this should be length of ui_components. |
| ui_components | [RGB_FILLED, DEPTH] | which are the ui components, choose from [RGB_FILLED, DEPTH, NORMAL, SEMANTICS, RGB_PREFILLED] |
| output | [nonviz_sensor, rgb_filled, depth] | output of the environment to the robot, choose from [nonviz_sensor, rgb_filled, depth]. These values are independent of ui_components, as ui_components determines what to show and output determines what the robot receives. |
| resolution | 512 | choose from [128, 256, 512] resolution of rgb/depth image |
| initial_orn | [0, 0, 3.14] | initial orientation (in radian) for navigating, the reference frame is world frame |
| speed : timestep | 0.01 | length of one physics simulation step in seconds(as defined in Bullet). For example, if timestep=0.01 sec, frameskip=10, and the environment is running at 100fps, it will be 10x real time. Note: setting timestep above 0.1 can cause instability in current version of Bullet simulator since an object should not travel faster than its own radius within one timestep. You can keep timestep at a low value but increase frameskip to simulate at a faster speed. See Bullet guide under "discrete collision detection" for more info. |
| speed : frameskip | 10 | how many timestep to skip when rendering frames. See above row for an example. For tasks that does not require high frequency control, you can set frameskip to larger value to gain further speed up. |
| mode | gui/headless/web_ui | gui or headless, if in a production environment (training), you need to turn this to headless. In gui mode, there will be visual output; in headless mode, there will be no visual output. In addition to that, if you set mode to web_ui, it will behave like in headless mode but the visual will be rendered to a web UI server. (more information) |
| verbose | true/false | show diagnostics in terminal |
| fast_lq_render | true/false | if there is fast_lq_render in yaml file, Gibson will use a smaller filler network, this will render faster but generate slightly lower quality camera output. This option is useful for training RL agents fast. |
Gibson provides a set of methods for you to define your own environments. You can follow the existing environments inside gibson/core/envs.
| Method name | Usage |
|---|---|
| robot.render_observation(pose) | Render new observations based on pose, returns a dictionary. |
| robot.get_observation() | Get observation at current pose. Needs to be called after robot.render_observation(pose). This does not induce extra computation. |
| robot.get_position() | Get current robot position. |
| robot.get_orientation() | Get current robot orientation. |
| robot.eyes.get_position() | Get current robot perceptive camera position. |
| robot.eyes.get_orientation() | Get current robot perceptive camera orientation. |
| robot.get_target_position() | Get robot target position. |
| robot.apply_action(action) | Apply action to robot. |
| robot.reset_new_pose(pos, orn) | Reset the robot to any pose. |
| robot.dist_to_target() | Get current distance from robot to target. |
Gibson includes a baked-in domain adaptation mechanism, named Goggles, for when an agent trained in Gibson is going to be deployed in real-world (i.e. operate based on images coming from an onboard camera). The mechanisms is essentially a learned inverse function that alters the frames coming from a real camera to what they would look like if they were rendered via Gibson, and hence, disolve the domain gap.
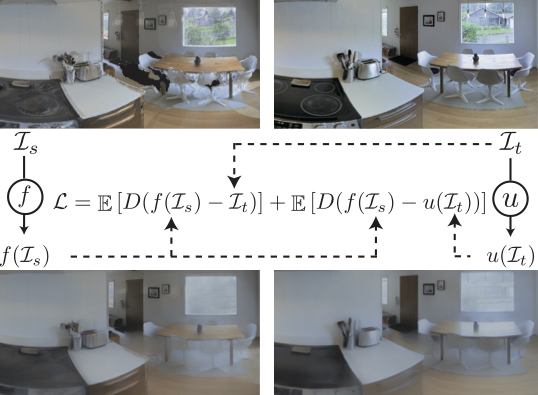
More details: With all the imperfections in point cloud rendering, it has been proven difficult to get completely photo-realistic rendering with neural network fixes. The remaining issues make a domain gap between the synthesized and real images. Therefore, we formulate the rendering problem as forming a joint space ensuring a correspondence between rendered and real images, rather than trying to (unsuccessfully) render images that are identical to real ones. This provides a deterministic pathway for traversing across these domains and hence undoing the gap. We add another network "u" for target image (I_t) and define the rendering loss to minimize the distance between f(I_s) and u(I_t), where "f" and "I_s" represent the filler neural network and point cloud rendering output, respectively (see the loss in above figure). We use the same network structure for f and u. The function u(I) is trained to alter the observation in real-world, I_t, to look like the corresponding I_s and consequently dissolve the gap. We named the u network goggles, as it resembles corrective lenses for the agent for deployment in real-world. Detailed formulation and discussion of the mechanism can be found in the paper. You can download the function u and apply it when you deploy your trained agent in real-world.
In order to use goggle, you will need preferably a camera with depth sensor, we provide an example here for Kinect. The trained goggle functions are stored in assets/unfiller_{resolution}.pth, and each one is paired with one filler function. You need to use the correct one depending on which filler function is used. If you don't have a camera with depth sensor, we also provide an example for RGB only here.
If you use Gibson Environment's software or database, please cite:
@inproceedings{xiazamirhe2018gibsonenv,
title={Gibson {Env}: real-world perception for embodied agents},
author={Xia, Fei and R. Zamir, Amir and He, Zhi-Yang and Sax, Alexander and Malik, Jitendra and Savarese, Silvio},
booktitle={Computer Vision and Pattern Recognition (CVPR), 2018 IEEE Conference on},
year={2018},
organization={IEEE}
}