RipMeWithDB is a training exercise for myself, currently, and is part of continuing my basic Java learning all those years ago. It isn't likely to be ready for "prime time" any time soon, and I'm much more apt to simply submit my changes to the RipMe team itself, so they can embrace and extend it beyond these basic framework ideas I have for it.
RipMeWithDB is an album ripper for various websites. It is a fork of the original RipMe tool (https://github.com/ripmeapp/ripme/), but with a few key changes to make it far more useful and independent.
Additions:
- Derby in Embedded mode support
- Tracking/using personal credentials for various sites
- Breaking out rippers to indpedent files from the main code
- Threaded image finding and downloading
- Shortening redundancy checks of sites already downloaded to conserve API calls
It is a cross-platform tool that runs on your computer, and requires Java 8 (but is being built with OpenJDK 15). RipMeWithDB will be tested on Windows and Linux as those are the only operating systems I have immediate access to.
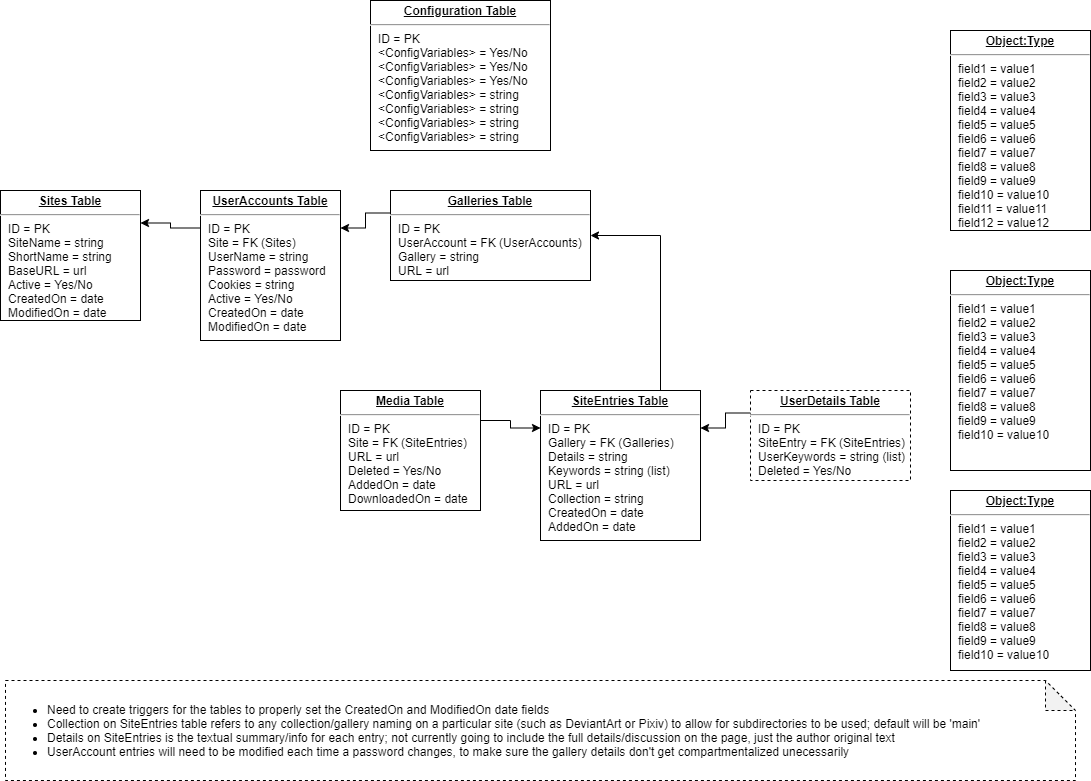
Current ERD plan for database: https://i.postimg.cc/VshkBWBz/Rip-Me-With-DB-Relationship-Diagram.png
{kind=link}
No meaningful changes have been integrated yet, but will be available via Downloads as available.
On macOS, there is a cask.
brew cask install ripme && xattr -d com.apple.quarantine /Applications/ripme.jar
Changelog (ripme.json)
- Quickly downloads all images in an online album. See supported sites
- Easily re-rip albums to fetch new content
- Built in updater
- Skips already downloaded images by default
- Can auto skip e-hentai and nhentai albums containing certain tags. See here for how to enable
- Download a range of urls. See here for how
- imgur
- tumblr
- flickr
- photobucket
- gonewild
- motherless
- imagefap
- imagearn
- seenive
- vinebox
- 8muses
- deviantart
- xhamster
- (more)
Request support for more sites by adding a comment to this Github issue.
If you're a developer, you can add your own Ripper by following the wiki guide: How To Create A Ripper for HTML Websites.
The project uses Maven. To build the .jar file using Maven, navigate to the root project directory and run:
mvn clean compile assembly:singleThis will include all dependencies in the JAR.
Tests can be marked as beeing slow, or flaky. Default is to run all but the flaky tests. Slow tests can be excluded to run. slow and flaky tests can be run on its own. After building you can run tests, quoting might be necessary depending on your shell:
mvn test
mvn test -DexcludedGroups= -Dgroups=flaky,slow
mvn test '-Dgroups=!slow'Please note that some tests may fail as sites change and our rippers become out of date. Start by building and testing a released version of RipMe and then ensure that any changes you make do not cause more tests to break.