


Table of contents
- Importing Libaries
- Data pre-processing
- Decision Tree Base Learner
- StackBoost-Cascading
Background
Cascading, according to Google, in simple English literature means "a process whereby something, typically information or knowledge, is successively passed on". Cascading is one of the most powerful ensemble learning algorithm which is used by Machine Learning engineers and scientists when they want to be absolutely dead sure about the accuracy of a result. For example, suppose we want to build a machine learning model which would detect if a credit card transaction is fraudulent or not. If you think about it, it's a binary classification problem where a class label 0 means the transaction is not fraud & a class label 1 means the transaction is fraudulent. In such a model, it's very risky to put our faith completely on just one model. So what we do is build a sequence of models (or a cascade of models) to be absolutely sure about the fact that the transaction is not fraudulent. Cascade models are mostly used when the cost of making a mistake is very very high. I will try to explain cascading with the help of a simple diagram.
Use a simple DecisionTreeClassifier as your base classifier. Make each successive model more complex by increasing the maximum_depth of the tree starting from a depth of a single split.
Use a confidence threshold of 0.95 and cascading depth of 15.
What changes would you make to the algorithm/implementation to improve performance?
Our Approuch - StackBoost Cascading
1. Change from Tree base classifiers to Boosting
classifiers (e.g. XGBoost, AdaBoost and GradientBoosting)
2. Tune more hyperparameters when cascading (e.g. max_depth, n_estimators and learning_rate)
3. Evaluate using Cross-Validation Procedure
4. Use Ensemble Voting - Majority Role (e.g. hard or soft voting)
Boosting
The second ensemble technique that we are going to discuss today is called Boosting. Boosting, in general, is used to convert weak learners to strong ones. Weak learners are basically classifier which has a very weak correlation with the true class labels and strong learners are classifiers that have a very high correlation between the model and the true class labels. Boosting involves training the weak learners iteratively, each trying to correct the error made by the previous model. This is achieved by training a weak model on the whole training data, then building a second model which aims at correcting the errors made by the first model. Then we build a third model which will correct the errors made by the second model and so on.
The EnsembleVoteClassifier is a meta-classifier for combining similar or conceptually different machine learning classifiers for classification via majority or plurality voting. (For simplicity, we will refer to both majority and plurality voting as majority voting.)
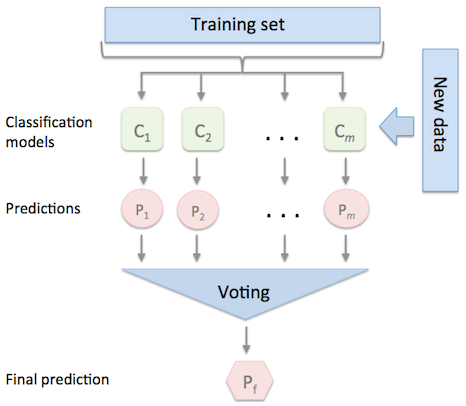
The EnsembleVoteClassifier implements "hard" and "soft" voting. In hard voting, we predict the final class label as the class label that has been predicted most frequently by the classification models. In soft voting, we predict the class labels by averaging the class-probabilities (only recommended if the classifiers are well-calibrated).
Evaluate the predictive performance using the log-loss metric.
- Python 3.6
- Git 2.26
- PyCharm IDEA (recommend)
You can modify or contribute to this project by following the steps below:
1. Clone the repository
-
Open terminal ( Ctrl + Alt + T )
-
Clone to a location on your machine.
# Clone the repository
$> git clone https://github.com/serfati/ensamble-learning.git
# Navigate to the directory
$> cd ensamble-learning2. Install Dependencies
# install with pip/conda
$> pip install -r requirments.txt3. launch of the project
# Run nootebook
$> jupyter notebook ensemble-learning.ipynb-
Or open with Colab
author Serfati
This program is free software: you can redistribute it and/or modify it under the terms of the MIT LICENSE as published by the Free Software Foundation.