Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Turn caching off by default when
max_diff==1 (#5243)
**Context:** Recent benchmarks (see #5211 (comment)) have shown that caching adds massive classical overheads, but often does not actually lead to a reduction in the the number of executions in normal workflows. Because of this, we want to make smart choices about when to use caching. Higher-order derivatives often result in duplicate circuits, so we need to keep caching when calculating higher-order derivatives. But, we can make caching opt-in for normal workflows. This will lead to reduced overheads in the vast majority of workflows. **Description of the Change:** The `QNode` keyword argument `cache` defaults to `None`. This is interpreted as `True` if `max_diff > 1` and `False` otherwise. **Benefits:** Vastly reduced classical overheads in most cases. **Possible Drawbacks:** Increased number of executions in a few edge cases. But these edge cases would be fairly convoluted. Somehow a transform would have to turn the starting tape into two identical tapes. **Related GitHub Issues:** **Performance Numbers:** ``` n_layers = 1 dev = qml.device('lightning.qubit', wires=n_wires) shape = qml.StronglyEntanglingLayers.shape(n_wires=n_wires, n_layers=n_layers) rng = qml.numpy.random.default_rng(seed=42) params = rng.random(shape) @qml.qnode(dev, cache=False) def circuit(params): qml.StronglyEntanglingLayers(params, wires=range(n_wires)) return qml.expval(qml.Z(0)) @qml.qnode(dev, cache=True) def circuit_cache(params): qml.StronglyEntanglingLayers(params, wires=range(n_wires)) return qml.expval(qml.Z(0)) ``` For `n_wires = 20`  But for `n_wires= 10`: 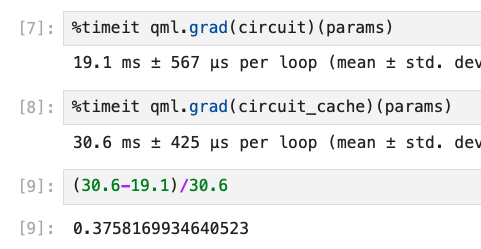 For `n_wires=20 n_layers=5`, we have:  While the cache version does seem to be faster here, that does seem to be statistical fluctuations. For `n_wires=10 n_layers=20`: 
- Loading branch information