In this we explore text classification, NER ,question answering using BERT and text summarization and question answering using BART
we also explore the LLMs like T5 Large, Ernie(chinese LLM)and Pegasus It can be access through the GitHub repository
In this repo we implement Text Classification,Named Entity Recignition and Question Answering Tasks Using BERT i.e, we done
Text Classification using pretrained model of BERT bert-base-uncased
Named Entity Recognition Using pretrained model of BERT dbmdz/bert-large-cased-finetuned-conll03-english
Question Answering Task using pretrained model of BERT bert-large-uncased-whole-word-masking-finetuned-squad
BERT, or Bidirectional Encoder Representations from Transformers, is a new method of pre-training language representations which obtains state-of-the-art results on a wide array of Natural Language Processing (NLP) tasks.
This Research paper which describes BERT in detail and provides full results on a number of tasks can be found here: https://arxiv.org/abs/1810.04805.
To give a few numbers, here are the results on the SQuAD v1.1 question answering task:
| SQuAD v1.1 Leaderboard (Oct 8th 2018) | Test EM | Test F1 |
|---|---|---|
| 1st Place Ensemble - BERT | 87.4 | 93.2 |
| 2nd Place Ensemble - nlnet | 86.0 | 91.7 |
| 1st Place Single Model - BERT | 85.1 | 91.8 |
| 2nd Place Single Model - nlnet | 83.5 | 90.1 |
And several natural language inference tasks:
| System | MultiNLI | Question NLI | SWAG |
|---|---|---|---|
| BERT | 86.7 | 91.1 | 86.3 |
| OpenAI GPT (Prev. SOTA) | 82.2 | 88.1 | 75.0 |
Plus many other tasks.
Moreover, these results were all obtained with almost no task-specific neural network architecture design.
If you already know what BERT is and you just want to get started, you can download the pre-trained models and run a state-of-the-art fine-tuning in only a few minutes.
BERT is a method of pre-training language representations, meaning that we train a general-purpose "language understanding" model on a large text corpus (like Wikipedia), and then use that model for downstream NLP tasks that we care about (like question answering). BERT outperforms previous methods because it is the first unsupervised, deeply bidirectional system for pre-training NLP.
Unsupervised means that BERT was trained using only a plain text corpus, which is important because an enormous amount of plain text data is publicly available on the web in many languages.
Pre-trained representations can also either be context-free or contextual,
and contextual representations can further be unidirectional or
bidirectional. Context-free models such as
word2vec or
GloVe generate a single "word
embedding" representation for each word in the vocabulary, so bank would have
the same representation in bank deposit and river bank. Contextual models
instead generate a representation of each word that is based on the other words
in the sentence.
BERT was built upon recent work in pre-training contextual representations —
including Semi-supervised Sequence Learning,
Generative Pre-Training,
ELMo, and
ULMFit
— but crucially these models are all unidirectional or shallowly
bidirectional. This means that each word is only contextualized using the words
to its left (or right). For example, in the sentence I made a bank deposit the
unidirectional representation of bank is only based on I made a but not
deposit. Some previous work does combine the representations from separate
left-context and right-context models, but only in a "shallow" manner. BERT
represents "bank" using both its left and right context — I made a ... deposit
— starting from the very bottom of a deep neural network, so it is deeply
bidirectional.
BERT uses a simple approach for this: We mask out 15% of the words in the input, run the entire sequence through a deep bidirectional Transformer encoder, and then predict only the masked words. For example:
Input: the man went to the [MASK1] . he bought a [MASK2] of milk.
Labels: [MASK1] = store; [MASK2] = gallon
In order to learn relationships between sentences, we also train on a simple
task which can be generated from any monolingual corpus: Given two sentences A
and B, is B the actual next sentence that comes after A, or just a random
sentence from the corpus?
Sentence A: the man went to the store .
Sentence B: he bought a gallon of milk .
Label: IsNextSentence
Sentence A: the man went to the store .
Sentence B: penguins are flightless .
Label: NotNextSentence
We then train a large model (12-layer to 24-layer Transformer) on a large corpus (Wikipedia + BookCorpus) for a long time (1M update steps), and that's BERT.
Using BERT has two stages: Pre-training and fine-tuning.
Pre-training is fairly expensive (four days on 4 to 16 Cloud TPUs), but is a one-time procedure for each language (current models are English-only, but multilingual models will be released in the near future). We are releasing a number of pre-trained models from the paper which were pre-trained at Google. Most NLP researchers will never need to pre-train their own model from scratch.
Fine-tuning is inexpensive. All of the results in the paper can be replicated in at most 1 hour on a single Cloud TPU, or a few hours on a GPU, starting from the exact same pre-trained model. SQuAD, for example, can be trained in around 30 minutes on a single Cloud TPU to achieve a Dev F1 score of 91.0%, which is the single system state-of-the-art.
The other important aspect of BERT is that it can be adapted to many types of NLP tasks very easily. In the paper, we demonstrate state-of-the-art results on sentence-level (e.g., SST-2), sentence-pair-level (e.g., MultiNLI), word-level (e.g., NER), and span-level (e.g., SQuAD) tasks with almost no task-specific modifications.
We are releasing the BERT-Base and BERT-Large models from the paper.
Uncased means that the text has been lowercased before WordPiece tokenization,
e.g., John Smith becomes john smith. The Uncased model also strips out any
accent markers. Cased means that the true case and accent markers are
preserved. Typically, the Uncased model is better unless you know that case
information is important for your task (e.g., Named Entity Recognition or
Part-of-Speech tagging).
For information about the Multilingual and Chinese model, see the Multilingual README.
The links to the models are here (right-click, 'Save link as...' on the name):
BERT-Large, Uncased (Whole Word Masking): 24-layer, 1024-hidden, 16-heads, 340M parametersBERT-Large, Cased (Whole Word Masking): 24-layer, 1024-hidden, 16-heads, 340M parametersBERT-Base, Uncased: 12-layer, 768-hidden, 12-heads, 110M parametersBERT-Large, Uncased: 24-layer, 1024-hidden, 16-heads, 340M parametersBERT-Base, Cased: 12-layer, 768-hidden, 12-heads , 110M parametersBERT-Large, Cased: 24-layer, 1024-hidden, 16-heads, 340M parametersBERT-Base, Multilingual Cased (New, recommended): 104 languages, 12-layer, 768-hidden, 12-heads, 110M parametersBERT-Base, Multilingual Uncased (Orig, not recommended)(Not recommended, useMultilingual Casedinstead): 102 languages, 12-layer, 768-hidden, 12-heads, 110M parametersBERT-Base, Chinese: Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters
Each .zip file contains three items:
- A TensorFlow checkpoint (
bert_model.ckpt) containing the pre-trained weights (which is actually 3 files). - A vocab file (
vocab.txt) to map WordPiece to word id. - A config file (
bert_config.json) which specifies the hyperparameters of the model.
Important: All results on the paper were fine-tuned on a single Cloud TPU,
which has 64GB of RAM. It is currently not possible to re-produce most of the
BERT-Large results on the paper using a GPU with 12GB - 16GB of RAM, because
the maximum batch size that can fit in memory is too small. We are working on
adding code to this repository which allows for much larger effective batch size
on the GPU. See the section on out-of-memory issues for
more details.
This code was tested with TensorFlow 1.11.0. It was tested with Python2 and Python3 (but more thoroughly with Python2, since this is what's used internally in Google).
The fine-tuning examples which use BERT-Base should be able to run on a GPU
that has at least 12GB of RAM using the hyperparameters given.
This is a release of 24 smaller BERT models (English only, uncased, trained with WordPiece masking) referenced in Well-Read Students Learn Better: On the Importance of Pre-training Compact Models.
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
You can download all 24 from here, or individually from the table below:
| H=128 | H=256 | H=512 | H=768 | |
|---|---|---|---|---|
| L=2 | 2/128 (BERT-Tiny) | 2/256 | 2/512 | 2/768 |
| L=4 | 4/128 | 4/256 (BERT-Mini) | 4/512 (BERT-Small) | 4/768 |
| L=6 | 6/128 | 6/256 | 6/512 | 6/768 |
| L=8 | 8/128 | 8/256 | 8/512 (BERT-Medium) | 8/768 |
| L=10 | 10/128 | 10/256 | 10/512 | 10/768 |
| L=12 | 12/128 | 12/256 | 12/512 | 12/768 (BERT-Base) |
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
| Model | Score | CoLA | SST-2 | MRPC | STS-B | QQP | MNLI-m | MNLI-mm | QNLI(v2) | RTE | WNLI | AX |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BERT-Tiny | 64.2 | 0.0 | 83.2 | 81.1/71.1 | 74.3/73.6 | 62.2/83.4 | 70.2 | 70.3 | 81.5 | 57.2 | 62.3 | 21.0 |
| BERT-Mini | 65.8 | 0.0 | 85.9 | 81.1/71.8 | 75.4/73.3 | 66.4/86.2 | 74.8 | 74.3 | 84.1 | 57.9 | 62.3 | 26.1 |
| BERT-Small | 71.2 | 27.8 | 89.7 | 83.4/76.2 | 78.8/77.0 | 68.1/87.0 | 77.6 | 77.0 | 86.4 | 61.8 | 62.3 | 28.6 |
| BERT-Medium | 73.5 | 38.0 | 89.6 | 86.6/81.6 | 80.4/78.4 | 69.6/87.9 | 80.0 | 79.1 | 87.7 | 62.2 | 62.3 | 30.5 |
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
***** New May 31st, 2019: Whole Word Masking Models *****
This is a release of several new models which were the result of an improvement the pre-processing code.
In the original pre-processing code, we randomly select WordPiece tokens to mask. For example:
Input Text: the man jumped up , put his basket on phil ##am ##mon ' s head
Original Masked Input: [MASK] man [MASK] up , put his [MASK] on phil [MASK] ##mon ' s head
The new technique is called Whole Word Masking. In this case, we always mask all of the the tokens corresponding to a word at once. The overall masking rate remains the same.
Whole Word Masked Input: the man [MASK] up , put his basket on [MASK] [MASK] [MASK] ' s head
The training is identical -- we still predict each masked WordPiece token independently. The improvement comes from the fact that the original prediction task was too 'easy' for words that had been split into multiple WordPieces.
Pre-trained models with Whole Word Masking are linked below. The data and training were otherwise identical, and the models have identical structure and vocab to the original models. We only include BERT-Large models. When using these models, please make it clear in the paper that you are using the Whole Word Masking variant of BERT-Large.
-
BERT-Large, Uncased (Whole Word Masking): 24-layer, 1024-hidden, 16-heads, 340M parameters -
BERT-Large, Cased (Whole Word Masking): 24-layer, 1024-hidden, 16-heads, 340M parameters
| Model | SQUAD 1.1 F1/EM | Multi NLI Accuracy |
|---|---|---|
| BERT-Large, Uncased (Original) | 91.0/84.3 | 86.05 |
| BERT-Large, Uncased (Whole Word Masking) | 92.8/86.7 | 87.07 |
| BERT-Large, Cased (Original) | 91.5/84.8 | 86.09 |
| BERT-Large, Cased (Whole Word Masking) | 92.9/86.7 | 86.46 |
BERT has been uploaded to TensorFlow Hub.).
***** New November 23rd, 2018: Un-normalized multilingual model + Thai + Mongolian *****
We uploaded a new multilingual model which does not perform any normalization on the input (no lower casing, accent stripping, or Unicode normalization), and additionally inclues Thai and Mongolian.
It is recommended to use this version for developing multilingual models, especially on languages with non-Latin alphabets.
This does not require any code changes, and can be downloaded here:
BERT-Base, Multilingual Cased: 104 languages, 12-layer, 768-hidden, 12-heads, 110M parameters
***** New November 15th, 2018: SOTA SQuAD 2.0 System *****
We released code changes to reproduce our 83% F1 SQuAD 2.0 system, which is currently 1st place on the leaderboard by 3%. See the SQuAD 2.0 section of the README for details.
***** New November 5th, 2018: Third-party PyTorch and Chainer versions of BERT available *****
NLP researchers from HuggingFace made a PyTorch version of BERT available which is compatible with our pre-trained checkpoints and is able to reproduce our results. Sosuke Kobayashi also made a Chainer version of BERT available (Thanks!) We were not involved in the creation or maintenance of the PyTorch implementation so please direct any questions towards the authors of that repository.
***** New November 3rd, 2018: Multilingual and Chinese models available *****
We have made two new BERT models available:
BERT-Base, Multilingual(Not recommended, useMultilingual Casedinstead): 102 languages, 12-layer, 768-hidden, 12-heads, 110M parametersBERT-Base, Chinese: Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters
For more, see the Multilingual README.
***** End new information *****
The Stanford Question Answering Dataset (SQuAD) is a popular question answering
benchmark dataset. BERT (at the time of the release) obtains state-of-the-art
results on SQuAD with almost no task-specific network architecture modifications
or data augmentation. However, it does require semi-complex data pre-processing
and post-processing to deal with (a) the variable-length nature of SQuAD context
paragraphs, and (b) the character-level answer annotations which are used for
SQuAD training. This processing is implemented and documented in run_squad.py.
To run on SQuAD, you will first need to download the dataset. The SQuAD website does not seem to link to the v1.1 datasets any longer, but the necessary files can be found here:
You should see a result similar to the 88.5% reported in the paper for
BERT-Base.
If you fine-tune for one epoch on TriviaQA before this the results will be even better, but you will need to convert TriviaQA into the SQuAD json format.
This model is also implemented and documented
To run on SQuAD 2.0, you will first need to download the dataset. The necessary files can be found here:
All experiments in the paper were fine-tuned on a Cloud TPU, which has 64GB of device RAM. Therefore, when using a GPU with 12GB - 16GB of RAM, you are likely to encounter out-of-memory issues if you use the same hyperparameters described in the paper.
The factors that affect memory usage are:
-
max_seq_length: The released models were trained with sequence lengths up to 512, but you can fine-tune with a shorter max sequence length to save substantial memory. This is controlled by themax_seq_lengthflag in our example code. -
train_batch_size: The memory usage is also directly proportional to the batch size. -
Model type,
BERT-Basevs.BERT-Large: TheBERT-Largemodel requires significantly more memory thanBERT-Base. -
Optimizer: The default optimizer for BERT is Adam, which requires a lot of extra memory to store the
mandvvectors. Switching to a more memory efficient optimizer can reduce memory usage, but can also affect the results. We have not experimented with other optimizers for fine-tuning.
the maximum batch size on single Titan X GPU (12GB RAM) with TensorFlow 1.11.0:
| System | Seq Length | Max Batch Size |
|---|---|---|
BERT-Base |
64 | 64 |
| ... | 128 | 32 |
| ... | 256 | 16 |
| ... | 320 | 14 |
| ... | 384 | 12 |
| ... | 512 | 6 |
BERT-Large |
64 | 12 |
| ... | 128 | 6 |
| ... | 256 | 2 |
| ... | 320 | 1 |
| ... | 384 | 0 |
| ... | 512 | 0 |
Unfortunately, these max batch sizes for BERT-Large are so small that they
will actually harm the model accuracy, regardless of the learning rate used. We
are working on adding code to this repository which will allow much larger
effective batch sizes to be used on the GPU. The code will be based on one (or
both) of the following techniques:
-
Gradient accumulation: The samples in a minibatch are typically independent with respect to gradient computation (excluding batch normalization, which is not used here). This means that the gradients of multiple smaller minibatches can be accumulated before performing the weight update, and this will be exactly equivalent to a single larger update.
-
Gradient checkpointing: The major use of GPU/TPU memory during DNN training is caching the intermediate activations in the forward pass that are necessary for efficient computation in the backward pass. "Gradient checkpointing" trades memory for compute time by re-computing the activations in an intelligent way.
However, this is not implemented in the current release.
In certain cases, rather than fine-tuning the entire pre-trained model end-to-end, it can be beneficial to obtained pre-trained contextual embeddings, which are fixed contextual representations of each input token generated from the hidden layers of the pre-trained model. This should also mitigate most of the out-of-memory issues.
We are releasing code to do "masked LM" and "next sentence prediction" on an arbitrary text corpus. Note that this is not the exact code that was used for the paper (the original code was written in C++, and had some additional complexity), but this code does generate pre-training data as described in the paper.
Here's how to run the data generation. The input is a plain text file, with one
sentence per line. (It is important that these be actual sentences for the "next
sentence prediction" task). Documents are delimited by empty lines. The output
is a set of tf.train.Examples serialized into TFRecord file format.
You can perform sentence segmentation with an off-the-shelf NLP toolkit such as spaCy.
The max_predictions_per_seq is the maximum number of masked LM predictions per
sequence. You should set this to around max_seq_length * masked_lm_prob (the
script doesn't do that automatically because the exact value needs to be passed
to both scripts).
- If using your own vocabulary, make sure to change
vocab_sizeinbert_config.json. If you use a larger vocabulary without changing this, you will likely get NaNs when training on GPU or TPU due to unchecked out-of-bounds access. - If your task has a large domain-specific corpus available (e.g., "movie reviews" or "scientific papers"), it will likely be beneficial to run additional steps of pre-training on your corpus, starting from the BERT checkpoint.
- The learning rate we used in the paper was 1e-4. However, if you are doing additional steps of pre-training starting from an existing BERT checkpoint, you should use a smaller learning rate (e.g., 2e-5).
- Current BERT models are English-only, but we do plan to release a multilingual model which has been pre-trained on a lot of languages in the near future (hopefully by the end of November 2018).
- Longer sequences are disproportionately expensive because attention is
quadratic to the sequence length. In other words, a batch of 64 sequences of
length 512 is much more expensive than a batch of 256 sequences of
length 128. The fully-connected/convolutional cost is the same, but the
attention cost is far greater for the 512-length sequences. Therefore, one
good recipe is to pre-train for, say, 90,000 steps with a sequence length of
128 and then for 10,000 additional steps with a sequence length of 512. The
very long sequences are mostly needed to learn positional embeddings, which
can be learned fairly quickly. Note that this does require generating the
data twice with different values of
max_seq_length. - If you are pre-training from scratch, be prepared that pre-training is
computationally expensive, especially on GPUs. If you are pre-training from
scratch, our recommended recipe is to pre-train a
BERT-Baseon a single preemptible Cloud TPU v2, which takes about 2 weeks at a cost of about $500 USD (based on the pricing in October 2018). You will have to scale down the batch size when only training on a single Cloud TPU, compared to what was used in the paper. It is recommended to use the largest batch size that fits into TPU memory.
We will not be able to release the pre-processed datasets used in the paper.
For Wikipedia, the recommended pre-processing is to download
the latest dump,
extract the text with
WikiExtractor.py, and then apply
any necessary cleanup to convert it into plain text.
Unfortunately the researchers who collected the BookCorpus no longer have it available for public download. The Project Guttenberg Dataset is a somewhat smaller (200M word) collection of older books that are public domain.
Common Crawl is another very large collection of text, but you will likely have to do substantial pre-processing and cleanup to extract a usable corpus for pre-training BERT.
If you want to use BERT with Colab
For now, cite the Arxiv paper:
#
@article{devlin2018bert,
title={BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding},
author={Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1810.04805},
year={2018}
}
In this Repo we perform NLP tasks like question answering ,Text Summarization using BART
i.e,
Text summarization task can be done by using pretrained model of BART facebook/bart-large-cnn
Question Answering task can be done by using Pretrained model of BART facebook/bart-large
This paper introduces BART, a pre-training method that combines Bidirectional and Auto-Regressive Transformers. BART is a denoising autoencoder that uses a sequence-to-sequence paradigm, making it useful for various applications. Pretraining consists of two phases: (1) text is corrupted using an arbitrary noising function, and (2) a sequence-to-sequence model is learned to reconstruct the original text.
BART's Transformer-based neural machine translation architecture can be seen as a generalization of BERT (due to the bidirectional encoder), GPT (With the left-to-right decoder), and many other contemporary pre-training approaches.
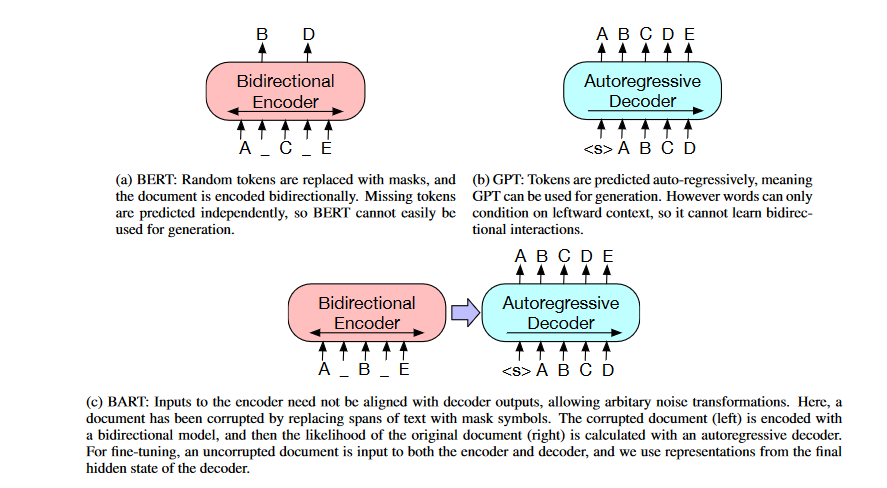
In addition to its strength in comprehension tasks, BART's effectiveness increases with fine-tuning for text generation. It generates new state-of-the-art results on various abstractive conversation, question answering, and summarization tasks, matching the performance of RoBERTa with comparable training resources on GLUE and SQuAD.
Architecture Except changing the ReLU activation functions to GeLUs and initializing parameters from (0, 0.02), BART follows the general sequence-to-sequence Transformer design (Vaswani et al., 2017). There are six layers in the encoder and decoder for the base model and twelve layers in each for the large model.
Similar to the architecture used in BERT, the two main differences are that (1) in BERT, each layer of the decoder additionally performs cross-attention over the final hidden layer of the encoder (as in the transformer sequence-to-sequence model); and (2) in BERT an additional feed-forward network is used before word prediction, whereas in BART there isn't.
To train BART, we first corrupt documents and then optimize a reconstruction loss, which is the cross-entropy between the decoder's output and the original document. In contrast to conventional denoising autoencoders, BART may be used for any type of document corruption.
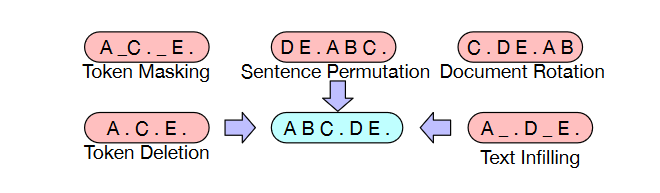
The worst-case scenario for BART is when all source information is lost, which becomes analogous to a language model. The researchers try out several new and old transformations, but they also believe there is much room for creating even more unique alternatives. In the following, we will outline the transformations they performed and provide some examples. Below is a summary of the transformations they used, and an illustration of some of the results is provided in the figure.
Token Masking: Following BERT, random tokens are sampled and replaced with MASK elements.
Token Deletion: Random tokens are deleted from the input. In contrast to token masking, the model must predict which positions are missing inputs.
Text Infilling: Several text spans are sampled, with span lengths drawn from a Poisson distribution (λ = 3). Each span is replaced with a single MASK token. Text infilling teaches the model to predict how many tokens are missing from a span.
Sentence Permutation: A document is divided into sentences based on full stops, and these sentences are shuffled in random order.
Document Rotation: A token is chosen uniformly at random, and the document is rotated to begin with that token. This task trains the model to identify the start of the document.
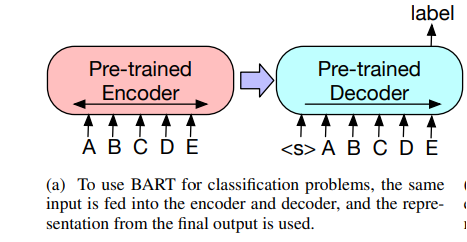
Several potential uses for the representations BART generates in subsequent processing steps exist:
Sequence Classification Tasks: For sequence classification problems, the same input is supplied into the encoder and decoder, and the final hidden states of the last decoder token is fed into the new multi-class linear classifier.
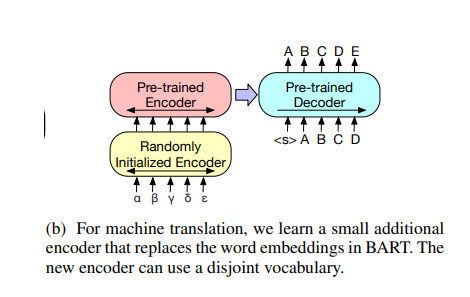
Token Classification Tasks: Both the encoder and decoder take the entire document as input, and from the decoder's top hidden state, a representation of each word is derived. The token's classification relies on its representation.
Sequence Generation Tasks: For sequence-generating tasks like answering abstract questions and summarizing text, BART's autoregressive decoder allows for direct fine-tuning. Both of these tasks are related to the pre-training goal of denoising since they involve the copying and subsequent manipulation of input data. Here, the input sequence serves as input to the encoder, while the decoder generates outputs in an autoregressive manner.
Machine Translation: The researchers investigate the feasibility of using BART to enhance machine translation decoders for translating into English. Using pre-trained encoders has been proven to improve models, while the benefits of incorporating pre-trained language models into decoders have been more limited. Using a set of encoder parameters learned from bitext, they demonstrate that the entire BART model can be used as a single pretrained decoder for machine translation. More specifically, they swap out the embedding layer of BART's encoder with a brand new encoder using random initialization. When the model is trained from start to end, the new encoder is trained to map foreign words into an input BART can then translate into English. In both stages of training, the cross-entropy loss is backpropagated from the BART model's output to train the source encoder. In the first stage, they fix most of BART's parameters and only update the randomly initialized source encoder, the BART positional embeddings, and the self-attention input projection matrix of BART's encoder first layer. Second, they perform a limited number of training iterations on all model parameters.
It takes much time for a researcher or journalist to sift through all the long-form information on the internet and find what they need. You can save time and energy by skimming the highlights of lengthy literature using a summary or paraphrase synopsis. The NLP task of summarizing texts may be automated with the help of transformer models. Extractive and abstractive techniques exist to achieve this goal. Summarizing a document extractively involves finding the most critical statements in the text and writing them down. One may classify this as a type of information retrieval. More challenging than literal summarizing is abstract summarization, which seeks to grasp the whole material and provide paraphrased text to sum up the key points. The second type of summary is carried out by transformer models such as BART.
HuggingFace gives us quick and easy access to thousands of pre-trained and fine-tuned weights for Transformer models, including BART. You can choose a tailored BART model for the text summarization assignment from the HuggingFace model explorer website. Each submitted model includes a detailed description of its configuration and training. The beginner-friendly bart-large-cnn model deserves a look, so let's look at it. Either use the HuggingFace Installation page or run pip install transformers to get started. Next, we'll follow these three easy steps to create our summary:
#Text Summarization using BART
from transformers import BartTokenizer, BartForConditionalGeneration
# Load pre-trained BART model and tokenizer
tokenizer = BartTokenizer.from_pretrained('facebook/bart-large-cnn')
model = BartForConditionalGeneration.from_pretrained('facebook/bart-large-cnn')
def summarize_text(text):
inputs = tokenizer.encode("summarize: " + text, return_tensors='pt', max_length=1024, truncation=True)
summary_ids = model.generate(inputs, max_length=150, min_length=40, length_penalty=2.0, num_beams=4, early_stopping=True)
summary = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
return summary
# Example usage
text = """
BART is a model developed by Facebook AI for various natural language processing (NLP) tasks. It combines bidirectional and auto-regressive transformers to achieve state-of-the-art performance on multiple tasks including summarization, translation, and text generation. The model was designed to handle the challenges of both text generation and understanding.
"""
print("Summary:")
print(summarize_text(text))Another option is to use BartTokenizer to generate tokens from text sequences and BartForConditionalGeneration for summarizing.
from transformers import BartForConditionalGeneration, BartTokenizer, BartConfigAs a pre-trained model, " bart-large-cnn" is optimized for the summary job. The from_pretrained() function is used to load the model, as seen below.
tokenizer=BartTokenizer.from_pretrained('facebook/bart-large-cnn')
model=BartForConditionalGeneration.from_pretrained('facebook/bart-large-cnn')Assume you have to summarize the same text as in the example above. You can make advantage of the tokenizer's batch_encode_plus() feature for this purpose. When called, this method produces a dictionary that stores the encoded sequence or sequence pair and any other information provided. How can we restrict the shortest possible sequence that can be returned?
In batch_encode_plus(), set the value of the max_length parameter. To get the ids of the summary output, we feed the input_ids into the model.generate() function.
inputs = tokenizer.batch_encode_plus([ARTICLE],return_tensors='pt')
summary_ids = model.generate(inputs['input_ids'], num_beams=4, max_length=150, early_stopping=True)The summary of the original text has been generated as a sequence of ids by the model.generate() method. The function model.generate() has many parameters, among which:
input_ids: The sequence used as a prompt for the generation.
max_length: The max length of the sequence to be generated. Between min_length and infinity. Default to 20.
min_length: The min length of the sequence to be generated. Between 0 and infinity. Default to 0.
num_beams: Number of beams for beam search. Must be between 1 and infinity. 1 means no beam search. Default to 1.
early_stopping: if set to True beam search is stopped when at least num_beams sentences finished per batch.
The decode() function can be used to transform the ids sequence into plain text.
# Decoding and printing the summary
summary = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
print(summary)The decode() convert a list of lists of token ids into a list of strings. Its accepts several parameters among which we will mention two of them:
token_ids: List of tokenized input ids.
skip_special_tokens : Whether or not to remove special tokens in the decoding.
References Reference1