-
Notifications
You must be signed in to change notification settings - Fork 2.7k
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Signed-off-by: sam1373 <[email protected]>
- Loading branch information
Showing
2 changed files
with
3 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1 @@ | ||
| {"nbformat":4,"nbformat_minor":0,"metadata":{"accelerator":"GPU","colab":{"name":"Self_Supervised_Pre_Training.ipynb","provenance":[{"file_id":"https://github.com/NVIDIA/NeMo/blob/main/tutorials/asr/ASR_with_NeMo.ipynb","timestamp":1636399360559}],"collapsed_sections":["i5XZWBnTf1pT","38aYTCTIlRzh","FLr1aJ-lf4_7","Rk7uDmuHAD2e"]},"kernelspec":{"display_name":"Python 3","language":"python","name":"python3"},"language_info":{"codemirror_mode":{"name":"ipython","version":3},"file_extension":".py","mimetype":"text/x-python","name":"python","nbconvert_exporter":"python","pygments_lexer":"ipython3","version":"3.7.7"},"pycharm":{"stem_cell":{"cell_type":"raw","source":[],"metadata":{"collapsed":false}}}},"cells":[{"cell_type":"code","metadata":{"id":"lJz6FDU1lRzc"},"source":["\"\"\"\n","You can run either this notebook locally (if you have all the dependencies and a GPU) or on Google Colab.\n","\n","Instructions for setting up Colab are as follows:\n","1. Open a new Python 3 notebook.\n","2. Import this notebook from GitHub (File -> Upload Notebook -> \"GITHUB\" tab -> copy/paste GitHub URL)\n","3. Connect to an instance with a GPU (Runtime -> Change runtime type -> select \"GPU\" for hardware accelerator)\n","4. Run this cell to set up dependencies.\n","5. Restart the runtime (Runtime -> Restart Runtime) for any upgraded packages to take effect\n","\"\"\"\n","# If you're using Google Colab and not running locally, run this cell.\n","\n","## Install dependencies\n","!pip install wget\n","!apt-get install sox libsndfile1 ffmpeg\n","!pip install unidecode\n","!pip install matplotlib>=3.3.2\n","\n","## Install NeMo\n","BRANCH = 'main'\n","!python -m pip install git+https://github.com/NVIDIA/NeMo.git@$BRANCH#egg=nemo_toolkit[all]\n","\n","\"\"\"\n","Remember to restart the runtime for the kernel to pick up any upgraded packages (e.g. matplotlib)!\n","Alternatively, you can uncomment the exit() below to crash and restart the kernel, in the case\n","that you want to use the \"Run All Cells\" (or similar) option.\n","\"\"\"\n","# exit()"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","source":["# Self-Supervised pre-training for ASR\n","\n","This notebook is a basic tutorial for pre-training a model using the self-supervised approach. With this approach, we use a training objective that does not require our dataset to be labeled, which significantly reduces the difficulty of collecting data for pre-training the model. After pre-training our encoder in this way, we can use it in a CTC or RNNT ASR model.\n","\n","The approach we will use for pre-training our models is represented in the following diagram:\n","\n"," 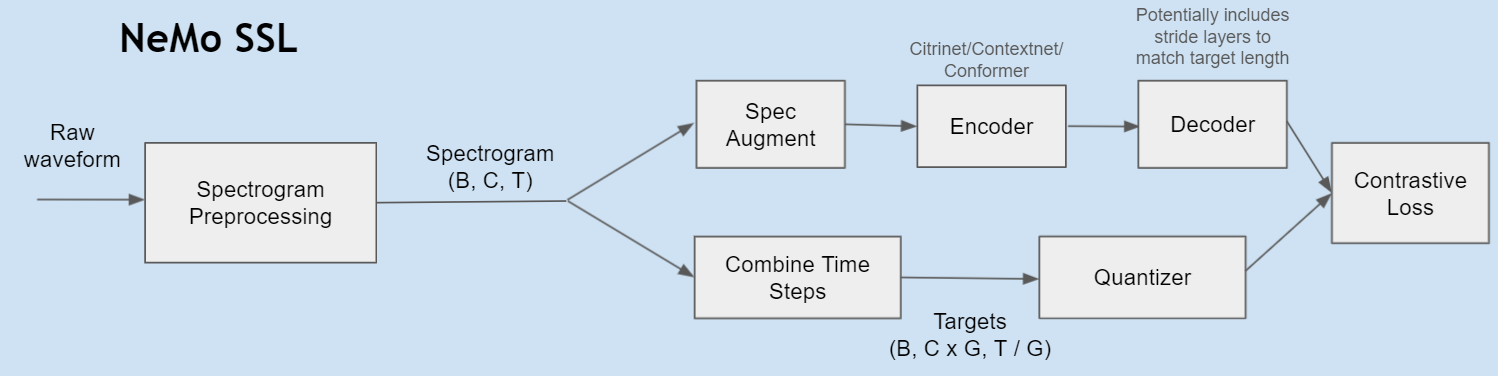\n","\n","We first mask parts of our input using SpecAugment. The model is then trained to solve a contrastive task of distinguishing the latent representation of the masked time steps from several sampled distractors. Since our encoders also contain stride blocks which reduce the length of the inputs, in order to obtain target representations we combine several consecutive time steps. They are then passed through a quantizer, which has been found to help with contrastive pre-training."],"metadata":{"id":"FGIVHjS1YEPw"}},{"cell_type":"markdown","source":["# Preparing our data"],"metadata":{"id":"i5XZWBnTf1pT"}},{"cell_type":"markdown","metadata":{"id":"38aYTCTIlRzh"},"source":["## Downloading dataset\n","\n","In order to demonstrate how to pre-train the model, we will use the AN4 dataset. Note: this is dataset is much smaller than one that we would typically want to use for self-supervised training, however it will suffice for this tutorial. This dataset also contains transcriptions, but they will be ignored for self-supervised pre-training.\n","\n","Before we get started, let's download and prepare the dataset. The utterances are available as `.sph` files, so we will need to convert them to `.wav` for later processing. If you are not using Google Colab, please make sure you have [Sox](http://sox.sourceforge.net/) installed for this step--see the \"Downloads\" section of the linked Sox homepage. (If you are using Google Colab, Sox should have already been installed in the setup cell at the beginning.)"]},{"cell_type":"code","metadata":{"id":"gAhsmi6HlRzh"},"source":["# This is where the an4/ directory will be placed.\n","# Change this if you don't want the data to be extracted in the current directory.\n","data_dir = '.'"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"Yb4fuUvWlRzk","scrolled":true,"collapsed":true},"source":["import glob\n","import os\n","import subprocess\n","import tarfile\n","import wget\n","\n","# Download the dataset. This will take a few moments...\n","print(\"******\")\n","if not os.path.exists(data_dir + '/an4_sphere.tar.gz'):\n"," an4_url = 'http://www.speech.cs.cmu.edu/databases/an4/an4_sphere.tar.gz'\n"," an4_path = wget.download(an4_url, data_dir)\n"," print(f\"Dataset downloaded at: {an4_path}\")\n","else:\n"," print(\"Tarfile already exists.\")\n"," an4_path = data_dir + '/an4_sphere.tar.gz'\n","\n","if not os.path.exists(data_dir + '/an4/'):\n"," # Untar and convert .sph to .wav (using sox)\n"," tar = tarfile.open(an4_path)\n"," tar.extractall(path=data_dir)\n","\n"," print(\"Converting .sph to .wav...\")\n"," sph_list = glob.glob(data_dir + '/an4/**/*.sph', recursive=True)\n"," for sph_path in sph_list:\n"," wav_path = sph_path[:-4] + '.wav'\n"," cmd = [\"sox\", sph_path, wav_path]\n"," subprocess.run(cmd)\n","print(\"Finished conversion.\\n******\")"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"m_LFeM0elRzm"},"source":["You should now have a folder called `an4` that contains `etc/an4_train.transcription`, `etc/an4_test.transcription`, audio files in `wav/an4_clstk` and `wav/an4test_clstk`, along with some other files we will not need.\n","\n","Now we can load and take a look at the data. As an example, file `cen2-mgah-b.wav` is a 2.6 second-long audio recording of a man saying the letters \"G L E N N\" one-by-one. To confirm this, we can listen to the file:"]},{"cell_type":"code","metadata":{"id":"_M_bSs3MjQlz"},"source":["import librosa\n","import IPython.display as ipd\n","\n","# Load and listen to the audio file\n","example_file = data_dir + '/an4/wav/an4_clstk/mgah/cen2-mgah-b.wav'\n","audio, sample_rate = librosa.load(example_file)\n","\n","ipd.Audio(example_file, rate=sample_rate)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"RdNyw1b_zgtm"},"source":["## Creating Data Manifests\n","\n","The first thing we need to do now is to create manifests for our training and evaluation data, which will contain the metadata of our audio files. NeMo data sets take in a standardized manifest format where each line corresponds to one sample of audio, such that the number of lines in a manifest is equal to the number of samples that are represented by that manifest. \n","\n","\n","A line must contain the path to an audio file, and the duration of the audio sample. For labeled datasets it will also contain the corresponding transcript (or path to a transcript file). Even though for self-supervised pre-training the transcript is unnecessary, we will still add it to our manifest, since we will also be using this dataset to demonstrate fine-tuning later on.\n","\n","Here's an example of what one line in a NeMo-compatible manifest might look like:\n","```\n","{\"audio_filepath\": \"path/to/audio.wav\", \"duration\": 3.45, \"text\": \"this is a nemo tutorial\"}\n","```\n","\n","We can build our training and evaluation manifests using `an4/etc/an4_train.transcription` and `an4/etc/an4_test.transcription`, which have lines containing transcripts and their corresponding audio file IDs:\n","```\n","...\n","<s> P I T T S B U R G H </s> (cen5-fash-b)\n","<s> TWO SIX EIGHT FOUR FOUR ONE EIGHT </s> (cen7-fash-b)\n","...\n","```"]},{"cell_type":"code","metadata":{"id":"lVB1sG1GlRzz"},"source":["# --- Building Manifest Files --- #\n","import json\n","\n","# Function to build a manifest\n","def build_manifest(transcripts_path, manifest_path, wav_path):\n"," with open(transcripts_path, 'r') as fin:\n"," with open(manifest_path, 'w') as fout:\n"," for line in fin:\n"," # Lines look like this:\n"," # <s> transcript </s> (fileID)\n"," transcript = line[: line.find('(')-1].lower()\n"," transcript = transcript.replace('<s>', '').replace('</s>', '')\n"," transcript = transcript.strip()\n","\n"," file_id = line[line.find('(')+1 : -2] # e.g. \"cen4-fash-b\"\n"," audio_path = os.path.join(\n"," data_dir, wav_path,\n"," file_id[file_id.find('-')+1 : file_id.rfind('-')],\n"," file_id + '.wav')\n","\n"," duration = librosa.core.get_duration(filename=audio_path)\n","\n"," # Write the metadata to the manifest\n"," metadata = {\n"," \"audio_filepath\": audio_path,\n"," \"duration\": duration,\n"," \"text\": transcript\n"," }\n"," json.dump(metadata, fout)\n"," fout.write('\\n')\n"," \n","# Building Manifests\n","print(\"******\")\n","train_transcripts = data_dir + '/an4/etc/an4_train.transcription'\n","train_manifest = data_dir + '/an4/train_manifest.json'\n","if not os.path.isfile(train_manifest):\n"," build_manifest(train_transcripts, train_manifest, 'an4/wav/an4_clstk')\n"," print(\"Training manifest created.\")\n","\n","test_transcripts = data_dir + '/an4/etc/an4_test.transcription'\n","test_manifest = data_dir + '/an4/test_manifest.json'\n","if not os.path.isfile(test_manifest):\n"," build_manifest(test_transcripts, test_manifest, 'an4/wav/an4test_clstk')\n"," print(\"Test manifest created.\")\n","print(\"***Done***\")"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","source":["# Self-supervised pre-training"],"metadata":{"id":"FLr1aJ-lf4_7"}},{"cell_type":"markdown","source":["## Setting up the config\n","\n","First, let's download the default config for ssl pre-training of Citrinet-1024, and the corresponding supervised training config, which we will use for fine-tuning later."],"metadata":{"id":"sT_uewIDk8oA"}},{"cell_type":"code","metadata":{"id":"978wWK7AKIvU"},"source":["## Grab the configs we'll use in this example\n","!mkdir configs\n","!wget -P configs/ https://raw.githubusercontent.com/NVIDIA/NeMo/main/examples/asr/conf/citrinet_ssl/citrinet_ssl_1024.yaml\n","!wget -P configs/ https://raw.githubusercontent.com/NVIDIA/NeMo/main/examples/asr/conf/citrinet/citrinet_1024.yaml\n"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","source":["Since this config is for a very large model, we will modify it to make a much smaller version for the purpose of this tutorial by reducing the number of channels and the number of sub-blocks in each block, as well as reducing masking and weight decay."],"metadata":{"id":"RLzjCgmHuJ_j"}},{"cell_type":"code","metadata":{"id":"Vmw9WbTPKHHA"},"source":["from omegaconf import OmegaConf\n","import torch\n","\n","config_path = './configs/citrinet_ssl_1024.yaml'\n","\n","cfg = OmegaConf.load(config_path)\n","\n","cfg.model.model_defaults.filters = 256\n","cfg.model.model_defaults.repeat = 1\n","cfg.model.model_defaults.enc_final = 256\n","\n","cfg.model.spec_augment.freq_masks = 0\n","cfg.model.spec_augment.time_masks = 5\n","\n","cfg.model.optim.weight_decay = 0\n","cfg.model.optim.sched.warmup_steps = 500\n","\n","cfg.model.train_ds.manifest_filepath = \"/content/an4/train_manifest.json\"\n","cfg.model.train_ds.batch_size = 16\n","\n","cfg.model.validation_ds.manifest_filepath = \"/content/an4/test_manifest.json\"\n","cfg.model.validation_ds.batch_size = 16\n","\n","cfg.trainer.max_epochs = None\n","cfg.trainer.max_steps = 2000 \n","#in practice you will usually want a much larger amount of pre-training steps\n","cfg.trainer.log_every_n_steps = 100\n","\n","if torch.cuda.is_available():\n"," cfg.trainer.gpus = 1\n"," cfg.trainer.accelerator = 'dp'\n","else:\n"," cfg.trainer.gpus = 0\n","\n","cfg.exp_manager.exp_dir = \"/content/exp\"\n","cfg.exp_manager.name = \"pre_trained\"\n","cfg.exp_manager.use_datetime_version = False\n","cfg.exp_manager.create_tensorboard_logger = False\n","cfg.exp_manager.resume_if_exists = True\n","cfg.exp_manager.resume_ignore_no_checkpoint = True\n","cfg.exp_manager.checkpoint_callback_params.save_best_model = True"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","source":["The parameters that are relevant to the self-supervised decoder and loss can be found in cfg.model.decoder and cfg.model loss. The default parameters tend to work well, so we will keep them as is for this tutorial."],"metadata":{"id":"TrfAb1DjWzpL"}},{"cell_type":"code","source":["print(cfg.model.decoder)\n","print(cfg.model.loss)"],"metadata":{"id":"DTcn93gMXQba"},"execution_count":null,"outputs":[]},{"cell_type":"markdown","source":["Now we will can create the config object."],"metadata":{"id":"yoUIMS7mgrUs"}},{"cell_type":"code","source":["cfg = OmegaConf.to_container(cfg, resolve=True)\n","cfg = OmegaConf.create(cfg)"],"metadata":{"id":"l0IqI0Yugqc1"},"execution_count":null,"outputs":[]},{"cell_type":"markdown","source":["## Pre-training the model\n","\n","We can now create the model based on our config and start pre-training with pytorch lightning. In NeMo you can use the examples/asr/speech_pre_training.py script for this, which contains the following lines:"],"metadata":{"id":"OxxEwR05XatQ"}},{"cell_type":"code","metadata":{"id":"WbnVpz03Jxto"},"source":["import pytorch_lightning as pl\n","from omegaconf import OmegaConf\n","\n","from nemo.collections.asr.models.ssl_models import SpeechEncDecSelfSupervisedModel\n","from nemo.core.config import hydra_runner\n","from nemo.utils import logging\n","from nemo.utils.exp_manager import exp_manager\n","\n","from nemo.collections.asr.models.ssl_models import SpeechEncDecSelfSupervisedModel\n","from nemo.core.config import hydra_runner\n","from nemo.utils import logging\n","from nemo.utils.exp_manager import exp_manager\n","\n","trainer = pl.Trainer(**cfg.trainer)\n","exp_manager(trainer, cfg.get(\"exp_manager\", None))\n","asr_model = SpeechEncDecSelfSupervisedModel(cfg=cfg.model, trainer=trainer)\n","\n","trainer.fit(asr_model)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","source":["# Fine-tuning with pre-trained encoder"],"metadata":{"id":"FylnQvwvKIy9"}},{"cell_type":"markdown","source":["Now that we have pre-trained our encoder, we can fine-tune our model with a supervised objective. Normally the dataset used for pre-training will be large and unlabeled, while the one used for fine-tuning will be a smaller labeled dataset. For the purpose of this tutorial we will just use the same dataset for fine-tuning."],"metadata":{"id":"RvhsJbsiKNj6"}},{"cell_type":"markdown","metadata":{"id":"Rk7uDmuHAD2e"},"source":["## Building tokenizer"]},{"cell_type":"code","metadata":{"id":"9WsIHRVVADZu"},"source":["!mkdir scripts\n","!wget -P scripts/ https://raw.githubusercontent.com/NVIDIA/NeMo/main/scripts/tokenizers/process_asr_text_tokenizer.py\n","\n","!python ./scripts/process_asr_text_tokenizer.py \\\n"," --manifest=\"{data_dir}/an4/train_manifest.json\" \\\n"," --data_root=\"{data_dir}/tokenizers/an4/\" \\\n"," --vocab_size=32 \\\n"," --tokenizer=\"spe\" \\\n"," --no_lower_case \\\n"," --spe_type=\"unigram\" \\\n"," --log"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","source":["## Creating config for fine-tuning with CTC objective\n","\n","We will now create a config for a ctc-based model with a matching encoder to the model we pre-trained."],"metadata":{"id":"Na0iuLoQMfgj"}},{"cell_type":"code","metadata":{"id":"tzF8uOWOoqeO"},"source":["config_path = './configs/citrinet_1024.yaml'\n","\n","cfg = OmegaConf.load(config_path)\n","\n","cfg.model.model_defaults.filters = 256\n","cfg.model.model_defaults.repeat = 1\n","cfg.model.model_defaults.enc_final = 256\n","cfg.model.optim.weight_decay = 0\n","cfg.model.optim.sched.warmup_steps = 500\n","\n","cfg.model.spec_augment.freq_masks = 0\n","cfg.model.spec_augment.time_masks = 5\n","\n","cfg.model.train_ds.manifest_filepath = \"/content/an4/train_manifest.json\"\n","cfg.model.train_ds.batch_size = 16\n","\n","cfg.model.validation_ds.manifest_filepath = \"/content/an4/test_manifest.json\"\n","cfg.model.validation_ds.batch_size = 16\n","\n","cfg.trainer.max_epochs = None\n","cfg.trainer.max_steps = 2000 \n","\n","if torch.cuda.is_available():\n"," cfg.trainer.gpus = 1\n"," cfg.trainer.accelerator = 'dp'\n","else:\n"," cfg.trainer.gpus = 0\n","\n","cfg.model.tokenizer.dir = data_dir + \"/tokenizers/an4/tokenizer_spe_unigram_v32/\" # note this is a directory, not a path to a vocabulary file\n","cfg.model.tokenizer.type = \"bpe\"\n","\n","cfg.exp_manager.exp_dir = \"/content/exp\"\n","cfg.exp_manager.name = \"fine_tuned\"\n","cfg.exp_manager.use_datetime_version = False\n","cfg.exp_manager.create_tensorboard_logger = False\n","cfg.exp_manager.resume_if_exists = True\n","cfg.exp_manager.resume_ignore_no_checkpoint = True\n","cfg.exp_manager.checkpoint_callback_params.save_best_model = True"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","source":["In order to load our encoder, we add the following to the config. We need to set init_strict to False, since the decoder for this model will be different, in order to have the correct output for ctc."],"metadata":{"id":"i3-_tFGDNPvZ"}},{"cell_type":"code","source":["cfg.init_from_nemo_model=\"/content/exp/pre_trained/checkpoints/pre_trained.nemo\"\n","cfg.init_strict = False"],"metadata":{"id":"3GKv7ERxNPRc"},"execution_count":null,"outputs":[]},{"cell_type":"code","source":["cfg = OmegaConf.to_container(cfg, resolve=True)\n","cfg = OmegaConf.create(cfg)"],"metadata":{"id":"MOZmD9sjNgfX"},"execution_count":null,"outputs":[]},{"cell_type":"markdown","source":["## Fine-tuning the model"],"metadata":{"id":"InacQMmE8tPZ"}},{"cell_type":"markdown","source":["Initializing our model from config:"],"metadata":{"id":"l3eNBs_sNhjE"}},{"cell_type":"code","metadata":{"id":"IEScq3t_vB6N"},"source":["from nemo.collections.asr.models.ctc_bpe_models import EncDecCTCModelBPE\n","\n","trainer = pl.Trainer(**cfg.trainer)\n","exp_manager(trainer, cfg.get(\"exp_manager\", None))\n","asr_model = EncDecCTCModelBPE(cfg=cfg.model, trainer=trainer)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","source":["Loading our pre-trained checkpoint:"],"metadata":{"id":"uif9DLOQ8d0b"}},{"cell_type":"code","metadata":{"id":"Jes4vqx4vLRC"},"source":["asr_model.maybe_init_from_pretrained_checkpoint(cfg)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","source":["Now we can run fine-tuning."],"metadata":{"id":"GdoIbsLn8gNC"}},{"cell_type":"code","metadata":{"id":"AACa0T6jJtMQ"},"source":["trainer.fit(asr_model)"],"execution_count":null,"outputs":[]}]} |