Using data exploration, data analysis and machine learning.
Main objective of the analysis is prediction and interpretation of juvenile crime in India and deciding efficient allocation of resources in the right areas to minimise the crime rate.
Dataset we have considered:Github
Following link contains processed data of various crime in separate csv file. From which we have considered csv which contains information about juvenile crime:Kaggle
Following link contains the original unprocessed data of various crime in separate csv file:NCRB
The dataset contains different sub datasets, each of these sub datasets holds the aggregate value of crime recorded from 2001 to 2010 and are split on various categories. On sub-dataset divided based on:
- Age-group and type of crime
- Background
- Recidivism The kaggle dataset was preprocessed, various combinations of datasets was used to train the model and address various issues.
Given state, crime(mapping required, not considered for now), age, gender, predicting the possibility of SLL(Naive bias using above data + ARIMA to predict current year using previous year data)
SLL by parima

Boys

Girls

Relation between punishment and recidivism (Linear Regression)
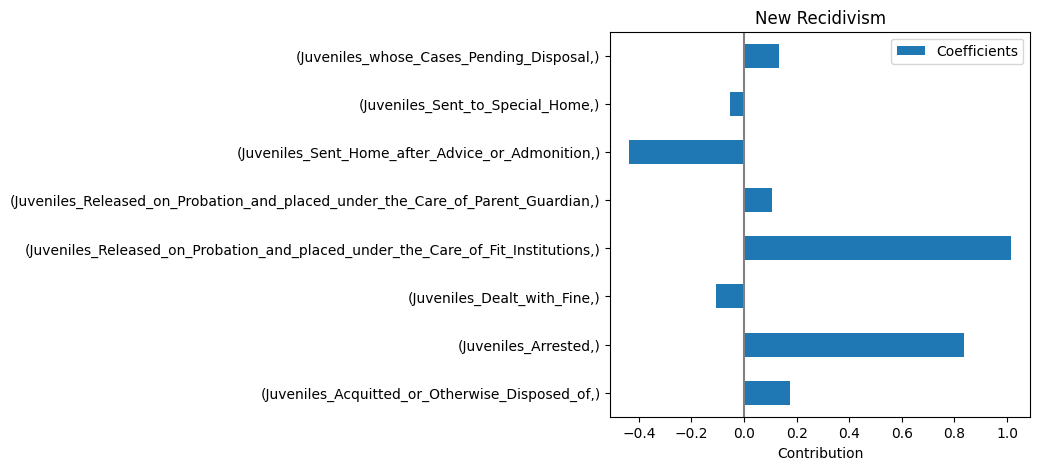
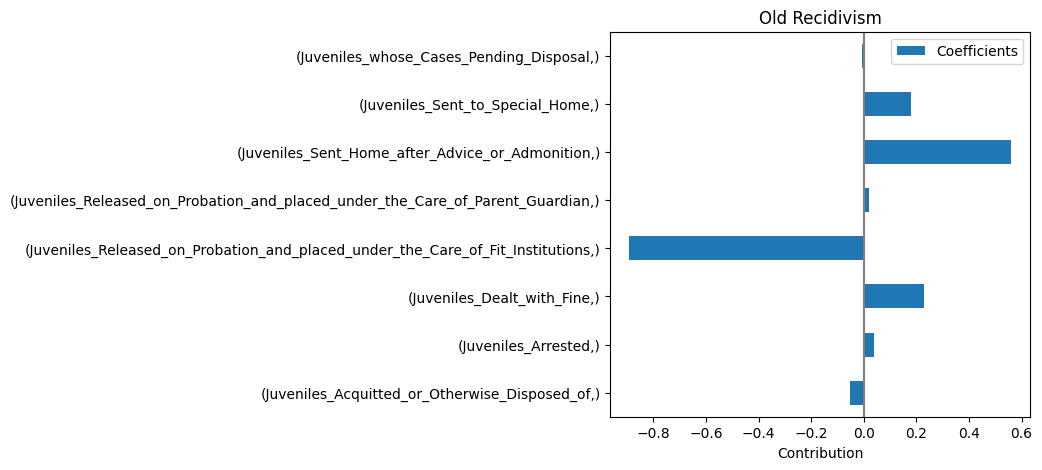
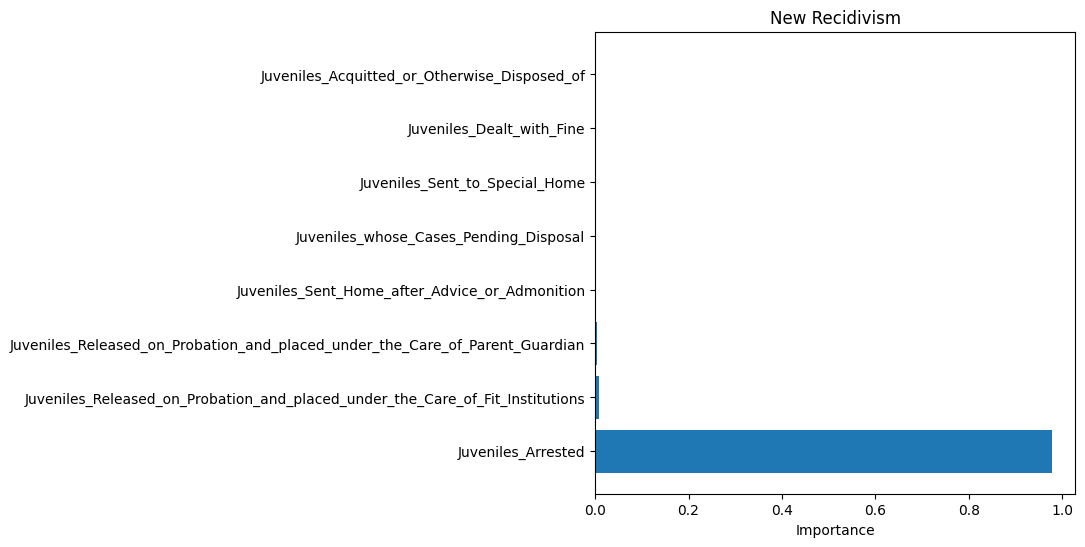
Relation between punishment and recidivism (Random Forest)

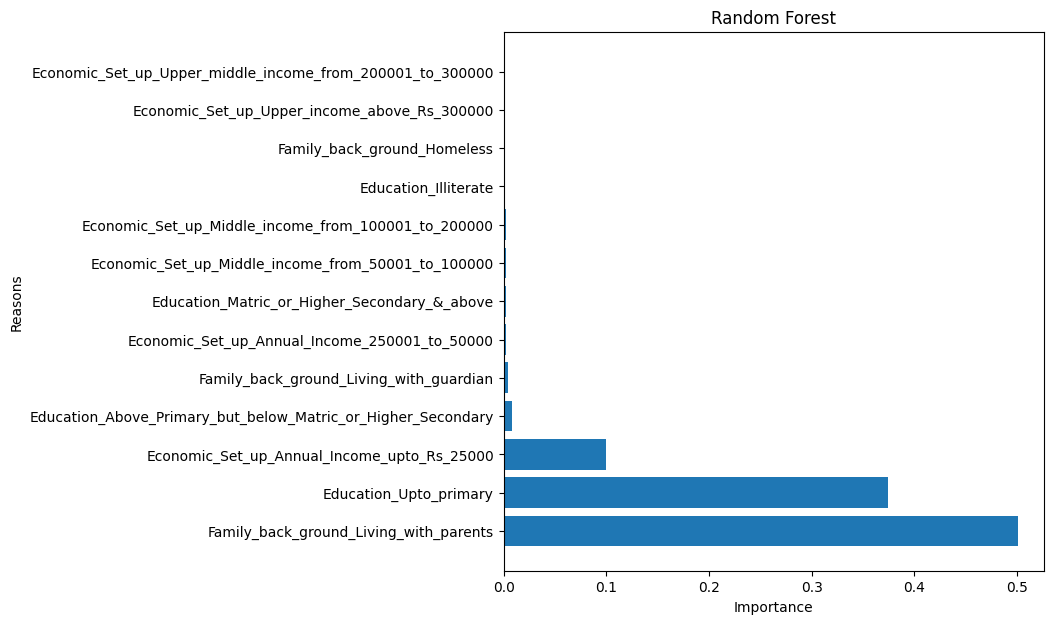
Background of juveniles committing crime

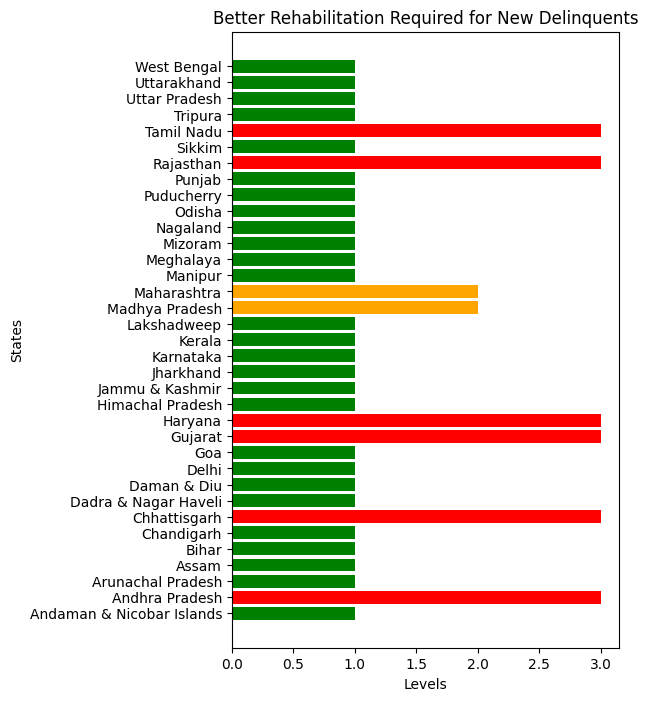

Recidivism by parima

Naive Bayes Result

The next step is to streamline the data analysis process by improving the collection method of data or aggregation of various data. Better interpretations can be made with more abstract data. A lot of key information is lost in the current format of data aggregation.