
"We need more speed" - Lightning McQueen or Scarface, I don't know
![]()
Parallel algorithm building blocks for the Julia ecosystem, targeting multithreaded CPUs, and GPUs via Intel oneAPI, AMD ROCm, Apple Metal and Nvidia CUDA (and any future backends added to the JuliaGPU organisation) from a unified KernelAbstractions.jl codebase.
| AcceleratedKernels Backend | Julia Version | CI Status |
|---|---|---|
|
CPU Single- and Multi-Threaded |
Julia LTS, Stable, Pre-Release x86, x64, aarch64 Windows, Ubuntu, MacOS |
|
|
Julia v1.10 |
|
|
|
Julia v1.11 |
|
|
|
Julia v1.10 |
|
|
|
Julia v1.11 |
|
|
|
Julia v1.10 |
|
|
|
Julia v1.11 |
|
|
|
Julia v1.10 |
|
|
|
Julia v1.11 |
|
- 1. What's Different?
- 2. Status
- 3. Benchmarks
- 4. Functions Implemented
- 5. API Examples
- 6. Custom Structs
- 7. Testing
- 8. Issues and Debugging
- 9. Roadmap / Future Plans
- 10. References
- 11. Acknowledgements
- 12. License
As far as I am aware, this is the first cross-architecture parallel standard library from a unified codebase - that is, the code is written as KernelAbstractions.jl backend-agnostic kernels, which are then transpiled to a GPU backend; that means we benefit from all the optimisations available on the native platform and official compiler stacks. For example, unlike open standards like OpenCL that require GPU vendors to implement that API for their hardware, we target the existing official compilers. And while performance-portability libraries like Kokkos and RAJA are powerful for large C++ codebases, they require US National Lab-level development and maintenance efforts to effectively forward calls from a single API to other OpenMP, CUDA Thrust, ROCm rocThrust, oneAPI DPC++ libraries developed separately. In comparison, this library was developed effectively in a week by a single person because developing packages in Julia is just a joy.
Again, this is only possible because of the unique Julia compilation model, the JuliaGPU organisation work for reusable GPU backend infrastructure, and especially the KernelAbstractions.jl backend-agnostic kernel language. Thank you.
The AcceleratedKernels.jl sorters were adopted as the official AMDGPU algorithms! The API is starting to stabilise; it follows the Julia standard library fairly closely - and additionally exposing all temporary arrays for memory reuse. For any new ideas / requests, please join the conversation on Julia Discourse or post an issue.
We have an extensive randomised test suite that we run on the CPU (single- and multi-threaded) backend on Windows, Ubuntu and MacOS for Julia LTS, Stable, and Pre-Release, plus the CUDA, AMDGPU, oneAPI and Metal backends on the JuliaGPU buildkite.
AcceleratedKernels.jl is also be a fundamental building block of applications developed at EvoPhase, so it will see continuous heavy use with industry backing. Long-term stability, performance improvements and support are priorities for us.
Some arithmetic-heavy benchmarks are given below - see this repository for the code; our paper will be linked here upon publishing with a full analysis.

See protoype/sort_benchmark.jl for a small-scale sorting benchmark code and prototype/thrust_sort for the Nvidia Thrust wrapper. The results below are from a system with Linux 6.6.30-2-MANJARO, Intel Core i9-10885H CPU, Nvidia Quadro RTX 4000 with Max-Q Design GPU, Thrust 1.17.1-1, Julia Version 1.10.4.

As a first implementation in AcceleratedKernels.jl, we are on the same order of magnitude as Nvidia's official sorter (x3.48 slower), and an order of magnitude faster (x10.19) than the Julia Base CPU radix sort (which is already one of the fastest).
The sorting algorithms can also be combined with MPISort.jl for multi-device sorting - indeed, you can co-operatively sort using both your CPU and GPU! Or use 200 GPUs on the 52 nodes of Baskerville HPC to sort 538-855 GB of data per second (comparable with the highest figure reported in literature of 900 GB/s on 262,144 CPU cores):
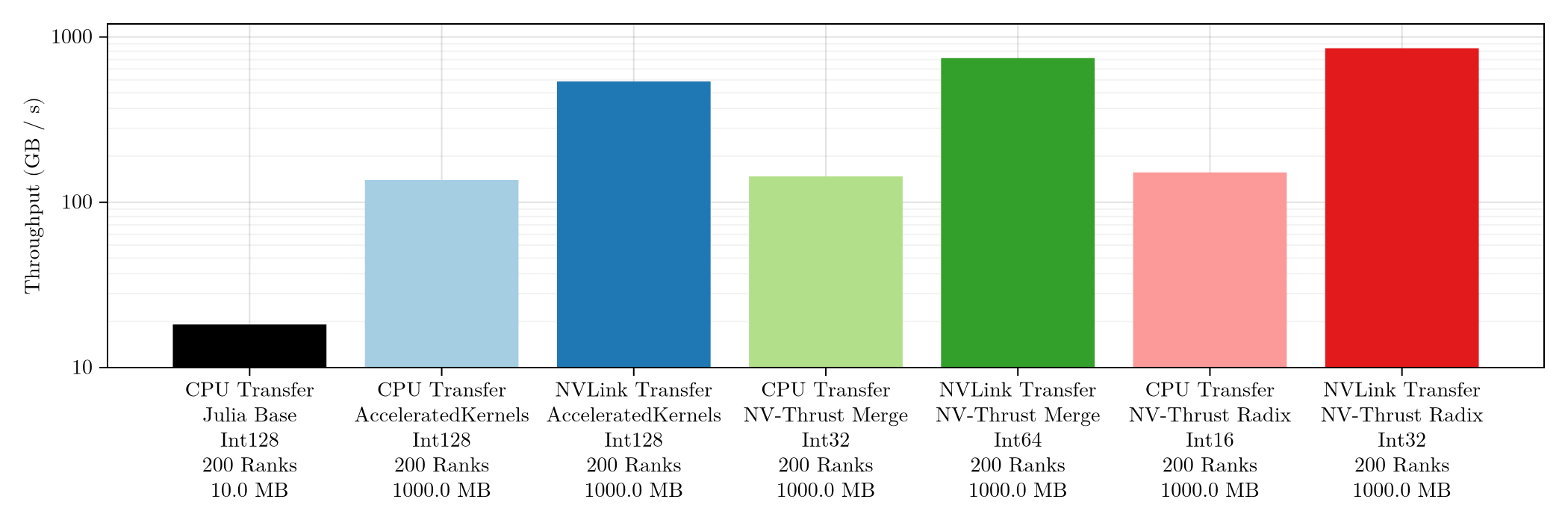
Hardware stats for nerds available here. Full analysis will be linked here once our paper is published.
Below is an overview of the currently-implemented algorithms, along with some common names in other libraries for ease of finding / understanding / porting code. If you need other algorithms in your work that may be of general use, please open an issue and we may implement it, help you implement it, or integrate existing code into AcceleratedKernels.jl. See API Examples below for usage.
| Function Family | AcceleratedKernels.jl Functions | Other Common Names |
|---|---|---|
| General Looping | foreachindex, foraxes |
Kokkos::parallel_for RAJA::forall thrust::transform |
| Mapping | map map! |
thrust::transform |
| Sorting | sort sort! |
sort sort_team stable_sort |
merge_sort merge_sort! |
||
merge_sort_by_key merge_sort_by_key! |
sort_team_by_key |
|
sortperm sortperm! |
sort_permutation index_permutation |
|
merge_sortperm merge_sortperm! |
||
merge_sortperm_lowmem merge_sortperm_lowmem! |
||
| Reduction | reduce |
Kokkos:parallel_reduce fold aggregate |
| MapReduce | mapreduce |
transform_reduce fold |
| Accumulation | accumulate accumulate! |
prefix_sum thrust::scan cumsum |
| Binary Search | searchsortedfirst searchsortedfirst! |
std::lower_bound |
searchsortedlast searchsortedlast! |
thrust::upper_bound |
|
| Predicates | all any |
Here are simple examples using the AcceleratedKernels.jl algorithms to help you get started with it quickly; more details on the function arguments are given in the Manual.
For any of the examples below, simply use a different GPU array and AcceleratedKernels.jl will pick the right backend:
# Intel Graphics
using oneAPI
v = oneArray{Int32}(undef, 100_000) # Empty array
# AMD ROCm
using AMDGPU
v = ROCArray{Float64}(1:100_000) # A range converted to Float64
# Apple Metal
using Metal
v = MtlArray(rand(Float32, 100_000)) # Transfer from host to device
# NVidia CUDA
using CUDA
v = CuArray{UInt32}(0:5:100_000) # Range with explicit step size
# Transfer GPU array back
v_host = Array(v)All publicly-exposed functions have CPU implementations with unified parameter interfaces:
import AcceleratedKernels as AK
v = Vector(-1000:1000) # Normal CPU array
AK.reduce(+, v, max_tasks=Threads.nthreads())Note the reduce and mapreduce CPU implementations forward arguments to OhMyThreads.jl, an excellent package for multithreading. The focus of AcceleratedKernels.jl is to provide a unified interface to high-performance implementations of common algorithmic kernels, for both CPUs and GPUs - if you need fine-grained control over threads, scheduling, communication for specialised algorithms (e.g. with highly unequal workloads), consider using OhMyThreads.jl or KernelAbstractions.jl directly.
There is ongoing work on multithreaded CPU sort and accumulate implementations - at the moment, they fall back to single-threaded algorithms; the rest of the library is fully parallelised for both CPUs and GPUs.
General workhorses for converting normal Julia for loops into GPU code, for example:
| CPU Code | GPU code |
|---|---|
# Copy kernel testing throughput
function cpu_copy!(dst, src)
for i in eachindex(src)
dst[i] = src[i]
end
end |
import AcceleratedKernels as AK
function gpu_copy!(dst, src)
AK.foreachindex(src) do i
dst[i] = src[i]
end
end |
Yes, simply change for i in eachindex(itr) into AK.foreachindex(itr) do i to run it on GPUs / multithreaded - magic! (or just amazing language design)
This is a parallelised for-loop over the indices of an iterable; converts normal Julia code to GPU kernels running one thread per index. On CPUs it executes static index ranges on max_tasks threads, with user-defined min_elems to be processed by each thread; if only a single thread ends up being needed, the loop is inlined and executed without spawning threads.
- Other names:
Kokkos::parallel_for,RAJA::forall,thrust::transform.
Function signature:
foreachindex(
f, itr, backend::Backend=get_backend(itr);
# CPU settings
scheduler=:threads,
max_tasks=Threads.nthreads(),
min_elems=1,
# GPU settings
block_size=256,
)Example:
import AcceleratedKernels as AK
function f(a, b)
# Don't use global arrays inside a `foreachindex`; types must be known
@assert length(a) == length(b)
AK.foreachindex(a) do i
# Note that we don't have to explicitly pass b into the lambda
if b[i] > 0.5
a[i] = 1
else
a[i] = 0
end
# Showing arbitrary if conditions; can also be written as:
# @inbounds a[i] = b[i] > 0.5 ? 1 : 0
end
end
# Use any backend, e.g. CUDA, ROCm, oneAPI, Metal, or CPU
using oneAPI
v1 = oneArray{Float32}(undef, 100_000)
v2 = oneArray(rand(Float32, 100_000))
f(v1, v2)All GPU functions allow you to specify a block size - this is often a power of two (mostly 64, 128, 256, 512); the optimum depends on the algorithm, input data and hardware - you can try the different values and @time or @benchmark them:
@time AK.foreachindex(f, itr_gpu, block_size=512)Similarly, for performance on the CPU the overhead of spawning threads should be masked by processing more elements per thread (but there is no reason here to launch more threads than Threads.nthreads(), the number of threads Julia was started with); the optimum depends on how expensive f is - again, benchmarking is your friend:
@time AK.foreachindex(f, itr_cpu, max_tasks=16, min_elems=1000)To iterate over the indices along a dimension of an array, similar to axes(itr, dims), you can use foraxes. Function signature:
foraxes(
f, itr, dims::Union{Nothing, <:Integer}=nothing, backend::Backend=get_backend(itr);
# CPU settings
scheduler=:threads,
max_tasks=Threads.nthreads(),
min_elems=1,
# GPU settings
block_size=256,
)Example:
using CUDA
import AcceleratedKernels as AK
function outer_set!(y, x)
AK.foraxes(x, 2) do i
for j in axes(x, 1)
@inbounds y[j, i] = 2 * x[j, i] + 1
end
end
end
x = CuArray(reshape(1:3000, 3, 1000))
y = similar(x)
outer_set!(y, x)Parallel mapping of a function over each element of an iterable via foreachindex:
map!(in-place),map(out-of-place)
Function signature:
map!(
f, dst::AbstractArray, src::AbstractArray;
# CPU settings
scheduler=:threads,
max_tasks=Threads.nthreads(),
min_elems=1,
# GPU settings
block_size=256,
)Example:
import Metal
import AcceleratedKernels as AK
x = MtlArray(rand(Float32, 100_000))
y = similar(x)
AK.map!(y, x) do x_elem
T = typeof(x_elem)
T(2) * x_elem + T(1)
endSorting algorithms with similar interface and default settings as the Julia Base ones, on GPUs:
sort!(in-place),sort(out-of-place)sortperm!,sortperm- Other names:
sort,sort_team,sort_team_by_key,stable_sortor variations in Kokkos, RAJA, Thrust that I know of.
Function signature:
sort!(v::AbstractGPUVector;
lt=isless, by=identity, rev::Bool=false, order::Base.Order.Ordering=Base.Order.Forward,
block_size::Int=256, temp::Union{Nothing, AbstractGPUVector}=nothing)
sortperm!(ix::AbstractGPUVector, v::AbstractGPUVector;
lt=isless, by=identity, rev::Bool=false, order::Base.Order.Ordering=Base.Order.Forward,
block_size::Int=256, temp::Union{Nothing, AbstractGPUVector}=nothing)Specific implementations that the interfaces above forward to:
merge_sort!(in-place),merge_sort(out-of-place) - sort arbitrary objects with custom comparisons.merge_sort_by_key!,merge_sort_by_key- sort a vector of keys along with a "payload", a vector of corresponding values.merge_sortperm!,merge_sortperm,merge_sortperm_lowmem!,merge_sortperm_lowmem- compute a sorting index permutation.
Function signature:
merge_sort!(v::AbstractGPUVector;
lt=(<), by=identity, rev::Bool=false, order::Ordering=Forward,
block_size::Int=256, temp::Union{Nothing, AbstractGPUVector}=nothing)
merge_sort_by_key!(keys::AbstractGPUVector, values::AbstractGPUVector;
lt=(<), by=identity, rev::Bool=false, order::Ordering=Forward,
block_size::Int=256,
temp_keys::Union{Nothing, AbstractGPUVector}=nothing,
temp_values::Union{Nothing, AbstractGPUVector}=nothing)
merge_sortperm!(ix::AbstractGPUVector, v::AbstractGPUVector;
lt=(<), by=identity, rev::Bool=false, order::Ordering=Forward,
inplace::Bool=false, block_size::Int=256,
temp_ix::Union{Nothing, AbstractGPUVector}=nothing,
temp_v::Union{Nothing, AbstractGPUVector}=nothing)
merge_sortperm_lowmem!(ix::AbstractGPUVector, v::AbstractGPUVector;
lt=(<), by=identity, rev::Bool=false, order::Ordering=Forward,
block_size::Int=256,
temp::Union{Nothing, AbstractGPUVector}=nothing)Example:
import AcceleratedKernels as AK
using AMDGPU
v = ROCArray(rand(Int32, 100_000))
AK.sort!(v)As GPU memory is more expensive, all functions in AcceleratedKernels.jl expose any temporary arrays they will use (the temp argument); you can supply your own buffers to make the algorithms not allocate additional GPU storage, e.g.:
v = ROCArray(rand(Float32, 100_000))
temp = similar(v)
AK.sort!(v, temp=temp)Apply a custom binary operator reduction on all elements in an iterable; can be used to compute minima, sums, counts, etc.
- Other names:
Kokkos:parallel_reduce,fold,aggregate.
New in AcceleratedKernels 0.2.0: N-dimensional reductions via the dims keyword
Function signature:
reduce(
op, src::AbstractArray;
init,
dims::Union{Nothing, Int}=nothing,
# CPU settings
scheduler=:static,
max_tasks=Threads.nthreads(),
min_elems=1,
# GPU settings
block_size::Int=256,
temp::Union{Nothing, AbstractGPUArray}=nothing,
switch_below::Int=0,
)Example computing a sum:
import AcceleratedKernels as AK
using CUDA
v = CuArray{Int16}(rand(1:1000, 100_000))
AK.reduce((x, y) -> x + y, v; init=0)In a GPU scalar reduction there end up being very few elements to process towards the end; it is sometimes faster to transfer the last few elements to the CPU and finish there (in a reduction we have to do a device-to-host transfer anyways for the final result); switch_below may be worth using (benchmark!) - here computing a minimum with the reduction operator defined in a Julia do block:
AK.reduce(v; init=typemax(eltype(v)), switch_below=100) do x, y
x < y ? x : y
endYes, the lambda within the do block can equally well be executed on both CPU and GPU, no code changes/duplication required.
Equivalent to reduce(op, map(f, iterable)), without saving the intermediate mapped collection; can be used to e.g. split documents into words (map) and count the frequency thereof (reduce).
- Other names:
transform_reduce, somefoldimplementations include the mapping function too.
New in AcceleratedKernels 0.2.0: N-dimensional reductions via the dims keyword
Function signature:
mapreduce(
f, op, src::AbstractArray;
init,
dims::Union{Nothing, Int}=nothing,
# CPU settings
scheduler=:static,
max_tasks=Threads.nthreads(),
min_elems=1,
# GPU settings
block_size::Int=256,
temp::Union{Nothing, AbstractArray}=nothing,
switch_below::Int=0,
)Example computing the minimum of absolute values:
import AcceleratedKernels as AK
using Metal
v = MtlArray{Int32}(rand(-5:5, 100_000))
AK.mapreduce(abs, (x, y) -> x < y ? x : y, v, init=typemax(Int32))As for reduce, when there are fewer than switch_below elements left to reduce, they can be copied back to the host and we switch to a CPU reduction. The init initialiser has to be a neutral element for op, i.e. same type as returned from f (f can change the type of the collection, see the "Custom Structs" section below for an example). The temporary array temp needs to have at least (length(src) + 2 * block_size - 1) ÷ (2 * block_size) elements and have eltype(src) === typeof(init).
Compute accumulated running totals along a sequence by applying a binary operator to all elements up to the current one; often used in GPU programming as a first step in finding / extracting subsets of data.
accumulate!(in-place),accumulate(allocating); inclusive or exclusive.- Other names: prefix sum,
thrust::scan, cumulative sum; inclusive (or exclusive) if the first element is included in the accumulation (or not).
Function signature:
accumulate!(op, v::AbstractGPUVector; init, inclusive::Bool=true,
block_size::Int=256,
temp::Union{Nothing, AbstractGPUVector}=nothing,
temp_flags::Union{Nothing, AbstractGPUVector}=nothing)
accumulate(op, v::AbstractGPUVector; init, inclusive::Bool=true,
block_size::Int=256,
temp::Union{Nothing, AbstractGPUVector}=nothing,
temp_flags::Union{Nothing, AbstractGPUVector}=nothing)Example computing an inclusive prefix sum (the typical GPU "scan"):
import AcceleratedKernels as AK
using oneAPI
v = oneAPI.ones(Int32, 100_000)
AK.accumulate!(+, v, init=0)The temporaries temp and temp_flags should both have at least (length(v) + 2 * block_size - 1) ÷ (2 * block_size) elements; eltype(v) === eltype(temp); the elements in temp_flags can be any integers, but Int8 is used by default to reduce memory usage.
Find the indices where some elements x should be inserted into a sorted sequence v to maintain the sorted order. Effectively applying the Julia.Base functions in parallel on a GPU using foreachindex.
searchsortedfirst!(in-place),searchsortedfirst(allocating): index of first element inv>=x[j].searchsortedlast!,searchsortedlast: index of last element inv<=x[j].- Other names:
thrust::upper_bound,std::lower_bound.
Function signature:
# GPU
searchsortedfirst!(ix::AbstractGPUVector, v::AbstractGPUVector, x::AbstractGPUVector;
by=identity, lt=(<), rev::Bool=false,
block_size::Int=256)
searchsortedfirst(v::AbstractGPUVector, x::AbstractGPUVector;
by=identity, lt=(<), rev::Bool=false,
block_size::Int=256)
searchsortedlast!(ix::AbstractGPUVector, v::AbstractGPUVector, x::AbstractGPUVector;
by=identity, lt=(<), rev::Bool=false,
block_size::Int=256)
searchsortedlast(v::AbstractGPUVector, x::AbstractGPUVector;
by=identity, lt=(<), rev::Bool=false,
block_size::Int=256)
# CPU
searchsortedfirst!(ix::AbstractVector, v::AbstractVector, x::AbstractVector;
by=identity, lt=(<), rev::Bool=false,
max_tasks::Int=Threads.nthreads(), min_elems::Int=1000)
searchsortedfirst(v::AbstractVector, x::AbstractVector;
by=identity, lt=(<), rev::Bool=false,
max_tasks::Int=Threads.nthreads(), min_elems::Int=1000)
searchsortedlast!(ix::AbstractVector, v::AbstractVector, x::AbstractVector;
by=identity, lt=(<), rev::Bool=false,
max_tasks::Int=Threads.nthreads(), min_elems::Int=1000)
searchsortedlast(v::AbstractVector, x::AbstractVector;
by=identity, lt=(<), rev::Bool=false,
max_tasks::Int=Threads.nthreads(), min_elems::Int=1000)Example:
import AcceleratedKernels as AK
using Metal
# Sorted array
v = MtlArray(rand(Float32, 100_000))
AK.merge_sort!(v)
# Elements `x` to place within `v` at indices `ix`
x = MtlArray(rand(Float32, 10_000))
ix = MtlArray{Int}(undef, 10_000)
AK.searchsortedfirst!(ix, v, x)Apply a predicate to check if all / any elements in a collection return true. Could be implemented as a reduction, but is better optimised with stopping the search once a false / true is found.
- Other names: not often implemented standalone on GPUs, typically included as part of a reduction.
Function signature:
any(pred, v::AbstractGPUVector;
block_size::Int=256, cooperative::Bool=true)
all(pred, v::AbstractGPUVector;
block_size::Int=256, cooperative::Bool=true)Example:
import AcceleratedKernels as AK
using CUDA
v = CuArray(rand(Float32, 100_000))
AK.any(x -> x < 1, v)
AK.all(x -> x > 0, v)As functions are compiled as/when used in Julia for the given argument types (for C++ people: kind of like everything being a template argument by default), we can use custom structs and functions defined outside AcceleratedKernels.jl, which will be inlined and optimised as if they were hardcoded within the library. Normal Julia functions and code can be used, without special annotations like __device__, KOKKOS_LAMBDA or wrapping them in classes with overloaded operator().
As an example, let's compute the coordinate-wise minima of some points:
import AcceleratedKernels as AK
using Metal
struct Point
x::Float32
y::Float32
end
function compute_minima(points)
AK.mapreduce(
point -> (point.x, point.y), # Extract fields into tuple
(a, b) -> (min(a[1], b[1]), min(a[2], b[2])), # Keep each coordinate's minimum
points,
init=(typemax(Float32), typemax(Float32)),
)
end
# Example output for Random.seed!(0):
# minima = compute_minima(points) = (1.7966056f-5, 1.7797855f-6)
points = MtlArray([Point(rand(), rand()) for _ in 1:100_000])
@show minima = compute_minima(points)Note that we did not have to explicitly type the function arguments in compute_minima - the types would be figured out when calling the function and compiled for the right backend automatically, e.g. CPU, oneAPI, ROCm, CUDA, Metal. Also, we used the standard Julia function min; it was not special-cased anywhere, it's just KernelAbstractions.jl inlining and compiling normal code, even from within the Julia.Base standard library.
If it ain't tested, it's broken. The test/runtests.jl suite does randomised correctness testing on all algorithms in the library. To test locally, execute:
$> julia -e 'import Pkg; Pkg.develop(path="path/to/AcceleratedKernels.jl"); Pkg.add("oneAPI")'
$> julia -e 'import Pkg; Pkg.test("AcceleratedKernels.jl", test_args=["--oneAPI"])'Replace the "--oneAPI" with "--CUDA", "--AMDGPU" or "--Metal" to test different backends, as available on your machine.
Leave out to test the CPU backend:
$> julia -e 'import Pkg; Pkg.test("AcceleratedKernels.jl")As the compilation pipeline of GPU kernels is different to that of base Julia, error messages also look different - for example, where Julia would insert an exception when a variable name was not defined (e.g. we had a typo), a GPU kernel throwing exceptions cannot be compiled and instead you'll see some cascading errors like "[...] compiling [...] resulted in invalid LLVM IR" caused by "Reason: unsupported use of an undefined name" resulting in "Reason: unsupported dynamic function invocation", etc.
Thankfully, there are only about 3 types of such error messages and they're not that scary when you look into them. See the Manual section on debugging for examples and explanations.
For other library-related problems, feel free to post a GitHub issue. For help implementing new code, or just advice, you can also use the Julia Discourse forum, the community is incredibly helpful.
Help is very welcome for any of the below:
- Automated optimisation / tuning of e.g.
block_sizefor a given input; can be made algorithm-agnostic.- Maybe some thing like
AK.@tune reduce(f, src, init=init, block_size=$block_size) block_size=(64, 128, 256, 512, 1024). Macro wizards help! - Or make it general like:
AK.@tune begin reduce(f, src, init=init, block_size=$block_size, switch_below=$switch_below) block_size=(64, 128, 256, 512, 1024) switch_below=(1, 10, 100, 1000, 10000) end
- Maybe some thing like
- Add performant multithreaded Julia implementations to all algorithms; e.g.
foreachindexhas one,anydoes not. - Any way to expose the warp-size from the backends? Would be useful in reductions.
- Define default
initvalues for often-used reductions? Or just expose higher-level functions likesum,minimum, etc.? - Add a performance regressions runner.
- Other ideas? Post an issue, or open a discussion on the Julia Discourse.
This library is built on the unique Julia infrastructure for transpiling code to GPU backends, and years spent developing the JuliaGPU ecosystem that make it a joy to use. In particular, credit should go to the following people and work:
- The Julia language design, which made code manipulation and generation a first class citizen: Bezanson J, Edelman A, Karpinski S, Shah VB. Julia: A fresh approach to numerical computing. SIAM review. 2017.
- The GPU compiler infrastructure built on top of Julia's unique compilation model: Besard T, Foket C, De Sutter B. Effective extensible programming: unleashing Julia on GPUs. IEEE Transactions on Parallel and Distributed Systems. 2018.
- The KernelAbstractions.jl library with its unique backend-agnostic compilation: Churavy V, Aluthge D, Wilcox LC, Schloss J, Byrne S, Waruszewski M, Samaroo J, Ramadhan A, Meredith SS, Bolewski J, Smirnov A. JuliaGPU/KernelAbstractions. jl: v0.8.3.
- For distributed applications, the MPI.jl library which makes integrating GPU codes with multi-node communication so easy: Byrne S, Wilcox LC, Churavy V. MPI. jl: Julia bindings for the Message Passing Interface. InProceedings of the JuliaCon Conferences 2021.
If you use AcceleratedKernels.jl in publications, please cite the works above.
While the algorithms themselves were implemented anew, multiple existing libraries and resources were useful; in no particular order:
- Kokkos: https://github.com/kokkos/kokkos
- RAJA: https://github.com/LLNL/RAJA
- Thrust / CUDA C++ Core Libraries: https://github.com/nvidia/cccl
- ThrustRTC: https://github.com/fynv/ThrustRTC
- Optimizing parallel reduction in CUDA: https://developer.download.nvidia.com/assets/cuda/files/reduction.pdf
- Parallel prefix sum (scan) with CUDA: https://developer.download.nvidia.com/compute/cuda/2_2/sdk/website/projects/scan/doc/scan.pdf
- Parallel prefix sum (scan) with CUDA: https://github.com/mattdean1/cuda
- rocThrust: https://github.com/ROCm/rocThrust
- FidelityFX: https://github.com/GPUOpen-Effects/FidelityFX
- Intel oneAPI DPC++ library: https://www.intel.com/content/www/us/en/developer/tools/oneapi/dpc-library.html
- Metal performance shaders: https://developer.apple.com/documentation/metalperformanceshaders
Designed and built by Andrei-Leonard Nicusan, maintained with contributors.
Much of this work was possible because of the fantastic HPC resources at the University of Birmingham and the Birmingham Environment for Academic Research, which gave us free on-demand access to thousands of CPUs and GPUs that we experimented on, and the support teams we nagged. In particular, thank you to Kit Windows-Yule and Andrew Morris on the BlueBEAR and Baskerville T2 supercomputers' leadership, and Simon Branford, Simon Hartley, James Allsopp and James Carpenter for computing support.
AcceleratedKernels.jl is MIT-licensed. Enjoy.