This repository contains the implementation of AFS from:
Juexiao Zhou, et al. "A unified method to revoke the private data of patients in intelligent healthcare with audit to forget"

conda env create --file environment.yaml
The installation process takes about 10 minutes.
environment.yml: creating an environment from the environment.yml file
afs.py: the entry point of AFS
/utils: stores necessary functions
/template: examples of applying AFS
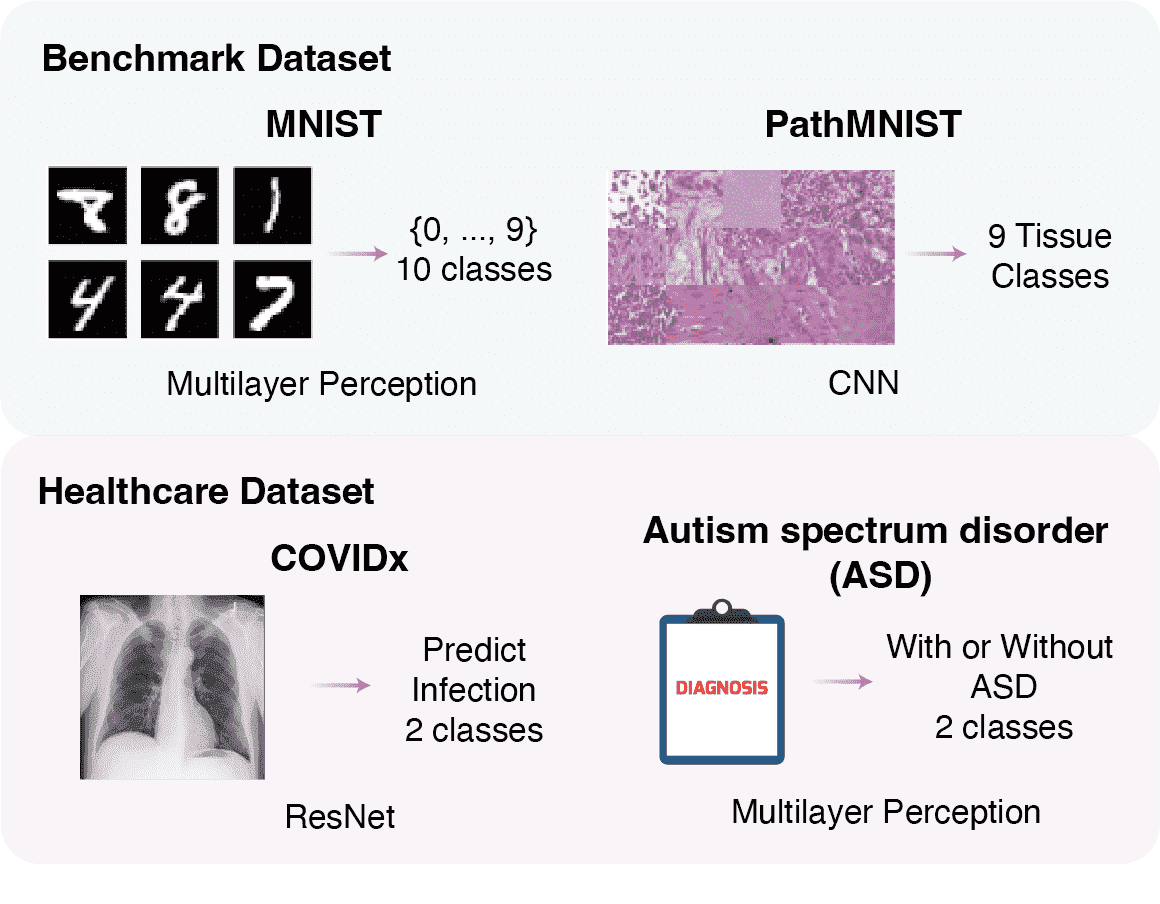
In this repositoty, we provided four examples, including MNIST, PathMNIST, COVIDx and ASD.
Taking the MNIST dataset as an example, to use AFS, we need to generate a pre-trained model first.
Go to /template/MNIST
Then run
python 01.Train.py \
--epoch 20 \
--mode base \
--expname EXP1 \
--base_label BASE1 \
--test_label TEST1
If users want to start with a new dataset from scratch, then those files 01.Train.py, Dataset.py, Model.py need to be modified accordingly.
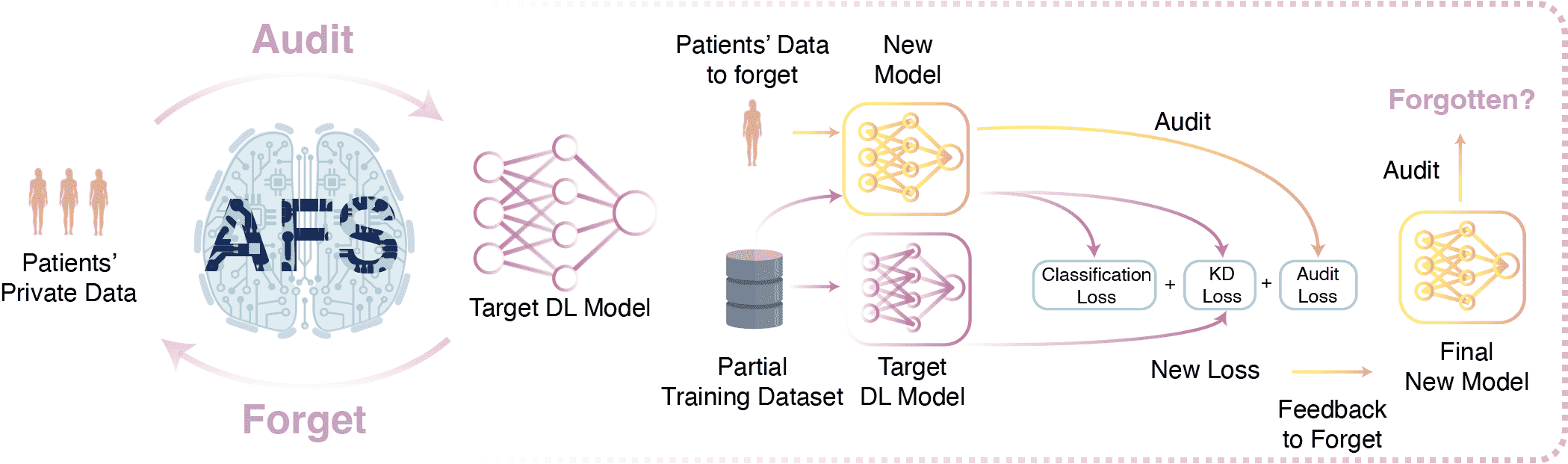
To audit, AFS takes a pre-trained DL model and the query dataset as inputs and will conclude whether the query dataset has been used for training the target DL model.
python afs.py audit --help
usage: AFS audit [-h] [--root ROOT] [--query_label QUERY_LABEL]
[--cal_label CAL_LABEL] [--cal_test_label CAL_TEST_LABEL]
[--test_label TEST_LABEL] [--model2audit MODEL2AUDIT]
[--model2cal MODEL2CAL] [--device DEVICE]
[--KP_infer_batch_size KP_INFER_BATCH_SIZE] [--nclass NCLASS]
[--num_workers NUM_WORKERS] [--command_class COMMAND_CLASS]
optional arguments:
-h, --help show this help message and exit
--root ROOT root dir to the project
--query_label QUERY_LABEL
label of the query data, defined in Dataset.py/Config
--cal_label CAL_LABEL
label of the calibration data, defined in
Dataset.py/Config
--cal_test_label CAL_TEST_LABEL
label of the calibration test data, defined in
Dataset.py/Config
--test_label TEST_LABEL
label of the test data, defined in Dataset.py/Config
--model2audit MODEL2AUDIT
relative path of model to be auditted to the root
--model2cal MODEL2CAL
relative path of the calibration model to the root
--device DEVICE
--KP_infer_batch_size KP_INFER_BATCH_SIZE
batch size for inference during membership attack
--nclass NCLASS number of classes
--num_workers NUM_WORKERS
number of num_workers
--command_class COMMAND_CLASS
for internal use only, no change
python afs.py audit \
--root ./template/MNIST \
--model2audit ./models/EXP1/BASE1/best_model.pth \
--nclass 10 \
--cal_label CAL_1000 \
--cal_test_label CALTEST1 \
--test_label TEST1 \
--query_label QF_100
python afs.py audit \
--root ./template/PathMNIST \
--model2audit ./models/EXP1/BASE1/best_model.pth \
--nclass 9 \
--cal_label CAL_1000 \
--cal_test_label CALTEST1 \
--test_label TEST1 \
--query_label QF_100
python afs.py audit \
--root ./template/COVIDx \
--model2audit ./models/EXP1/BASE1/best_model.pth \
--nclass 2 \
--cal_label CAL_1000 \
--cal_test_label CALTEST1 \
--test_label TEST1 \
--query_label QF_100
python afs.py audit \
--root ./template/ASD \
--model2audit ./models/EXP1/BASE1/best_model.pth \
--nclass 2 \
--cal_label CAL_100 \
--cal_test_label CALTEST1 \
--test_label TEST1 \
--query_label QF_100
To forget, AFS takes a pre-trained DL model and the query dataset to be forgotten as inputs, in which case users know that the query dataset has been used to train the DL model and want to remove the information of the query dataset from the target DL model.
python afs.py forget --help
usage: AFS forget [-h] [--root ROOT] [--expname EXPNAME]
[--teacher_model TEACHER_MODEL] [--KD_label KD_LABEL]
[--test_label TEST_LABEL] [--cal_label CAL_LABEL]
[--cal_test_label CAL_TEST_LABEL]
[--query_label QUERY_LABEL] [--add_risk_loss ADD_RISK_LOSS]
[--nclass NCLASS] [--train_batch_size TRAIN_BATCH_SIZE]
[--KP_infer_batch_size KP_INFER_BATCH_SIZE]
[--device DEVICE] [--epochs EPOCHS] [--T T] [--lr LR]
[--lambda_kd LAMBDA_KD] [--lambda_risk LAMBDA_RISK]
[--num_workers NUM_WORKERS] [--command_class COMMAND_CLASS]
optional arguments:
-h, --help show this help message and exit
--root ROOT root dir to the project
--expname EXPNAME name of exp, will affect the path and dataset
splitting
--teacher_model TEACHER_MODEL
relative path of model to be distilled to the root
--KD_label KD_LABEL the name of base dataset used for KD, should be
defined in CONFIG
--test_label TEST_LABEL
label of the test data, defined in Dataset.py/Config
--cal_label CAL_LABEL
label of the calibration data, defined in
Dataset.py/Config
--cal_test_label CAL_TEST_LABEL
label of the calibration test data, defined in
Dataset.py/Config
--query_label QUERY_LABEL
label of the query data, defined in Dataset.py/Config,
here the query dataset should overlap with training
dataset
--add_risk_loss ADD_RISK_LOSS
1: will add risk loss when running KP, 0: same as pure
KD
--nclass NCLASS number of classes
--train_batch_size TRAIN_BATCH_SIZE
--KP_infer_batch_size KP_INFER_BATCH_SIZE
batch size for inference during membership attack
--device DEVICE
--epochs EPOCHS number of epochs
--T T temperature for ST
--lr LR initial learning rate
--lambda_kd LAMBDA_KD
trade-off parameter for kd loss
--lambda_risk LAMBDA_RISK
trade-off parameter for risk loss
--num_workers NUM_WORKERS
number of num_workers
--command_class COMMAND_CLASS
for internal use only, no change
python afs.py forget \
--root ./template/MNIST \
--expname EXP1 \
--KD_label KD0.5 \
--test_label TEST1 \
--query_label QF_100 \
--cal_label CAL_1000 \
--cal_test_label CALTEST1 \
--nclass 10 \
--teacher_model ./models/EXP1/BASE1/best_model.pth \
--epochs 50 \
--add_risk_loss 1 \
--lr 0.001 \
--device cuda:0 \
--train_batch_size 32 \
--lambda_risk 1
python afs.py forget \
--root ./template/PathMNIST \
--expname EXP1 \
--KD_label KD0.5 \
--test_label TEST1 \
--query_label QF_100 \
--cal_label CAL_1000 \
--cal_test_label CALTEST1 \
--nclass 9 \
--teacher_model ./models/EXP1/BASE1/best_model.pth \
--epochs 50 \
--add_risk_loss 1 \
--lr 0.001 \
--device cuda:0 \
--train_batch_size 32 \
--lambda_risk 1
python afs.py forget \
--root ./template/COVIDx \
--expname EXP1 \
--KD_label KD0.5 \
--test_label TEST1 \
--query_label QF_100 \
--cal_label CAL_1000 \
--cal_test_label CALTEST1 \
--nclass 2 \
--teacher_model ./models/EXP1/BASE1/best_model.pth \
--epochs 50 \
--add_risk_loss 1 \
--lr 0.001 \
--device cuda:0 \
--KP_infer_batch_size 32 \
--train_batch_size 32 \
--lambda_risk 1
python afs.py forget \
--root ./template/Autism \
--expname EXP1 \
--KD_label KD0.5 \
--test_label TEST1 \
--query_label QF_100 \
--cal_label CAL_1000 \
--cal_test_label CALTEST1 \
--nclass 2 \
--teacher_model ./models/EXP1/BASE1/best_model.pth \
--epochs 50 \
--add_risk_loss 1 \
--lr 0.001 \
--device cuda:0 \
--KP_infer_batch_size 4 \
--num_workers 1 \
--train_batch_size 4 \
--lambda_risk 1
If you find our work useful, please cite our paper:
Zhou, J., Li, H., Liao, X. et al. A unified method to revoke the private data of patients in intelligent healthcare with audit to forget. Nat Commun 14, 6255 (2023). https://doi.org/10.1038/s41467-023-41703-x