#Hands on Lab - World of Watson, October 2016
Session Name: From Lab to Production: Scale Up Your Data Science with IBM Data Science Experience
Date: October 25, 2016, 4:00pm - 6:30pm
Place: Las Vegas, Mandalay Bay - Bayside F - 13
Description: Learn how IBM Data Science Experience can be used in early the stages of a data science project to create models that can then be scaled. By making it easy to change Spark instances with Jupyter notebooks or RStudio, Data Science Experience makes it easy to scale up when you are ready.
Speakers:
- Brandon MacKenzie, IBM
- Greg Filla, IBM
- Account Set-up
- Create a project
- Load data
- Import Notebook from GitHub
- Load Object Storage Data in a Notebook
- Create decision tree in R
- Additional Activities
- Create & Visualize Decision Tree with SPSS in Scala
#Step 1. Get on IBM Data Science Experience (DSX).
-
Click the signup button on the top right

-
If you have a Bluemix account you can click continue with Bluemix credentials, otherwise click create your Bluemix account and enter your email.
-
You should get an email from "ibmacct" with your IBMid Confirmation code
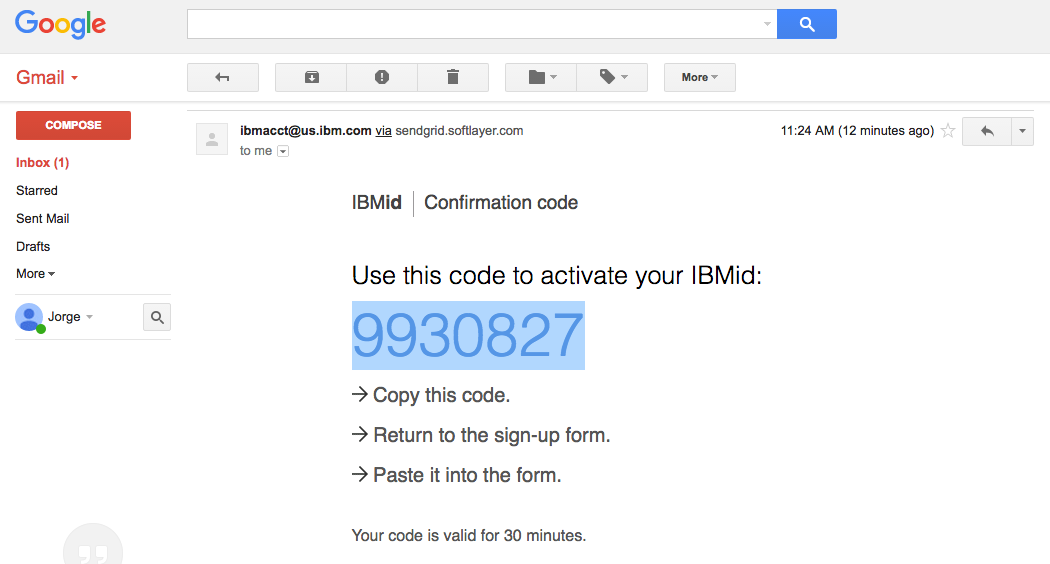
- Then, on the next page fill in the corresponding fields and click CREATE ACCOUNT

- In the new page, write your email and click CONTINUE

- Write your recently generated password and click on SIGN IN
- It will take a minute to create your account. When ready, click on Get Started.
You are now in the Data Science Experience landing page. Your environment is automatically set up with one Apache Spark instance and 5 GB of object storage. From here you can explore any of the tutorials, videos, sample notebooks, totorials or articles in the community.

- Click on the left hand side "hamburger" icon and then click on My Projects to see a list of your projects. You should only see a default project.
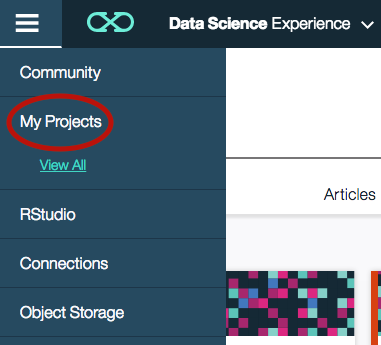
- Click on the create project icon on the top right of the project list.

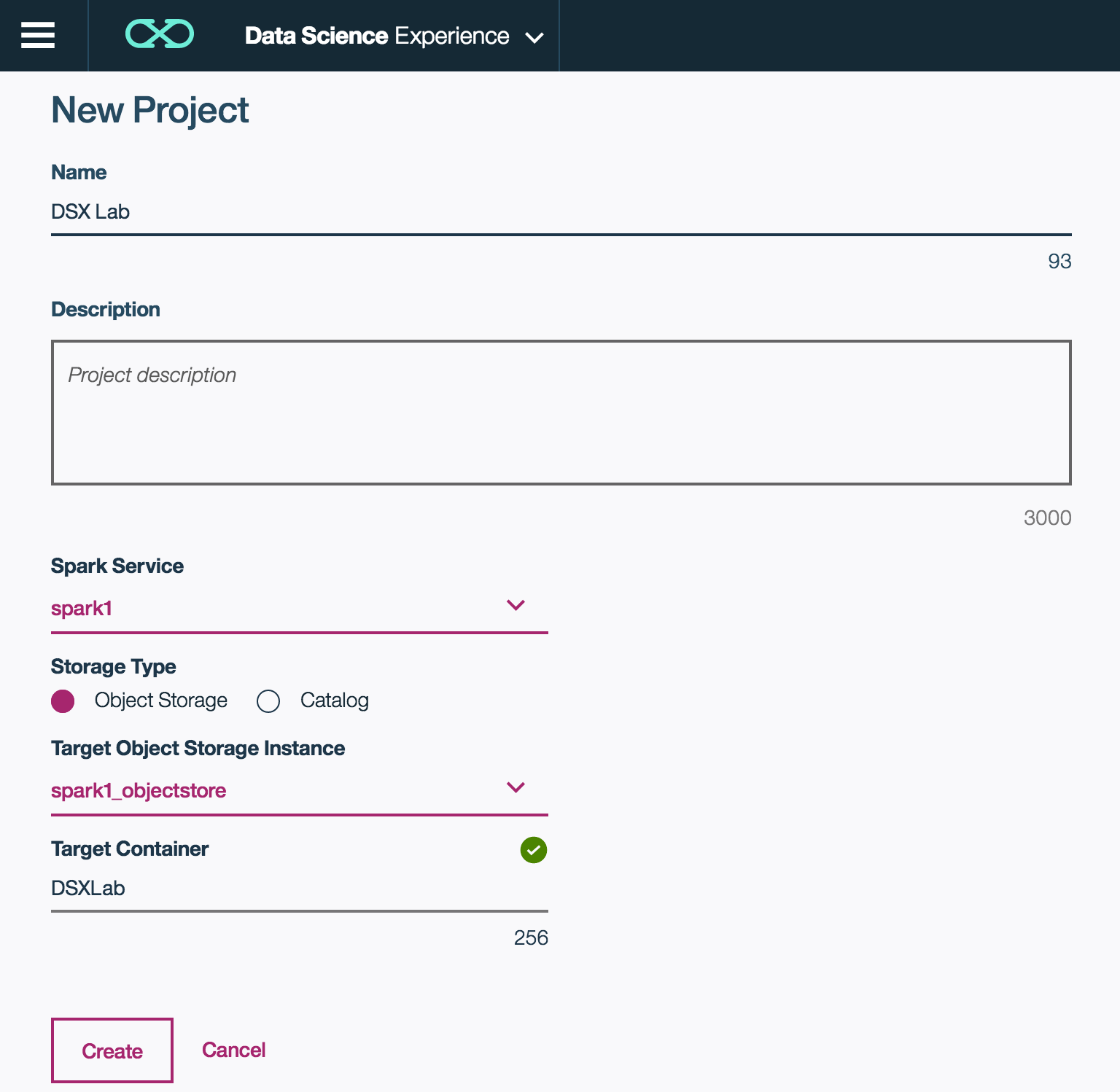
- Type a name for your project. For instance, "DSX Lab". A Spark service and an object storage will be automatically selected as well as a container with a default name. A container is a directory on the object storage. Click on Create.
You are now in your new project where you can create notebooks and data assets as well as add collaborators.
-
Click here to download this repository to your computer to access the data stored in the data directory.
-
Unzip this zip file on your computer so you have a directory with all the assets in the repository. We will be using the data from the data directory. The screenshot below shows dragging the contents to the desktop for easy access:

- Go to your recently created project on DSX and click on the add data assets + icon

- Click on the Add file and select the transactions.csv file from your computer and click on open

- Once the file is loaded, click on Apply to add this file to your project.

Click Apply on the pop-up:

You should see transactions.csv under the data assets list of your project. Your data is now loaded in your object storage in the container associated to your project. If your project name is "DSX Lab", the default container name is DSXLab (unless you change to a different name on Step 2, part 3).

- From the your project page, on the "Overview" tab click "add notebook"

- In the next screen named “Create Notebook”, switch to “From File” tab, name the notebook “ML Lab Installation”, and choose the notebook file on your disk from the archive: notebooks/ml-lab-installation.ipynb; alternatively you can switch to “From URL” tab and use the following “Notebook URL”:

- Click Create Notebook at the bottom of the page to add the notebook
- Run all the cells in the notebook clicking on the Run All option under Cells

- Once the libraries have been installed, all the cells will have a number present on the left side of the notebook between square brackets.

- Click File -> Save or the Floppy disk icon to save the notebook
- Return back to the project overview page by clicking on "DSX Lab" or the name you gave your project

NOTE: the software packages installation may take a few minutes, but it needs to be done only once per account
- Load the second notebook “Machine Learning with DSX - Lab” (from the file machine-learning-with-DSX-lab.ipynb, or from URL https://raw.githubusercontent.com/IBMDataScience/wow-lab-to-production/master/notebooks/machine-learning-with-DSX-lab.ipynb ) by following the same steps 1-3 as above
- From the loaded notebook “Machine Learning with DSX Lab” click on "Find and add data":

- Follow the instructions in the cell of the notebook shown below:

```R
df.data.1 <- read.csv(file = getObjectStorageFileWithCredentials_92c679820c6ebdd53("DSXLab", "transactions.csv"))
head(df.data.1)
```
Replace df.data.1 with df
```R
df <- read.csv(file = getObjectStorageFileWithCredentials_92c679820c6ebdd53("DSXLab", "transactions.csv"))
head(df)
```
After the modifications, the section code should define a data frame variable df which is used in the notebook; the modifications should be done only for replacing the variable in the last 2 lines of code shown above.
-
Begin execution of every code section in the order in which the sections appear by clicking on the button
 or by using the menu Cell> Run Cells. The lab covers the following actions:
or by using the menu Cell> Run Cells. The lab covers the following actions:a. Declaring the libraries used in the lab
b. Loading the data from the Object Storage into a data frame
c. Transforming the data for using with C5.0
d. Training the classification model (C5.0)
e. Transforming the classification model to visualize it in Brunel
f. Using a tree map for visualizing and exploring the decision tree in Brunel
g. Using a tree for exploring the decision tree in Brunel
h. Showing the native R visualization of the decision tree for comparison
-
Stop the kernel (File > Stop Kernel) and go back to the project overview page or DSX home page

- Load the this notebook “SPSS Decision Tree and Visualization” (from the file machine-learning-with-DSX-lab.ipynb, or from URL https://raw.githubusercontent.com/IBMDataScience/wow-lab-to-production/master/notebooks/SPSS%2BDecision%2BTree%2Band%2BVisualization.ipynb ) by following the same steps 1-3 as above
- This notebook also uses the transactions.csv data set.
- Follow the instructions in the cell of the notebook shown below:
