本次作业旨在利用ResNet18实现对于Cifar-100数据集进行图像识别按照精细类进行分类。 Cifar-100数据集由20个粗类和100个细类组成,每个粗类包含5个细类,每个细类有500张训练图片和100张测试图片。 残差神经网络(ResNet)是由微软研究院的何恺明、张祥雨、任少卿、孙剑等人提出的。ResNet 在2015 年的ILSVRC(ImageNet Large Scale Visual Recognition Challenge)中取得了冠军。
https://blog.csdn.net/aa1520098156/article/details/125130782?spm=1001.2014.3001.5502
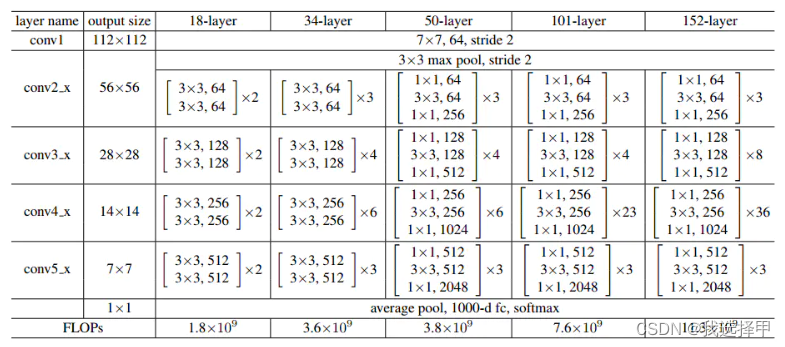
导入:
import tensorflow.keras as keras
import tensorflow as tf
from tensorflow.keras import layers下面是一个基本残差结构的代码:
class BasicBlock(layers.Layer):
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
self.left = keras.Sequential([
layers.Conv2D(filters=filter_num, kernel_size=(3, 3), strides=stride, padding='same'),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.Conv2D(filters=filter_num, kernel_size=(3, 3), strides=1, padding='same'),
layers.BatchNormalization()
])
if stride != 1:
self.downSample = keras.Sequential([
layers.Conv2D(filters=filter_num, kernel_size=(1, 1), strides=stride),
layers.BatchNormalization()
])
else:
self.downSample = lambda x: x
def call(self, inputs, training=None):
identity = self.downSample(inputs)
out = self.left(inputs)
output = layers.add([out, identity])
output = tf.nn.relu(output)
return output残差边的作用在于可以通过一条残差边将这一部分直接“跳过”。实现这一目的很简单,将这些层的权重参数设置为0就行了。这样一来,不管网络中有多少层,效果好的层我们保留,效果不好的我们可以跳过。总之,添加的新网络层至少不会使效果比原来差,就可以较为稳定地通过加深层数来提高模型的效果了。
接下来使用make_res_block组合残差块:
def make_res_block(filter_num, blocks, stride=1):
res_block = keras.Sequential()
res_block.add(BasicBlock(filter_num, stride))
for i in range(1, blocks):
res_block.add(BasicBlock(filter_num, stride=1))
return res_block最后由多个残差块构成一个残差网络的模型,和传统的ResNet18不同的是,将第一层卷积层的size改为了3*3的结构以适应32*32*3的图片大小:
class ResNet(keras.Model):
def __init__(self, layer_dims, num_class=100):
super(ResNet, self).__init__()
self.pre = keras.Sequential([
layers.Conv2D(filters=64, kernel_size=(3, 3), strides=(1, 1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPooling2D(pool_size=(2, 2), strides=(1, 1), padding='same')
])
self.layer1 = make_res_block(64, layer_dims[0])
self.layer2 = make_res_block(128, layer_dims[1], stride=2)
self.layer3 = make_res_block(256, layer_dims[2], stride=2)
self.layer4 = make_res_block(512, layer_dims[3], stride=2)
self.average_pooling = layers.GlobalAveragePooling2D()
self.fc = layers.Dense(num_class)
def call(self, inputs, training=None):
x = self.pre(inputs, training=training)
x = self.layer1(x, training=training)
x = self.layer2(x, training=training)
x = self.layer3(x, training=training)
x = self.layer4(x, training=training)
x = self.average_pooling(x)
x = self.fc(x)
return x导入:
import tensorflow as tf我们选择从keras库中导入Cifar-100数据集的数据并将图片的数据转化到0-1之间,从训练集中切分出10%作为验证集:
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.cifar100.load_data()
train_images, test_images = train_images / 255.0, test_images / 255.0
train_labels = train_labels.astype(np.float32)
test_labels = test_labels.astype(np.float32)
test_dataset = tf.data.Dataset.from_tensor_slices((test_images, test_labels)).batch(50)
validation_images = train_images[45000:]
train_images = train_images[0:45000]
validation_labels = train_labels[45000:]
train_labels = train_labels[0:45000]然后使用ImageDataGenerator进行数据增广,数据增广是深度学习中常用的优化技巧之一,通过对训练数据进行一系列变换增加样本数量及样本多样性,使得模型具有更强的泛化能力。 代码如下:
datagen = ImageDataGenerator(
featurewise_center=False, # 布尔值。将输入数据的均值设置为 0,逐特征进行。
samplewise_center=False, # 布尔值。将每个样本的均值设置为 0。
featurewise_std_normalization=False, # 布尔值。将输入除以数据标准差,逐特征进行。
samplewise_std_normalization=False, # 布尔值。将每个输入除以其标准差。
zca_whitening=False, # 布尔值。是否应用 ZCA 白化。
# zca_epsilon ZCA 白化的 epsilon 值,默认为 1e-6。
# rotation_range=30, # 整数。随机旋转的度数范围 (degrees, 0 to 180)
width_shift_range=0.2, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.2, # randomly shift images vertically (fraction of total height)
horizontal_flip=True, # 布尔值。随机水平翻转。
vertical_flip=False, # 布尔值。随机垂直翻转
fill_mode='nearest'
)
datagen.fit(train_images)构建优化器,Adam优化器实现简单,计算高效,对内存需求少:
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001, decay=0.004)自定义损失函数,由一个keras的SparseCategoricalCrossentropy损失函数和损失函数l2正则化构成,l2正则化通过限制权重的大小,防止模型拟合随机噪音,用于限制过拟合问题:
def spareCE(y_true, y_pred):
sce = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
return tf.reduce_mean(sce(y_true, y_pred))
def l2_loss(my_model, weights=1e-4):
variable_list = []
for v in my_model.trainable_variables:
if 'kernel' or 'bias' in v.name:
variable_list.append(tf.nn.l2_loss(v))
return tf.add_n(variable_list) * weights
def myLoss(y_true, y_pred):
sce = spareCE(y_true, y_pred)
l2 = l2_loss(my_model=model)
loss = sce + l2
return loss模型初始化:
model = ResNet([2, 2, 2, 2])model.compile()方法用于在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准:
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001, decay=0.004),
loss=myLoss,
metrics=['sparse_categorical_accuracy'])model.fit()方法用于执行训练过程,训练数据由ImageDataGenerator生成,并记录日志。其中学习率由keras_tuner方法调试得出:
history = model.fit(
datagen.flow(train_images, train_labels, batch_size=64), steps_per_epoch=len(train_images) / 64,
# x=train_images, y=train_labels, batch_size=64,
epochs=150, verbose=2,
validation_data=(validation_images, validation_labels)
)保存模型:
model.save('saved_model/my_model')请先训练模型得到训练后的模型才能进行模型测试,我自己训练好的模型大小太大了,传不上来。
my_model = tf.keras.models.load_model('saved_model/my_model', custom_objects={'myLoss': myLoss})
correct_num = 0
test_dataset = tf.data.Dataset.from_tensor_slices((test_images, test_labels)).batch(50)
for x, y in test_dataset:
y_pred = my_model(x, training=False)
y_pred = tf.cast(tf.argmax(y_pred, 1), dtype=tf.int32)
y_true = tf.cast(tf.squeeze(y, -1), dtype=tf.int32)
equality = tf.equal(y_pred, y_true)
equality = tf.cast(equality, dtype=tf.float32)
correct_num += tf.reduce_sum(equality)
print(float(correct_num))
print('acc=', float(correct_num) / 10000.0)得出测试集的正确率为62.21%:
acc= 0.6221通过history日志调出训练时训练集和测试集的正确率和损失值并用matplotlib绘制图像:
from matplotlib import pyplot as plt
fig1, ax_acc = plt.subplots()
plt.plot(history.history['sparse_categorical_accuracy'], 'r', label='acc')
plt.plot(history.history['val_sparse_categorical_accuracy'], 'b', label='val_acc')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Model - Accuracy')
plt.legend(loc='lower right')
plt.show()
fig2, ax_loss = plt.subplots()
plt.plot(history.history['loss'], 'r', label='loss')
plt.plot(history.history['val_loss'], 'b', label='val_loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Model- Loss')
plt.legend(loc='upper right')
plt.show()训练过程中训练集正确率与验证集正确率变化:

训练过程中训练集损失值与验证集损失值变化:

使用opencv绘制预测训练集时的预测结果可视化(图片很大,仅截取部分,完整大图运行下方代码后详见test_visualisation.png):

绘图代码如下:
# 精细类别的序号与名称 序号:名称
fineLabelNameDict = {}
# 精细类别对应的粗糙类别 精细序号:粗糙序号-粗糙名称
fineLableToCoraseLabelDict = {}
def dealData(meta, train):
for fineLabel, coarseLabel in zip(train[b'fine_labels'], train[b'coarse_labels']):
if fineLabel not in fineLabelNameDict.keys():
fineLabelNameDict[fineLabel] = meta[b'fine_label_names'][fineLabel].decode('utf-8')
if fineLabel not in fineLableToCoraseLabelDict.keys():
fineLableToCoraseLabelDict[fineLabel] = str(coarseLabel) + "-" + meta[b'coarse_label_names'][
coarseLabel].decode('utf-8')
meta = unpickle('cifar-100-python/meta')
train = unpickle('cifar-100-python/test')
dealData(meta, train)
img = np.zeros([3300, 6400, 3], np.uint8)
font = cv.FONT_HERSHEY_SIMPLEX
for i in range(100):
category = fineLabelNameDict[i]
cv.putText(img, text=category, org=(10, i * 32 + 50), fontFace=font, fontScale=1, color=(255, 255, 255),
lineType=cv.LINE_AA)
position = np.zeros([100], dtype=int)
for x, y in test_dataset:
y_pred = my_model(x, training=False)
y_pred = tf.cast(tf.argmax(y_pred, 1), dtype=tf.int32)
for image, img_category in zip(x, y_pred):
print(img_category, '__', position[img_category])
x0 = int(img_category) * 32 + 18
y0 = position[img_category] * 32 + 250
# image = image * 255.0
image = image[:, :, ::-1] # RGB TO BGR
img[x0:x0 + image.shape[0], y0:y0 + image.shape[1], :] = image * 255.0
position[img_category] += 1
# cv.imshow('img', img)
cv.imwrite('test_visualisation.png', img=img)第一版ResNet18。仅做图像数除以255将图像数据转化到0-1的处理,设定学习率为0.1,无学习率decay,使用SparseCategoricalCrossentropy作为损失函数。
最终结果:在50个epoch内,训练集损失值稳定下降,正确率稳定上升至约0.8,损失值从约4.5下降至约0.5。但是验证集的损失值从约4.3下降至约3.8再重新上升至10.0,正确率仅仅达到约0.20且难以上升。
第一版VGG16,尝试使用VGG16作为网络模型,数据处理方式和学习率和损失函数不变。
最终结果,在150个epoch内,训练集损失值稳定下降,正确率稳定上升至约0.7。但是验证集的表现很差,损失值从约4.9一路上升到约20,正确率卡在0.11难以上升。
第二版ResNet18。在第一版ResNet18基础上使用ImageDataGenerator来进行数据增广。epoch改为200
最终结果:在200个epoch内,训练集正确率到达约0.45,损失值从约4.7降低至约1.88。验证集正确率达到约0.37
第三版ResNet18。在第二版ResNet18的基础上调整了ImageDataGenerator参数并使用了根据,将学习率改为0.001。epoch改为100
最终结果:在100个epoch内,训练集正确率上升至约0.99,损失值降至0.0151,验证集的正确率达到约0.49但难以继续上升且持续震荡,验证集损失率先从约4.6降至约2.5再升至4.5并不断震荡。
第四版ResNet18。在第三版ResNet18的基础上重新调整了ImageDataGenerator参数,学习率改为0.1。epoch改为50
最终结果:在50个epoch内,训练集正确率在10个epoch左右快速上升至约0.9,损失值降至0.3,在最后训练集正确率达到0.9999,损失值达到4.7983e-04。验证集的正确率达到约0.5震荡幅度小但卡住难以继续上升,验证集损失从约4.6降至约2.6再升回约3.6。
第1版ResNet34。在第四版ResNet18基础上仅仅将ResNet18改为ResNet34结构,轻微重新调整ImageDataGenerator参数。进行100个epoch。
最终结果:由于ResNet34的结构较大,训练花费时间很长。在100个epoch内,训练集正确率上升至约0.98,损失值从约4.0下降至约0.05。验证集正确率上升至0.65但是在0.56和0.65之间剧烈震荡,震荡程度非常大,损失值从约4.1下降至最低约1.8再到最后在约2.5和约4.0之间剧烈震荡。


第5版ResNet18,在第四版ResNet18的使用自定义损失函数,在原有SparseCategoricalCrossentropy损失函数的基础上,增加l2正则化来降低过拟合问题。调整了Adam优化器的decay参数。根据keras_tuner调参,根据调参结果将学习率改为0.01。修改了ImageDataGenerator参数。进行150个epoch。
最终结果:训练集正确率上升到约0.92,损失值从约4.1降至约0.74。验证集的正确率稳步上升至约0.62,损失值从约3.6下降至约2.0且从上方可视化那一节的图像上来看震荡非常小,几乎没有剧烈震荡。