ReviewRobot: Explainable Paper Review Generation based on Knowledge Synthesis Sample Output
Accepted by 13th International Conference on Natural Language Generation (INLG 2020)
- Python 3.6 CAUTION!! The model might not be saved and loaded properly under Python 3.5
- Ubuntu 16.04/18.04/20.04 CAUTION!! The model might not run properly on windows because windows uses backslashes on the path while Linux/OS X uses forward slashes
You can click the following links for detailed installation instructions.
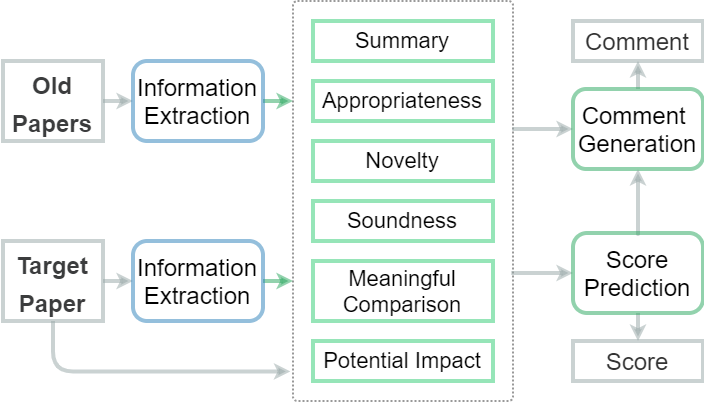
ReviewRobot dataset This dataset contains 8,110 paper and review pairs and background KG from 174,165 papers. It also contains information extraction results from SciIE, various knowledge graphs built on the IE results, and human annotation for paper-review pairs. The detailed information can be found here.
Download and unzip the dataset.zip from Paper review dataset. Replace the existing dataset folder with the folder extracted from dataset.zip.
Run the python preprocess.py which is under the Score Prediction folder. It will extract required features and create the training/validation/testing sets which have the same split as the PeerRead.
The data folder, which is under the Score Prediction folder, stores the preprocessed files for the best models used in the paper. Those files will be updated if you run the training files again.
You can train up to 7 categories: RECOMMENDATION, APPROPRIATENESS, MEANINGFUL_COMPARISON, SOUNDNESS_CORRECTNESS, ORIGINALITY, IMPACT, and CLARITY.
The training/testing files for those categories are: recommend.py / test_recommend.py for RECOMMENDATION, appropriate.py / test_appropriate.py for APPROPRIATENESS, meaningful_comparison.py / test_meaningful_comparison.py for MEANINGFUL_COMPARISON, sound.py / test_sound.py for SOUNDNESS, novelty.py / test_novelty.py for NOVELTY, impact.py / test_impact.py for IMPACT, clarity.py / test_clarity.py for CLARITY.
Hyperparameter can be adjusted as follows: For example, if you want to change the number of hidden units to 32, you can append --hidden_dim 32 after impact.py. More hyperparameters can be changed, please check the code for more detailed instructions.
To train the impact score predicter, you can run:
python impact.py
The models reported in Table 5 of the Paper are under models/*/best folders. Before you want to test those models, you need to make sure the dataset files under data folder are not changed.
To test the impact score with the pre-trained model, you can run:
python test_impact.py
If you trained your own model and want to test it, you can also run the following:
python test_impact.py --model_dp <path_to_your_model>
Where <path_to_your_model> is the path to your previous model.
Create two subfolders: paper and scores under the Score Prediction folder. Under the paper folder create three subfolders: novelty, recommend, and related. Under the scores folder also create three subfolders: MEANINGFUL_COMPARISON, ORIGINALITY, and RECOMMENDATION. Go to the Comment Generation folder. Create three subfolder under it: template_comment, data, and template_paper. Under the data folder, also create three subfolders: MEANINGFUL_COMPARISON, ORIGINALITY, and SUMMARY.
Run python template_prepare_category.py to gather tokenized reviews for each paper.
Run python template_preprocess.py to extract features and create input files for score predictions.
Then, go to Score Prediction folder, run python test_meaningful_comparison.py, python test_novelty.py, and python test_recommend.py respectively to predict scores for meaningful comparison, novelty, and overall recommendation. This step will generate predicted scores under paper folder.
Run python template_prepare_generator.py to generate the required file for the template-based generator. Finally, you can run python related.py, python novelty.py, and python summary.py to generate reviews for missing related work, novelty, and paper summary.
@inproceedings{wang-etal-2020-reviewrobot,
title = "{R}eview{R}obot: Explainable Paper Review Generation based on Knowledge Synthesis",
author = "Wang, Qingyun and
Zeng, Qi and
Huang, Lifu and
Knight, Kevin and
Ji, Heng and
Rajani, Nazneen Fatema",
booktitle = "Proceedings of the 13th International Conference on Natural Language Generation",
month = dec,
year = "2020",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.inlg-1.44",
pages = "384--397"
}