This repository contains foundational algorithms and models commonly used in machine learning. It serves as a resource for beginners to understand the core concepts and implementation of essential techniques. The repository is organized into two main folders: PCA and Simple NN Model.
The NN-From-Scratch folder contains a basic implementation of a neural network from scratch using Python. This model serves as a foundation for understanding the fundamental concepts of neural networks, including forward propagation, backward propagation, and gradient descent.
The implementation of the forward pass for the one hidden layer neural network can be found in the above file.
This file contains the code for performing the forward and backward pass operations. It includes functions to compute the activations of the hidden layer and the output layer, given the input features and the model parameters, it also includes calculating the gradients of the functions to be used for gradient descent.
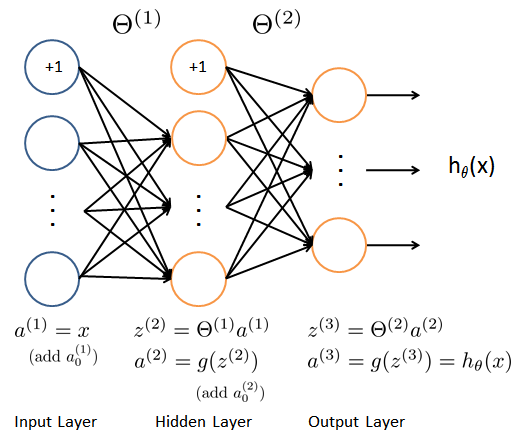
This is a demonstration of the forward pass for a one-hidden-layer neural network with the output layer for classification tasks. The forward pass is a fundamental step in neural network computation, where input data is propagated through the network to generate predictions.
The neural network architecture consists of three layers:
- Input Layer: The input layer receives the feature values of the input data.
- Hidden Layer: The hidden layer applies a set of weights and biases to the input data, followed by an activation function (sigmoid in our example).
- Output Layer: The output layer produces the final predictions based on the transformed features from the hidden layer.
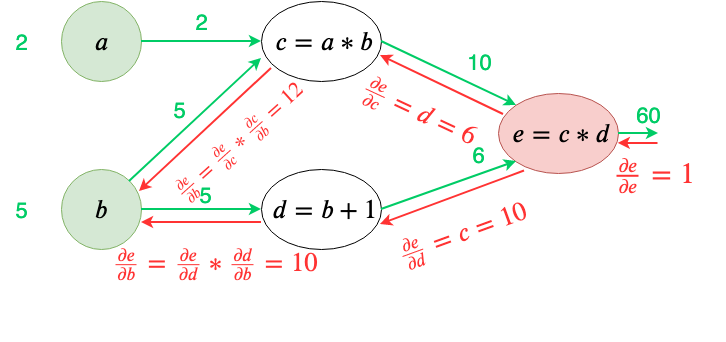
Backpropagation is a core algorithm in neural network training, enabling adjustments of weights and biases to minimize prediction errors. It iteratively propagates errors backward through the network layers, using the chain rule of calculus to efficiently compute gradients. This process enables the optimization of network parameters via gradient descent, forming the foundation of modern deep learning frameworks and facilitating training of complex neural architectures for diverse machine learning tasks.

Gradient descent is a fundamental optimization algorithm used to minimize the loss function by iteratively adjusting the model parameters. In our context, we update the weights W1,W2,b1,b2 of a neural network for classification.
- W1 <- W1 - alpha * dL_dW1
- W2 <- W2 - alpha * dL_dW2
- b1 <- b1 - alpha * dL_db1
- b2 <- b2 - alpha * dL_db2
The SimpleNN class in model.py is a basic implementation of a neural network. Its main components and functionality:
-
Initialization:
- The constructor
__init__allows users to define the architecture of the neural network by specifying the number of input features (h0), neurons in the first hidden layer (h1), and neurons in the second hidden layer (h2).
- The constructor
-
Forward Pass:
- The
forward_passmethod performs the forward pass through the neural network, computing the activations of each layer.
- The
-
Backward Pass:
- The
backward_passmethod computes the gradients of the cost function with respect to the parameters of the network during backpropagation.
- The
-
Parameter Update:
- The
updatemethod updates the parameters of the network using the computed gradients and a specified learning rate (alpha).
- The
-
Prediction:
- The
predictmethod applies the trained network to make predictions on new data.
- The
To use the SimpleNN class, users need to:
-
Import:
- Import the
SimpleNNclass frommodel.py.
- Import the
-
Initialization:
- Create an instance of
SimpleNNby specifying the network architecture.
- Create an instance of
-
Training and Prediction:
- Train the network using training data and labels, then make predictions on new data.
Ensure that the necessary dependencies, particularly numpy, are installed to utilize the numerical computations within the class effectively.
The dataset.py file in this repository provides functions for generating synthetic data and splitting it into training and testing sets. Here's a summary of the provided functions:
The generate_data function generates synthetic data with two classes, each having two-dimensional features. It creates clusters for each class with a specified variance and concatenates them to form the dataset. The data is shuffled randomly before returning.
The train_test_split function splits the generated data into training and testing sets based on a specified ratio. It uses the generated data from generate_data and separates it into training and testing subsets according to the provided ratio.
To use the dataset functions:
-
Import:
- Import the
generate_dataandtrain_test_splitfunctions fromdataset.pyinto your Python script:
from dataset import generate_data, train_test_split
- Import the
The sigmoid.py file in this repository contains implementations of the sigmoid activation function and its derivative. These functions are commonly used in neural networks for introducing non-linearity into the model and computing gradients during backpropagation.
-
sigmoid(z):
- Computes the sigmoid activation function for the given input.
- Parameters:
z: numpy array or scalar
- Returns:
- numpy array or scalar
- Result of applying the sigmoid function element-wise to the input.
- numpy array or scalar
-
d_sigmoid(z):
- Computes the derivative of the sigmoid activation function for the given input.
- Parameters:
z: numpy array or scalar
- Returns:
- numpy array or scalar
- Result of applying the derivative of the sigmoid function element-wise to the input.
- numpy array or scalar
-
Importing:
- First, ensure that
sigmoid.pyis in your Python project directory. - Then, you can import the functions into your Python script as follows:
from sigmoid import sigmoid, d_sigmoid
- First, ensure that
The evaluations.py file in this repository contains functions for evaluating machine learning models, including loss and accuracy calculations. Here's a summary of the provided functions:
The loss function computes the cross-entropy loss between predicted labels (y_pred) and true labels (Y). It is commonly used in classification tasks to measure the difference between predicted probabilities and actual class labels.
The accuracy function calculates the accuracy of a model's predictions. It compares predicted labels (y_pred) with true labels (y) and computes the proportion of correct predictions over the total number of samples.
To use the evaluation functions:
-
Import:
- Import the
lossandaccuracyfunctions fromevaluations.pyinto your Python script:
from evaluations import loss, accuracy
- Import the
The main.py script in this repository ties everything together and manages the training, evaluation, and testing of a neural network using various modules and functionalities provided in other files. Here's an overview of what main.py does and how to use it:
The script imports necessary modules and functions from other files within the repository:
numpyfor numerical computations.train_test_splitfunction fromdataset.pyto split the data into training and testing sets.SimpleNNclass frommodel.pyfor creating and training the neural network.sigmoidfunctions fromsigmoid.pyfor implementing activation functions.evaluationsmodule for computing evaluation metrics such as loss and accuracy.
The script performs the following steps:
- Data Splitting: Calls
train_test_splitto split the dataset into training and testing sets. - Neural Network Initialization: Initializes a neural network using the
SimpleNNclass. - Training Loop:
- Iterates over a specified number of epochs.
- Performs forward and backward passes through the neural network.
- Updates the parameters based on computed gradients using gradient descent.
- Optionally, prints the training and testing loss at certain intervals.
- Evaluation:
- Computes and prints the training and testing accuracies using the trained model.
To use main.py:
- Ensure Dependencies:
- Make sure all necessary Python files (
dataset.py,sigmoid.py,evaluations.py,model.py) are in the same directory asmain.py.
- Make sure all necessary Python files (
- Run the Script:
- Simply execute
main.pyusing Python:python main.py
- Simply execute
-
Clone the repository to your local machine:
git clone https://github.com/DuaaAlshreef/foundations-of-machine-learning.git
The PCA folder contains implementations of the Principal Component Analysis algorithm, a widely used technique for dimensionality reduction and data visualization in machine learning. PCA helps in identifying patterns in data and reducing its complexity while preserving important information.
-
PCA.py: This file contains the implementation of the PCA algorithm. It includes functions for calculating principal components, transforming data, and reconstructing original features from reduced dimensions.
-
PCA_CLASS.py: The file contains the implementation of the same PCA algorithm by using class.
-
Initialization:
- The constructor
__init__initializes the PCA object with the desired number of principal components (n_components).
- The constructor
-
Fit Method:
- The
fitmethod computes the principal components from the input data matrixX. It calculates the mean, covariance matrix, eigenvalues, and eigenvectors, sorts them in descending order, and selects the topn_componentsfor further analysis.
- The
-
Transform Method:
- The
transformmethod projects the input data matrixXonto the principal components computed during the fitting process, providing a lower-dimensional representation of the data.
- The
To use the PCA class:
-
Initialization:
- Create an instance of the
PCAclass by specifying the number of principal components:
pca = PCA(n_components=2)
- Create an instance of the
-
Clone the repository to your local machine:
git clone https://github.com/DuaaAlshreef/foundations-of-machine-learning.git
This repository contains Python implementations of the K-Nearest Neighbors (KNN) algorithm for classification tasks. The KNN algorithm is a simple and effective method for classification and regression tasks.
This file contains the implementation of the KNN algorithm. The KNN class provides methods for training the model, predicting labels for new data points, and evaluating the performance of the model.
The dataset.py file includes functions for loading and preprocessing datasets. It provides functionalities to split the dataset into training and testing sets, as well as methods for normalizing or standardizing the data.
main.py serves as the main entry point to demonstrate the usage of the KNN algorithm. It contains example code to load a dataset, train a KNN model, make predictions, and evaluate the model's performance.
This file contains auxiliary functions used in the KNN algorithm implementation, such as distance calculations and vote counting.
To use the KNN algorithm for classification tasks:
- Ensure you have Python installed on your system.
- Clone this repository:
git clone https://github.com/your_username/KNN.git