Languages: English | 中文
This project shows how to deploy chatglm-6b to the free cloud resources or your local machine. And it also shows how to use the chatglm-6b in chat2db client.
| Model | GPU(Inference) | GPU(Finetue) |
|---|---|---|
| ChatGLM-6B-int4 | 6GB | 7GB |
- Open the chatglm-6b-int4-deploy.ipynb in the google colab. In our case, we can run the model in google colab absolutely free.
- Run the code of step1 to step6 in the notebook.
- After the step6, you will get the public demo url for your model such as
https://3cef73d65765afdfea.gradio.live. Click the url to check if the model is deployed successfully. And you can also experiment with the model as you want. Click stop button to stop the web demo.
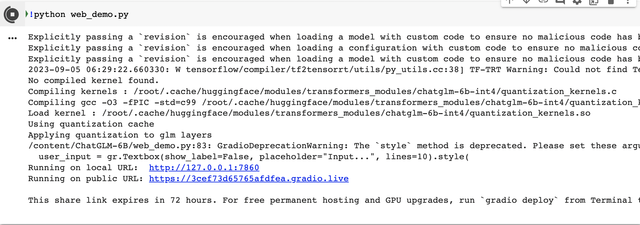


- Note: The google colab will disconnect after 12 hours. You can rerun the notebook to get the public demo url and api url again. And also, the network speed of google colab is not very fast. So it may take a long time to download the model and run the model. Please be patient.
- Since the network in google colab is not very fast, we can also deploy the model to our local machine. The script for deploy in your local machine is similar to the script in the google colab. Just follow the steps in chatglm-6b-int4-deploy.ipynb.
- Note: when you deploy the model in your local machine, you need to change the model path from '/content/chatglm-6b-int4' to the path of your local machine. You need also change the api url in the chat2db client to the url of your local machine.