This repository has been archived by the owner on Oct 25, 2024. It is now read-only.
-
Notifications
You must be signed in to change notification settings - Fork 30
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
4 changed files
with
556 additions
and
0 deletions.
There are no files selected for viewing
153 changes: 153 additions & 0 deletions
153
docs/academic/算法科普/Transformer/OverlapMamba 具备超强泛化能力的定位方法.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,153 @@ | ||
| # 全方位SOTA!OverlapMamba:具备超强泛华能力的定位方法 | ||
|
|
||
| ## I.论文摘要: | ||
|
|
||
| 精准的定位是自动驾驶系统独立决策和安全运行的基石,也是SLAM中环路闭合检测和全局定位的核心。传统方法通常采用点云数据作为输入,和基于深度学习的激光雷达定位(LPR)技术。然而,新近提出的Mamba深度学习模型与状态空间模型(SSM)相结合,展现出处理长序列数据的巨大潜力。基于此,作者开发了OverlapMamba——一种创新的定位网络,它将输入的视距视图(RVs)转化为序列数据。该方法采用了一种新颖的随机重构方法来构建偏移状态空间模型,有效压缩了视觉数据的表示。在三个不同的公共数据集上进行评估,该方法能够有效地检测环路闭合,即便是在从不同方向重访先前的位置时也能保持稳定性。依赖于原始的视距视图输入,OverlapMamba在时间复杂度和处理速度上优于传统的激光雷达和多视图融合方法,展现了卓越的定位能力和实时处理效率。 | ||
|
|
||
| 论文标题:OverlapMamba:Novel Shift State Space Model for LiDAR-based Place Recognition | ||
|
|
||
| 论文链接:https://arxiv.org/abs/2405.07966 | ||
|
|
||
| 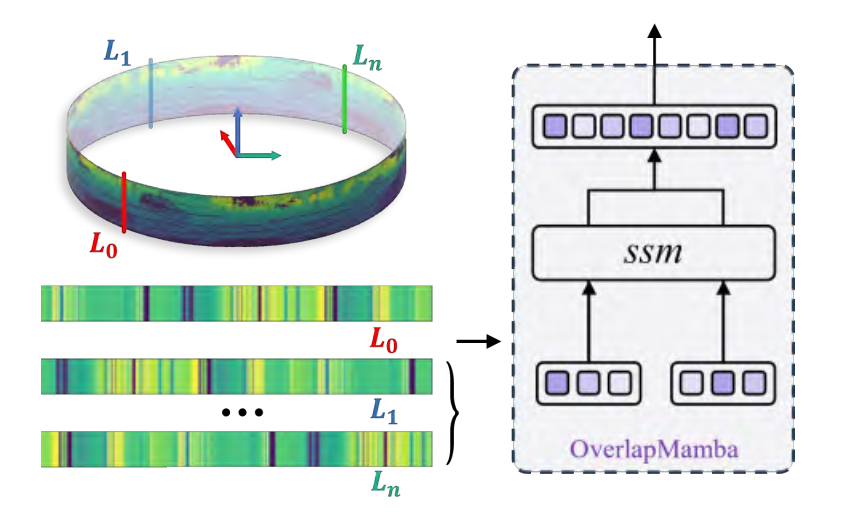 | ||
|
|
||
| 图1.OverlapMamba模型的核心思想。 | ||
|
|
||
| ## II.背景介绍 | ||
|
|
||
| 定位技术使自动驾驶系统能够在没有先验知识的情况下感知周围环境,并在复杂和动态环境中准确识别自身位置。当前基于图像的定位技术通常包括回归图像相似性或匹配描述符来从数据库中检索最相似的参考。然而,由于动态环境变化和光照变化会影响精度,这些方法在自动驾驶系统重新访问先前绘制的位置时可能会导致定位不准确。相比之下,基于激光雷达的定位(LPR)方法表现出更大的稳健性和竞争优势,因为它们不太容易受到环境干扰的影响。这些方法使用 3D 激光雷达进行数据采集,并采用不同的数据表示形式,包括鸟瞰视图、视距视图(RV)和原始 3D 点云作为 LPR 的输入。例如,RangeRCNN引入了RV-PV-BEV(range-point-bird's eye views)模块,将特征从 RV 传输到 BEV,从而避免了尺度变化和遮挡带来的问题。尽管如此,将多个图像聚合以生成全局描述符的计算强度使这些方法不适合快速计算和实时操作。因此,基于图的在线运算方法会产生显著的延迟,并且随着地图扩大,定位和闭环检测所需的时间也会线性增加。 | ||
|
|
||
| 本研究引入了一种端到端网络,利用 RV 作为输入来生成每个位置的朝向不变的全局描述符,以解决现有基于图的在线运算方法固有的高延迟问题。这种稳健的定位方法是通过在多个视角之间匹配全局描述符实现的。此外,这项工作介绍了 OverlapMamba 模块,这是一种新颖的特征提取主干网络,重点将前沿的状态空间模型(SSM)集成到 SLAM 技术中,以提高定位效率并增强全局定位能力。OverlapMamba 模块将 RV 建模为多方向序列,并采用自设计的随机重构方法计算注意力,以弥补 SSM 单向建模和位置感知能力不足的缺陷。网络中集成了一个简单的序列金字塔池化(SPP)架构,以减轻噪声干扰造成的特征损失。 | ||
|
|
||
| 与最优秀的基于Transformer的LPR方法相比,OverlapMamba以线性计算复杂度的优势提供了更优秀的视觉表示。由于其朝向不变的架构和丰富的空间特征合并,所产生的全局描述符在定位任务中表现出稳健性,即使自动驾驶系统以相反的方向导航,其效果也能保持准确。 | ||
|
|
||
| 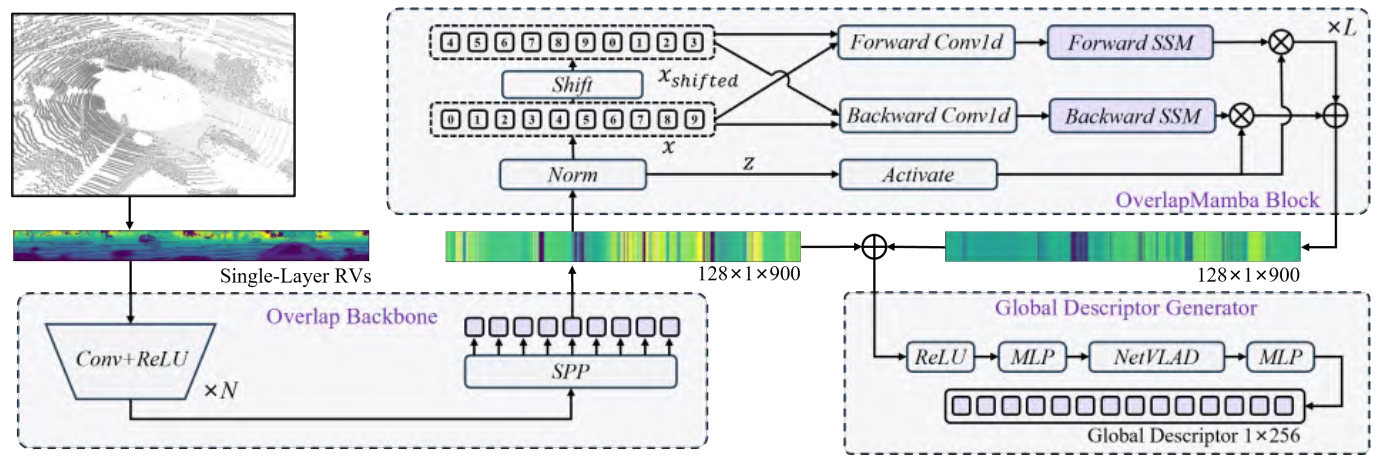 | ||
|
|
||
| 图2.OverlapMamba的总览。 | ||
|
|
||
| ## III.框架概述 | ||
|
|
||
| ### A. 基础模型 | ||
|
|
||
| 本研究重点将前沿的状态空间模型(SSM),即 Mamba 模型集成到 SLAM 技术中,以提高定位效率并增强全局定位能力。 | ||
|
|
||
| 连续系统启发了基于SSM和Mamba的结构化状态空间模型(S4),通过隐藏状态 $h(t) \in R^{N}$,将1-D函数或序列 $x(t) \in R$ 映射到 $y(t) \in R$ 。从数学上讲,它们通常被公式化为线性常微分方程(ODE),其参数包括 $A \in R^{N \times N}$、$B$、$C \in R^{N}$ 和跳跃连接参数 $D \in R^{1}$。在该系统中,A 是进化参数,而 B 和 C 是投影参数。 | ||
|
|
||
| 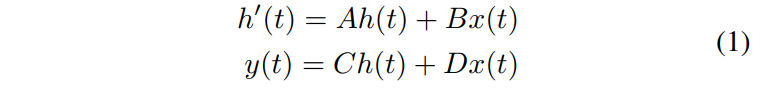 | ||
|
|
||
| 作为连续时间模型,SSM在集成到深度学习算法中时面临重大挑战。离散化是必须的,以克服这一障碍,S4 和 Mamba 是连续系统的离散版本,具有以下离散化规则: | ||
|
|
||
| 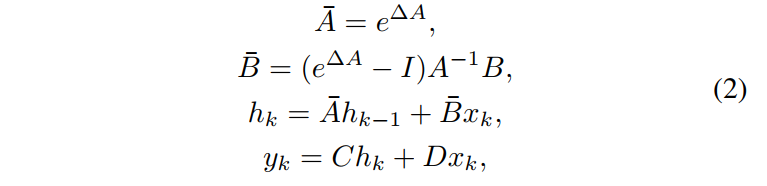 | ||
|
|
||
| 为了实现并行训练并推导用于高效计算 y 的卷积核,使用以下公式:M 表示序列长度,而 $\bar{K}$ 表示 1D 卷积的核。 | ||
|
|
||
| 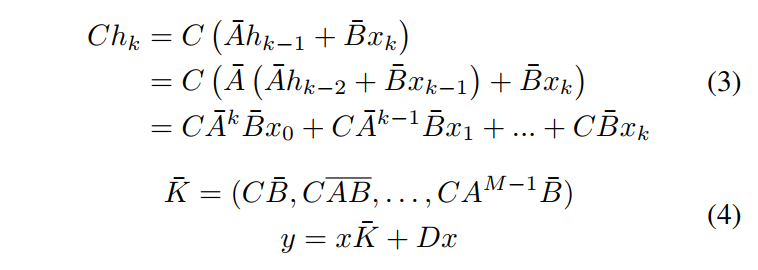 | ||
|
|
||
| ### B. 基于 Mamba 的定位 | ||
|
|
||
| OverlapMamba 模型的整体概览包括重叠主干网络、OverlapMamba 块和最终的 GDG,如图2所示。使用原始激光雷达扫描生成的点云数据,并从中创建 RV。点云 P 和 RVs之间需要进行投影变换 $\Pi: R^3 \rightarrow R^2$,其中每个 3D 点都被转换为 R 上的一个像素。每个点 $p_k = (x, y, z)$ 被转换为图像坐标 $(u, v)$ 如下: | ||
|
|
||
|  | ||
|
|
||
| 其中 $r_k = \|p_k\|_2$ 是对应点 $p_k$ 的距离测量值, $f = f_{up} + f_{down}$ 是传感器的垂直视场, $w, h$ 分别是生成 RV 的宽度和高度。 | ||
|
|
||
| 使用单通道 RV(假设批量大小为 1),大小为 $1 \times h \times w$。与三通道 RGB 图像相比,单通道 RV 提供了更简单的深度信息,在训练过程中具有更高的内存效率。最初为 1D 序列设计的标准 Mamba 模型通过将 RV 转换为序列数据格式而适应视觉任务。在主干网络中,仅沿垂直维度使用卷积滤波器,而不压缩宽度维度。在 OverlapLeg 中,RV 沿垂直维度被分成大小为 $h \times 1$ 的序列,用 1-D 卷积进行处理,然后在单个 $1 \times w$ 序列中连接。然而,单通道 RV 不可避免地缺乏足够的空间信息,无法确保最终生成的序列不会丢失场景信息。这种错误是由于单维处理而导致的噪声放大。因此,在主干网络设计中引入了序列金字塔池化。 | ||
|
|
||
| 受 Vision Mamba 的启发,作者使用 Mamba 以高精度和高效率处理序列。标准 Mamba 专为一维序列而设计。将 RV 序列化以处理视觉任务,得到 $x \in R^{c\times 1\times w}$,其中 c 是通道数,w 是 RV 的宽度。然后,将 $x_{l-1}$ 发送到 OverlapMamba 编码器的第 l 层以获得输出 $x_l$。最后,对输出 $x_l$ 应用激活函数,对其进行标准化,并将其向后传递到 GDG。 | ||
|
|
||
| 在 GDG 中,作者使用 NetVLAD 生成朝向不变的描述性特征符号。NetVLAD 支持端到端基于图像的定位,并具有对朝向旋转的固有不变性。例如,如果输入的原始激光雷达数据旋转了90度和180度,距离图像中的距离将分别移动 $\frac{1}{4}w$ 和 $\frac{1}{2}w$。然而,最终生成的全局描述符是朝向不变的,因此在这两种情况下都会生成相同的全局描述符。整个过程如下公式所示: | ||
|
|
||
| 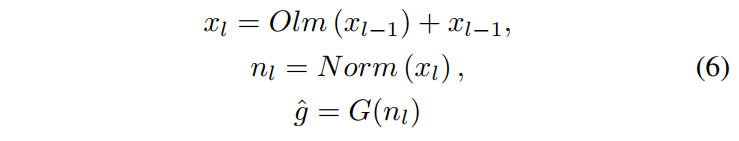 | ||
|
|
||
| 其中 $Olm(.)$ 表示 OverlapMamba 块,输入序列 $x_{l-1}$ 在通过 OverlapMamba 块后与其自身连接。$G(.)$ 表示 GDG,负责将标准化序列转换为最终的全局描述符。 | ||
|
|
||
| ### C. OverlapMamba 块 | ||
|
|
||
| 图2展示了所提出的 OverlapMamba 块(OLM)。原始 Mamba 模块专门为 1D 序列设计,可能不适合需要空间感知的任务。在最新研究中,研究人员普遍采用的一种方法是使用双向序列建模。这种方法本质上是将图像分成多个补丁,并合并位置编码将它们映射为序列。与此同时,一些研究选择使用四个不同的方向序列作为输入,沿垂直和水平轴收集像素信息,然后反转这些生成的序列以创建一个四元组序列。最后,在通过选择性 SSM (S6) 模型后,所有序列被合并到一个新序列中。 | ||
|
|
||
| 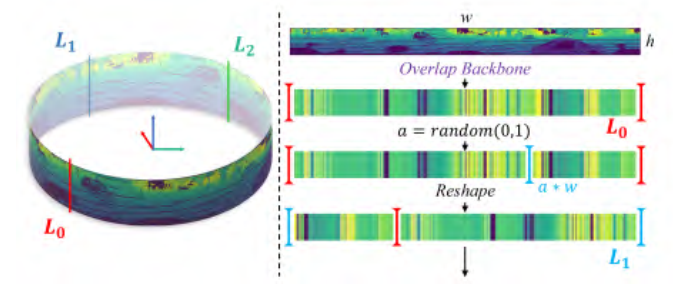 | ||
|
|
||
| 图3.SIFT操作过程。 | ||
|
|
||
| 在本文中,主干网络中的卷积滤波器仅沿垂直维度压缩距离图像,而不压缩宽度维度。这导致特征序列的最大输出大小为 $1\times w\times c$。采用双向方法进行序列建模。添加额外的位置嵌入或沿水平方向采样是不必要的,因为直接通过堆叠的卷积模块获得标记序列。标记序列直接包含朝向信息,反向处理反向序列后就包含了机器人从同一场景的相反方向接近的信息。因此,作者认为由于距离图像包含全局场景信息,不同朝向角下同一场景的标记序列是从循环序列生成的,如图3所示。 | ||
|
|
||
|  | ||
|
|
||
| 算法1 OverlapMamba block 过程。 | ||
|
|
||
| 因此,在重叠主干网络中,作者使用算法1中的Shift(·)函数随机处理标准化的标记序列,并生成随机翻转朝向角的序列。经过处理的数据可以模拟同一场景在不同朝向角下的特征,从而在训练期间增强模型的泛化能力。最后,经过处理后获得四个不同的序列作为选择性SSM(S6)的输入用于推理和训练。 | ||
|
|
||
| 整个OverlapMamba块结合了多方向序列建模,用于定位任务。作者在算法1中演示了OLM块的操作,相关超参数包括:模块堆叠数L、隐藏状态维度D、扩展状态维度E和SSM维度N。该块接收并标准化标记序列$T_{l-1}$;然后,它使用线性层将序列投影以获得x和z。接下来,翻转x并应用随机朝向角处理以获得四个方向序列,每个序列分别处理。对每个序列通过1D卷积和激活函数以获得$x'_o$。然后,切分线性层的结果。使用softplus(·)函数分别计算Δ,再计算A和B,并将它们输入到SSM以获得由z控制的$y'$。最后,通过将四个方向的序列相加,获得输出标记序列$T_l$。 | ||
|
|
||
| ### D. 主干网络中的序列金字塔池化 | ||
|
|
||
| 作者探索了两种不同的方法来生成token序列,以确保朝向等变性。第一种方法利用增强了位置编码的平坦2D补丁。第二种采用纯卷积框架。距离图像大小为64×900,更接近于序列数据的表示形式,而不是垂直和水平方向相等尺寸的普通图像。自然地,转换为序列后可以保留更多的特征信息。然而,针对普通图像提出了处理小补丁和融合位置编码的方法。当应用于距离图像时,水平和垂直方向的特征信息存在失衡。 | ||
|
|
||
| 为了解决这个问题,重叠主干网络沿垂直方向使用卷积滤波器将距离图像压缩为大小为1×w×c的特征序列。这种方法生成的序列最大程度上保留了沿宽度维度的朝向信息。此外,由于距离图像在垂直方向上只有64像素,因此主干网络不需要大滤波器或堆叠多个卷积模块。总体而言,这种方法更适合处理RV。 | ||
|
|
||
| 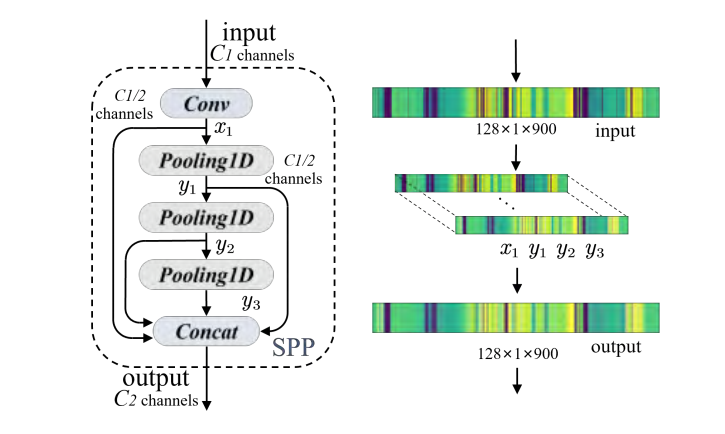 | ||
|
|
||
| 图4.SPP块的结构。 | ||
|
|
||
| 在处理距离图像时,由于滤波器仅沿垂直方向压缩图像,因此图像沿水平方向被分成H个长度为W的序列进行处理。但是,由于距离图像固有的物体失真和噪声干扰,得到的特征序列可能会显示不正确的空间信息。因此,作者提出了一种简单的SPP模块架构,灵感来自空间金字塔池化,如图4所示。 | ||
|
|
||
| SPP采用两层沿水平方向的1-D池化,而无需使用多尺度池化核。它对输入序列执行三次连续的最大池化操作,并连接中间状态,然后使用滤波器进行通道压缩。尽管金字塔池化结构很简单,但通常不能用于序列处理,因为它旨在学习2D图像中的多尺度特征。然而,如前所述,通过垂直卷积处理生成的序列包含水平方向的所有位置信息。因此,使用SPP可以有效提高对象位置和比例在序列中的不变性,并减少由噪声干扰造成的特征损失。 | ||
|
|
||
| 图4展示了输入序列经过两次连续的最大池化操作,以不同分辨率处理序列,以捕获更丰富的空间信息。处理后的序列发生均匀变化,同时保持了空间层次结构。 | ||
|
|
||
| ### E. 改进的triplet损失与硬挖掘 | ||
|
|
||
| 通过设置重叠阈值来判断两个激光雷达扫描之间的相似性,从而计算重叠程度。在训练过程中,模型根据重叠值选择正负样本,并将它们整合到训练批次中。对于每个训练元组,作者使用查询全局描述符$g_q$、$k_p$个正描述符$g_p$和$k_n$个负描述符$g_n$来计算三元损失。 | ||
|
|
||
| 在传统设计中,三元损失通常使用$g_q$与$g_p$之间的平均距离以及$g_q$与$g_n$之间的距离来计算。其目的是从这些具有细微差异的正负样本中学习更加微妙的特征。公式如下,其中a表示边距,$||.||^2_2$计算平方欧几里得距离, +表示当值大于0时为损失值,小于0时损失值为0。 | ||
|
|
||
| 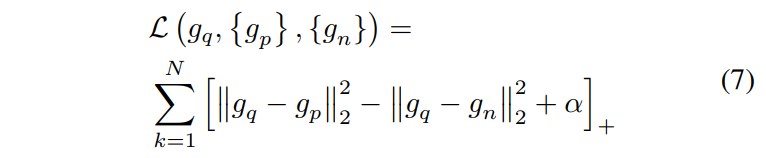 | ||
|
|
||
|  | ||
|
|
||
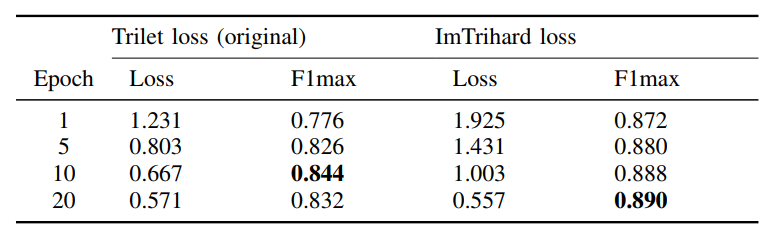
| 图5.训练期间的原始损失和F1max。 | ||
|
|
||
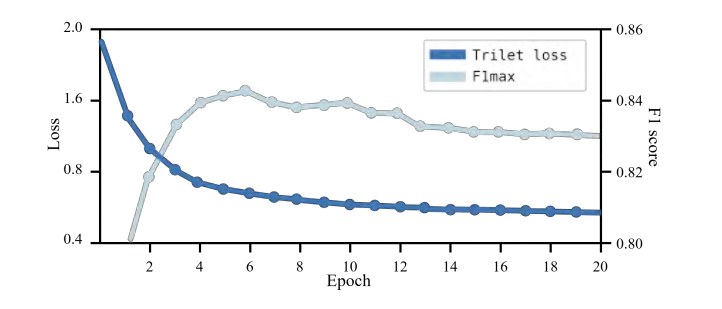
| 在实验中,作者发现损失函数在使用传统三元损失时很难收敛。此外,随着损失函数的减小,模型的泛化能力并没有增加,如图5所示。作者认为模型选择的训练数据分布不均匀。从训练数据中随机选择样本的做法虽然简单,但会导致易于区分的样本。许多容易区分的样本对于网络学习更好的表示并不有利。为了解决这个问题,作者提出从查询样本中选择差异最大的正负样本进行训练,如下式所示: | ||
|
|
||
| 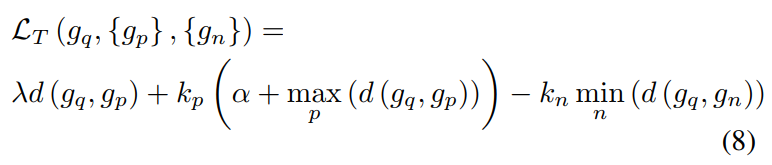 | ||
|
|
||
| 其中$\lambda$表示压缩系数,d(·)用于计算平方欧几里得距离。使用三元损失最小化查询描述符与最难正全局描述符之间的距离,并最大化查询描述符与最难负全局描述符之间的距离,同时添加查询描述符与正样本之间的距离以确保查询与正样本之间的绝对距离。在训练期间,默认将$\lambda$设置为$1\times 10^-4$以控制这一监督项的强度。 | ||
|
|
||
| ## IV.实验结果 | ||
|
|
||
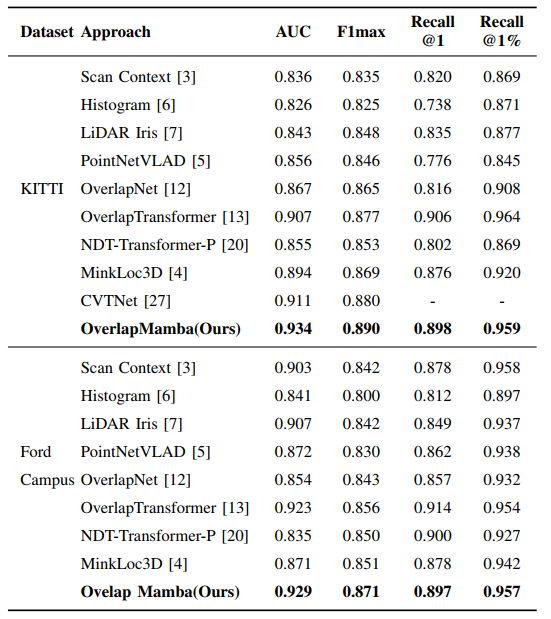
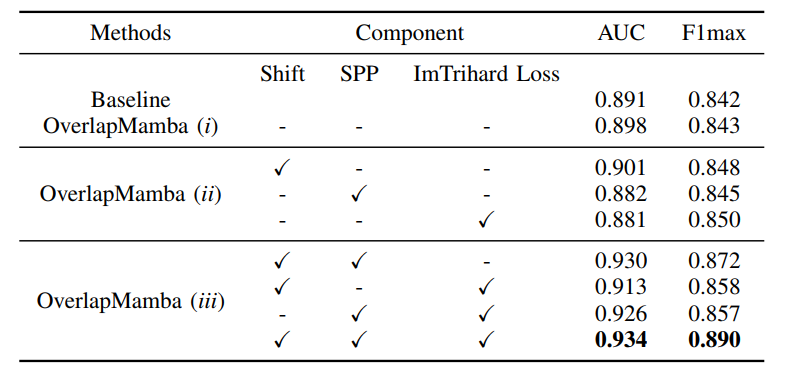
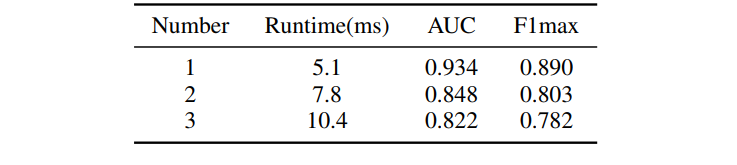
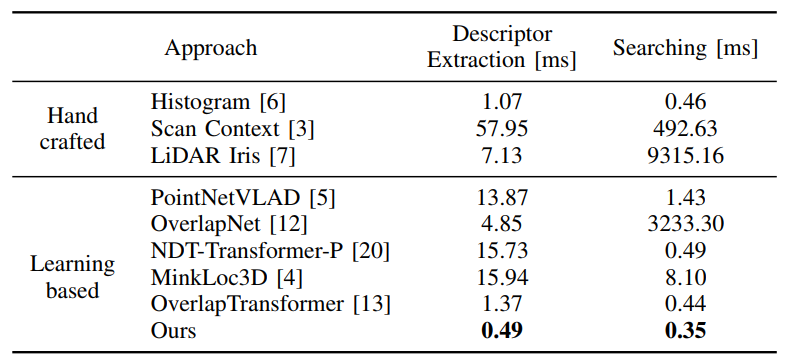
| 作者在三个公开数据集上评估了本模型的性能,结果表明,本方法在时间精度、复杂度和速度上优于其他最先进的方法。 | ||
|
|
||
|  | ||
|
|
||
| 表格I:在KITTI和Ford校园数据集上的闭环检测性能比较。 | ||
|
|
||
|  | ||
|
|
||
| 表格II:在KITTI数据集上进行的本方法各个模块的消融研究。 | ||
|
|
||
|  | ||
|
|
||
| 表格III:在KITTI数据集上使用不同数量的OverlapMamba块的比较。 | ||
|
|
||
|  | ||
|
|
||
| 表格IV:在训练过程中OverlapMamba在两种损失函数上的收敛速度比较。 | ||
|
|
||
|  | ||
|
|
||
| 表格V:与最先进方法的运行时间比较。 | ||
|
|
||
| 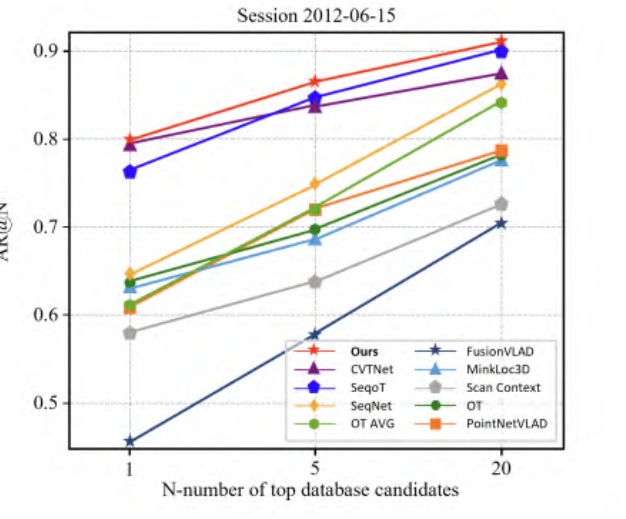 | ||
|
|
||
| 图6.使用NCLT数据集的2012-06-15会话作为查询,2012-01-08作为数据库的场所识别结果。 | ||
|
|
||
| 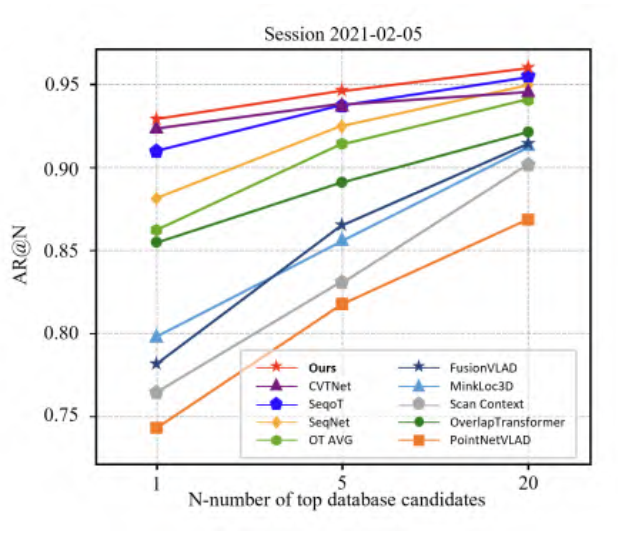 | ||
|
|
||
| 图7.使用NCLT数据集的2012-02-05会话作为查询,2012-01-08作为数据库的场所识别结果。 | ||
|
|
||
| 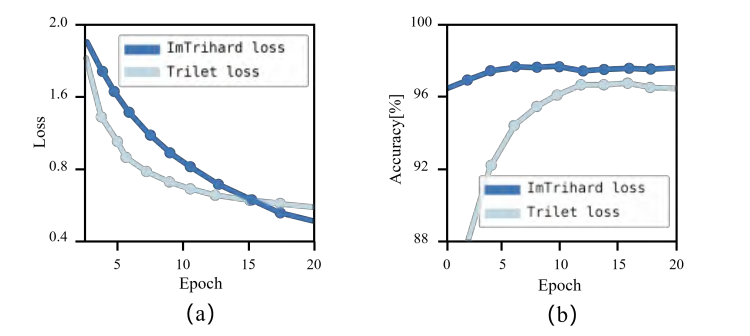 | ||
|
|
||
| 图8.两种损失函数的比较。 | ||
|
|
||
| ## V.结论 | ||
|
|
||
| 本文提出了一种新颖的基于激光雷达的定位网络,它利用了Mamba模型、一种处理RV的随机重建方法,以及一种简单的SPP架构。实验结果证明,即使只使用简单的信息输入,作者提出的OverlapMamba在三个公共数据集上的时间精度、复杂度和速度方面都可以优于其他最先进的算法,展现了其在LPR任务中的泛化能力以及在真实世界自动驾驶场景中的实用价值。 |
Oops, something went wrong.