This code is written in PyTorch 0.2. By the time the PyTorch has released their 1.0 version, there are plenty of outstanding seq2seq learning packages built on PyTorch, such as OpenNMT, AllenNLP and etc. You can learn from their source code.
Usage: Please refer to offical pytorch tutorial on attention-RNN machine translation, except that this implementation
handles batched inputs, and that it implements a slightly different attention mechanism.
To find out the formula-level difference of implementation, illustrations below will help a lot.
PyTorch version mechanism illustration, see here:
http://pytorch.org/tutorials/_images/decoder-network.png
PyTorch offical Seq2seq machine translation tutorial:
http://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html
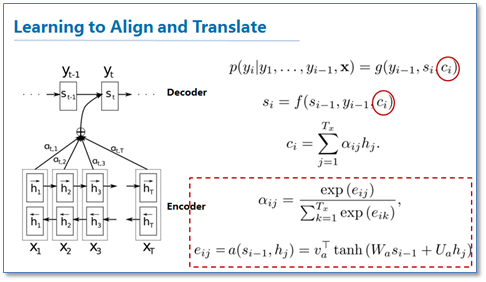
Bahdanau attention illustration, see here:
http://images2015.cnblogs.com/blog/670089/201610/670089-20161012111504671-910168246.png
PyTorch version attention decoder fed "word_embedding" to compute attention weights,
while in the origin paper it is supposed to be "encoder_outputs". In this repository,
we implemented the origin attention decoder according to the paper
{kind=link}
{kind=link}
Update: dynamic encoder added and does not require inputs to be sorted by length in a batch.
PyTorch supports element-wise fetching and assigning tensor values during procedure, but actually it is slow especially when running on GPU. In a tutorial(https://github.com/spro/practical-pytorch),
attention values are assigned element-wise; it's absolutely correct(and intuitive from formulas in paper), but slow on our GPU.
Thus, we re-implemented a real batched tensor manipulating version, and it achieves more than 10X speed improvement.
This code works well on personal projects.