Chang Liu, Rui Li, Kaidong Zhang, Yunwei Lan, Dong Liu
[Paper] / [Project] / [Models (Huggingface)] / [DAVIS-Edit (HuggingFace)] / [Models (wisemodel)] / [DAVIS-Edit (wisemodel)] / [Models (ModelScope)] / [DAVIS-Edit (ModelScope)]
- 1. Overview of
StableV2V - 2. News
- 3. To-Do Lists
- 4. Code Structure
- 5. Prerequisites
- 6. Inference of
StableV2V(Command Lines) - 7. Inference of
StableV2V(Gradio Demo) - 8. Details of
DAVIS-Edit - 9. Training the Shape-guided Depth Refinement Network
- 10. Citation
- 11. Results
- 12. Star History
- 13. Acknowledgements
If you have any questions about this work, please feel free to start a new issue or propose a PR.
StableV2V presents a novel paradigm to perform video editing in a shape-consistent manner, especially handling the editing scenarios when user prompts cause significant shape changes to the edited contents.
Besides, StableV2V shows superior flexibility in handling a wide series of down-stream applications, considering various user prompts from different modalities.
- [Nov. 27th] We uploaded our model weights and the proposed testing benchmark
DAVIS-Editto ModelScope. - [Nov. 21th] We updated a Gradio demo for interactive use of
StableV2V, with detailed illustrations presented in this section. - [Nov. 20th] We uploaded our model weights and the proposed testing benchmark
DAVIS-Editto wisemodel.cn. - [Nov. 19th] We have updated
DAVIS-Editto our HuggingFace dataset repo, and uploaded all the required model weights ofStableV2Vto our HuggingFace model repo. - [Nov. 19th] Our arXiv paper is currently released.
- [Nov. 18th] We updated the codebase of StableV2V.
- [Nov. 17th] We updated our project page.
- Update the codebase of
StableV2V - Upload the curated testing benchmark
DAVIS-Editto our HuggingFace repo - Upload all required model weights of
StableV2Vto our HuggingFace repo - Update a Gradio demo
- Regular Maintainence
StableV2V
├── LICENSE
├── README.md
├── assets
├── datasets <----- Code of datasets for training of the depth refinement network
├── models <----- Code of model definitions in different components
├── runners <----- Code of engines to run different components
├── inference.py <----- Script to inference StableV2V
├── train_completion_net.py <----- Script to train the shape-guided depth completion network
└── utils <----- Code of toolkit functions
We offer an one-click command line to install all the dependencies that the code requires.
First, create the virtual environment with conda:
conda create -n stablev2v python=3.10Then, you can execute the following lines to install the dependencies with pip:
bash install_pip.shYou can also install the dependencies with conda, following the command line below:
bash install_conda.shThen, you are ready to go with conda activate stablev2v.
Before you start the inference process, you need to prepare the model weights that StableV2V requires.
We uploaded all model weights that `StableV2V` requires to our HuggingFace repo. Besides, you can also get access to them in their official releases, where we provide the corresponding details in the following table.
| Model | Component | Link |
|---|---|---|
| Paint-by-Example | PFE | Fantasy-Studio/Paint-by-Example |
| InstructPix2Pix | PFE | timbrooks/instruct-pix2pix |
| SD Inpaint | PFE | botp/stable-diffusion-v1-5-inpainting |
| ControlNet + SD Inpaint | PFE | ControlNet models at lllyasviel |
| AnyDoor | PFE | xichenhku/AnyDoor |
| RAFT | ISA | Google Drive |
| MiDaS | ISA | Link |
| U2-Net | ISA | Link |
| Depth Refinement Network | ISA | Link |
| SD v1.5 | CIG | stable-diffusion-v1-5/stable-diffusion-v1-5 |
| ControlNet (depth) | CIG | lllyasviel/control_v11f1p_sd15_depth |
| Ctrl-Adapter | CIG | hanlincs/Ctrl-Adapter (i2vgenxl_depth) |
| I2VGen-XL | CIG | ali-vilab/i2vgen-xl |
Once you downloaded all the model weights, put them in the checkpoints folder.
Note
If your network environment can get access to HuggingFace, you can directly use the HuggingFace repo ID to download the models. Otherwise we highly recommend you to prepare the model weights locally.
Specfically, make sure you modify the configuration file of AnyDoor at models/anydoor/configs/anydoor.yaml with the path of DINO-v2 pre-trained weights:
(at line 83)
cond_stage_config:
target: models.anydoor.ldm.modules.encoders.modules.FrozenDinoV2Encoder
weight: /path/to/dinov2_vitg14_pretrain.pth
You may refer to the following command line to run StableV2V:
python inference.py --raft-checkpoint-path checkpoints/raft-things.pth --midas-checkpoint-path checkpoints/dpt_swin2_large_384.pt --u2net-checkpoint-path checkpoints/u2net.pth --stable-diffusion-checkpoint-path stable-diffusion-v1-5/stable-diffusion-v1-5 --controlnet-checkpoint-path lllyasviel/control_v11f1p_sd15_depth --i2vgenxl-checkpoint-path ali-vilab/i2vgen-xl --ctrl-adapter-checkpoint-path hanlincs/Ctrl-Adapter --completion-net-checkpoint-path checkpoints/depth-refinement/50000.ckpt --image-editor-type paint-by-example --image-editor-checkpoint-path /path/to/image/editor --source-video-frames examples/frames/bear --external-guidance examples/reference-images/raccoon.jpg --prompt "a raccoon" --outdir resultsFor detailed illustrations of the arguments, please refer to the table below.
| Argument | Default Setting | Required or Not | Explanation |
|---|---|---|---|
| Model arguments | - | - | - |
--image-editor-type |
- | Yes | Argument to define the image editor type. |
--image-editor-checkpoint-path |
- | Yes | Path of model weights for the image editor, required by PFE. |
--raft-checkpoint-path |
checkpoints/raft-things.pth |
Yes | Path of model weights for RAFT, required by ISA. |
--midas-checkpoint-path |
checkpoints/dpt_swin2_large_382.pt |
Yes | Path of model weights for MiDaS, required by ISA. |
--u2net-checkpoint-path |
checkpoints/u2net.pth |
Yes | Path of model weights for U2-Net, required by ISA to obtain the segmentation masks of video frames (will be replaced by SAM in near future) |
--stable-diffusion-checkpoint-path |
stable-diffusion-v1-5/stable-diffusion-v1-5 |
Yes | Path of model weights for SD v1.5, required by CIG. |
--controlnet-checkpoint-path |
lllyasviel/control_v11f1p_sd15_depth |
Yes | Path of model weights for ControlNet (depth) required by CIG. |
--ctrl-adapter-checkpoint-path |
hanlincs/Ctrl-Adapter |
Yes | Path of model weights for Ctrl-Adapter, required by CIG. |
--i2vgenxl-checkpoint-path |
ali-vilab/i2vgen-xl |
Yes | Path of model weights for I2VGen-XL, required by CIG. |
--completion-checkpoint-path |
checkpoints/depth-refinement/50000.ckpt |
Yes | Path of model weights for I2VGen-XL, required by CIG. |
| Input Arguments | - | - | - |
--source-video-frames |
- | Yes | Path of input video frames. |
--prompt |
- | Yes | Text prompt of the edited video. |
--external-guidance |
- | Yes | External inputs for the image editors if you use Paint-by-Example, InstructPix2Pix, and AnyDoor. |
--outdir |
results |
Yes | Path of output directory. |
--edited-first-frame |
- | No | Path of customized first edited frame, where the image editor will not be used if this argument is configured. |
--input-condition |
- | No | Path of cusromzied depth maps. We directly extract depth maps from the source video frames with MiDaS if this argument is not configured |
--input-condition |
- | No | Path of cusromzied depth maps. We directly extract depth maps from the source video frames with MiDaS if this argument is not configured. |
--reference-masks |
- | No | Path of segmentation masks of the reference image, required by AnyDoor. We will automatically extract segmentation mask from the reference image if this argument is not configured. |
--image-guidance-scale |
1.0 | No | Hyper-parameter required by InstructPix2Pix. |
--kernel-size |
9 | No | Kernel size of the binary dilation operation, to make sure that the pasting processes cover the regions of edited contents. |
--dilation-iteration |
1 | No | Iteration for binary dilation operation. |
--guidance-scale |
9.0 | No | Classifier-free guidance scale. |
--mixed-precision |
bf16 | No | Precision of models in StableV2V. |
--n-sample-frames |
16 | No | Number of video frames of the edited video. |
--seed |
42 | No | Random seed. |
Note
Some specific points that you may pay additional attentions to while inferencing:
- By configuring
--image-editor-checkpoint-path, the path will be automatically delievered to the corresponding editor according to your--image-editor-type. So please do not be worried about some extra arguments in the codebase. - If you are using
Paint-by-Example,InstructPix2Pix,AnyDoor, you are required to configure the--external-guidanceargument, which corresponds to reference image and user instruction accordingly. - Our method does not currently support
xformers, which might cause artifacts in the produced results. Such issue might be fixed in the future if possible.
So far, we have not found an efficient way to perform the sketch-based editing within one command line, thus we showcase our way in doing so for reference, where the procedures are shown below.
To obtain the human-drawn sketches, you need to manually draw them on external devices such as a tablet, and then export the result for later uses.
Particularly, we obtain the hand-drawn sketches on the iPad application Sketchbook. An example hand-drawn sketch might look like this:


Once you obtain the hand-drawn sketch, the next step is to get the first edited frame.
In doing so, we use ControlNet (scribble), where you need to prepare the model weights of ControlNet (scribble) and SD Inpaint in advance.
Suppose we put the previously hand-drawn sketches at inputs/hand-drawn-sketches, you can execute the following command line by running ControlNet (scribble):
python scripts/inference_controlnet_inpaint.py --controlnet-checkpoint-path lllyasviel/control_v11p_sd15_scribble --stable-diffusion-checkpoint-path botp/stable-diffusion-v1-5-inpainting --prompt "an elephant" --input-mask inputs/masks/bear.png --controlnet-guidance inputs/hand-drawn-sketches/bear-elephant-sketch.png --outdir results/sketch-guided-result.pngThe result might seem like:

Finally, you are ready to generate the entire edited video. We offer an example command line as follows:
python inference.py --raft-checkpoint-path checkpoints/raft-things.pth --midas-checkpoint-path checkpoints/dpt_swin2_large_384.pt --u2net-checkpoint-path checkpoints/u2net.pth --stable-diffusion-checkpoint-path stable-diffusion-v1-5/stable-diffusion-v1-5 --controlnet-checkpoint-path lllyasviel/control_v11f1p_sd15_depth --i2vgenxl-checkpoint-path ali-vilab/i2vgen-xl --ctrl-adapter-checkpoint-path hanlincs/Ctrl-Adapter --completion-net-checkpoint-path checkpoints/depth-refinement/50000.ckpt --source-video-frames examples/frames/bear --edited-first-frame inputs/edited-first-frames/bear-elephant.png --prompt "an elephant walking on the rocks in a zoo" --outdir results By configuring the --edited-first-frame, the codebase will automatically skip the first-frame editing process, where we visualize the source video and the edited video below:
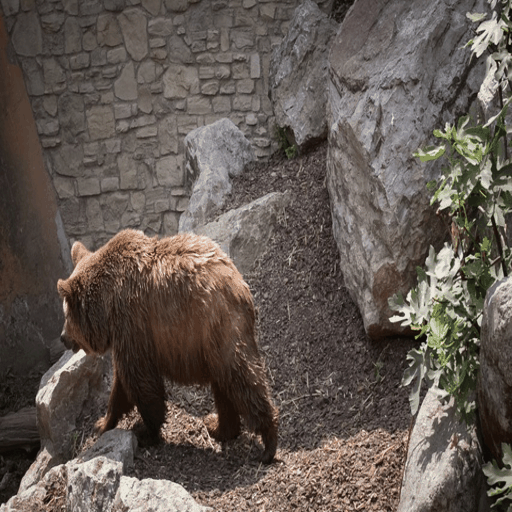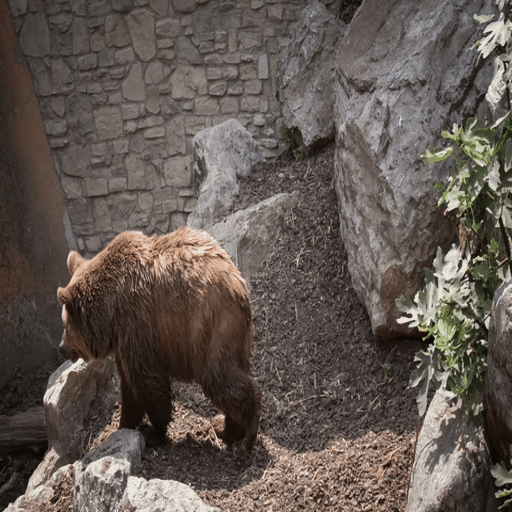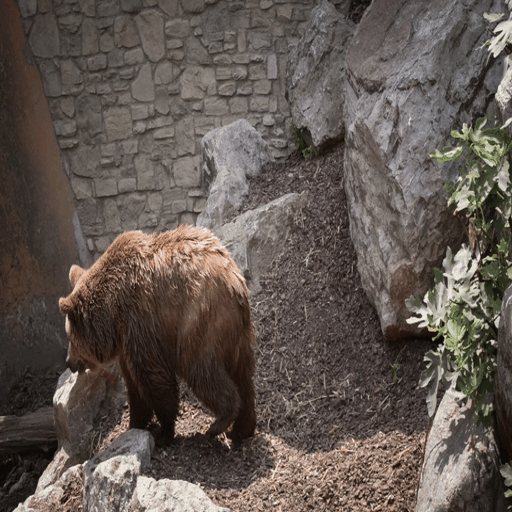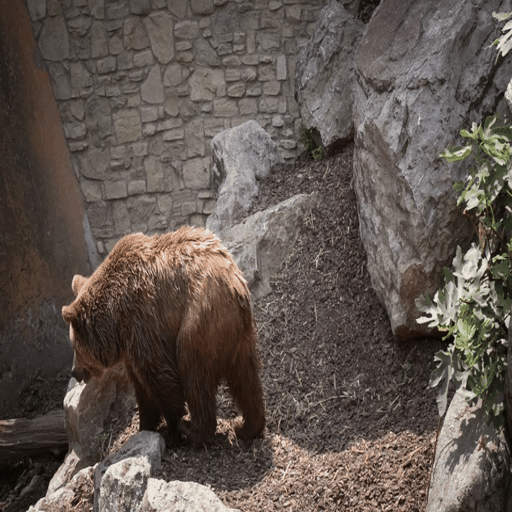

The application of video inpainting has similar problem to that of sketch-based editing, we have not found integrated solution so far. Thus, we showcase how we perform such application in the following contents for potential reference.
Before you inpaint the first video frame, we recommend you dilate the annotated segmentation mask (if any) using the following script:
python scripts/run_dilate_mask.py --input-folder inputs/masks/car-turn.png --output-folder inputs/dilated-masks --kernel-size 15 --iterations 1
The original (left) and dilated (right) masks might look like:


We recommend you to use the library IOPaint for convenient use. To install it, you can simply run:
pip install iopaintThen, you are able to execute LaMa through the library:
iopaint run --model=lama --image inputs/frames/car-turn/00000.jpg --mask inputs/dilated-masks/car-turn.png --output inputs/edited-first-frames/
The original and inpainted first frames might look like:


Finally, you are ready to generate the entire edited video. We offer an example command line as follows:
python inference.py --raft-checkpoint-path checkpoints/raft-things.pth --midas-checkpoint-path checkpoints/dpt_swin2_large_384.pt --u2net-checkpoint-path checkpoints/u2net.pth --stable-diffusion-checkpoint-path stable-diffusion-v1-5/stable-diffusion-v1-5 --controlnet-checkpoint-path lllyasviel/control_v11f1p_sd15_depth --i2vgenxl-checkpoint-path ali-vilab/i2vgen-xl --ctrl-adapter-checkpoint-path hanlincs/Ctrl-Adapter --completion-net-checkpoint-path checkpoints/depth-refinement/50000.ckpt --source-video-frames examples/frames/car-turn --edited-first-frame inputs/edited-first-frame/car-turn-inpainted.png --prompt "an elephant walking on the rocks in a zoo" --outdir results By configuring the --edited-first-frame, the codebase will automatically skip the first-frame editing process, where we visualize the source video and the edited video below:


We also offer a gradio demo to try StableV2V through interactive UI. Before you go, we recommend you to follow the instructions in this section to prepare all the required model weights locally (in the ./checkpoints folder). Then, feel free to test it out by simply running:
python app.pyIn the following figure, we illustrate the functions of different modules in our Gradio demo:
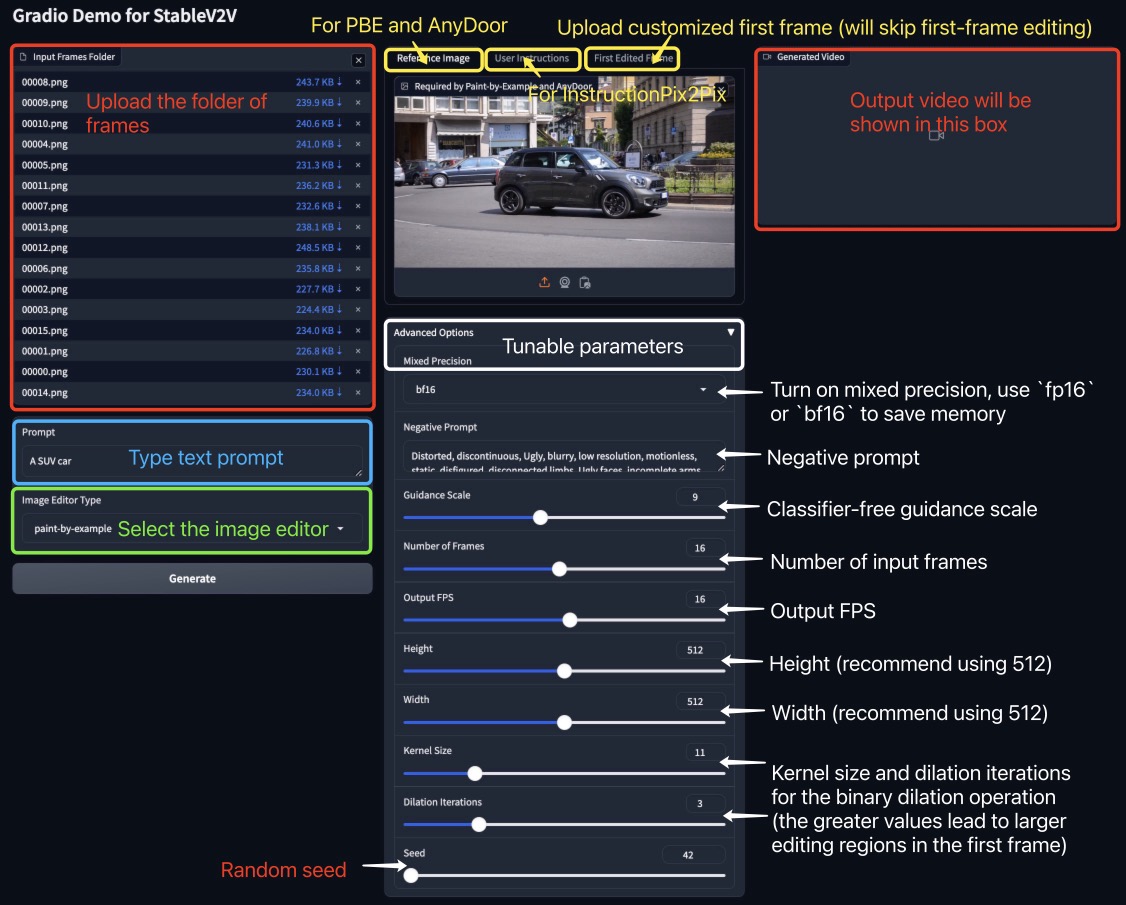
Please do not hesitate to start a new issue or propose a PR if have any further questions about the demo.
We illustrate more details of the curated testing benchmark `DAVIS-Edit` below, where you can get access to the dataset in our HuggingFace repo.
We construct DAVIS-Edit following the same data structure as the one of DAVIS, as is shown below:
DAVIS-Edit
├── Annotations <----- Official annotated masks of DAVIS
├── bear
├── blackswan
├── ...
└── train
├── JPEGImages <----- Official video frames of DAVIS
├── bear
├── blackswan
├── ...
└── train
├── ReferenceImages <----- Annotated reference images for image-based editing on DAVIS-Edit
├── bear.png
├── blackswan.png
├── ...
└── train.png
├── .gitattributes
├── README.md
├── edited_video_caption_dict_image.json <----- Annotated text descriptions for image-based editing on DAVIS-Edit
└── edited_video_caption_dict_text.json <----- Annotated text descriptions for text-based editing on DAVIS-Edit
Specifically, edited_video_caption_dict_image.json and edited_video_caption_dict_text.json are constructed as Python dictionary, with its keys as the names of video folders in JPEGImages. For example in edited_video_caption_dict_text.json:
{
"bear": {
"original": "a bear walking on rocks in a zoo",
"similar": "A panda walking on rocks in a zoo",
"changing": "A rabbit walking on rocks in a zoo"
},
# ...
}The annotations of reference images contain two sub-folders, i.e., similar and changing, corresponding to the annotations for DAVIS-Edit-S and DAVIS-Edit-C, respectively, where the structure are constructed in the same folder name as that in JPEGImages.
We highly recommend you to index different elements in DAVIS-Edit through the annotation files. Particularly, you may refer to the script below:
import os
import json
from tqdm import tqdm
from PIL import Image
# TODO: Modify the configurations here to your local paths
frame_root = 'JPEGImages'
mask_root = 'Annotations'
reference_image_root = 'ReferenceImages/similar' # Or 'ReferenceImages/changing'
annotation_file_path = 'edited_video_caption_dict_text.json'
# Load the annotation file
with open(annotation_file_path, 'r') as f:
annotations = json.load(f)
# Iterate all data samples in DAVIS-Edit
for video_name in tqdm(annotations.keys()):
# Load text prompts
original_prompt = annotations[video_name]['original']
similar_prompt = annotations[video_name]['similar']
changing_prompt = annotations[video_name]['changing']
# Load reference images
reference_image = Image.open(os.path.join(reference_image_root, video_name + '.png'))
# Load video frames
video_frames = []
for path in sorted(os.listdir(os.path.join(frame_root, video_name))):
if path != 'Thumbs.db' and path != '.DS_store':
video_frames.append(Image.open(os.path.join(frame_root, path)))
# Load masks
masks = []
for path in sorted(os.listdir(os.path.join(mask_root, video_name))):
if path != 'Thumbs.db' and path != '.DS_store':
masks.append(Image.open(os.path.join(frame_root, path)))
# (add further operations that you expect in the lines below)We have open-sourced the pre-trained model weights of the proposed shape-guided depth refinement network in our HuggingFace repo, where you are free to use `StableV2V` with it. Meanwhile, we offer the specific procedures to perform cutomized training for the refinement network, with details listed below.
We use YouTube-VOS to conduct the training process of our shape-guided depth refinement network.
Before you start the training process, you need to first download its source videos and annotations from this link.
Once downloaded, the data follows the structures below:
youtube-vos
├── JPEGImages <----- Path of source video frames
├── Annotations <----- Path of segmentation masks
└── meta.json <----- Annotation file for the segmentation masks
Once the video frames are ready, the next step is to annotate their corresponding depth maps.
Specifically, make sure you download the MiDaS model weights from this link.
Then, you can execute the following command lines with our automatic script:
python scripts/extract_youtube_vos_depths.py --midas-path checkpoints/dpt_swin2_large_384.pt --dataset-path data/youtube-vos/JPEGImages --outdir data/youtube-vos/DepthMapsOur depth refinement network uses an additional network channel to take the first-frame shape mask as guidance, thus you need to annotate them for the YouTube-VOS dataset.
First, make sure you download the U2-Net model weights from this link.
Then, you execute the following command lines with our automatic script:
python scripts/extract_youtube_vos_shapes.py --video-root data/youtube-vos/JPEGImages --model-dir checkpoints/u2net.pth --outdir data/youtube-vos/FirstFrameMasksFinally, you are ready to execute the training process with the following command line:
python train_completion_net.py --video-path data/youtube-vos/JPEGImages --shape-path data/youtube-vos/FirstFrameMasks --max-train-steps 50000 --outdir results/shape-guided-depth-refinement --checkpoint-freq 2000 --validation-freq 200The trained model weights will be saved at results/checkpoints, and the visualizations of intermediate results can be checked via tensorboard, with the logs saved at results/tensorboard.
Please refer to our project page for more results and comparisons performed by StableV2V.
If you find this work helpful to your research, or use our testing benchmark DAVIS-Edit, please cite our paper:
@misc{liu-etal-2024-stablev2v,
title={StableV2V: Stablizing Shape Consistency in Video-to-Video Editing},
author={Chang Liu and Rui Li and Kaidong Zhang and Yunwei Lan and Dong Liu},
year={2024},
eprint={2411.11045},
archivePrefix={arXiv},
primaryClass={cs.CV},
}
This repo is heavily modified based on Diffusers, Ctrl-Adapter, AnyDoor, and RAFT. We sincerely thanks the authors for their fantasitic implementations.