The reMarkable device is a sleek, minimalist e-ink tablet designed to replicate the feel of writing on paper while providing the benefits of digital tools. It is primarily used by writers, artists, and professionals for notetaking, sketching, and reading. Its distraction-free interface distinguishes it from conventional tablets [1].
Integrating large language model (LLM) support into the reMarkable device could unlock transformative use cases. For example, LLMs could enhance the writing experience with intelligent features such as auto-completion for user inputs, grammar and style corrections, contextual suggestions, and summarization & paraphrasing of handwritten or typed notes. These functionalities would not only boost productivity but also improve the overall user experience, making the device an even more powerful tool for creative and professional tasks.
Porting support for LLMs to a device like the reMarkable 2 presents a significant technical challenge due to its limited hardware capabilities, which include only 1GB of RAM and a Freescale i.MX7 series 1GHz dual-core CPU. These specifications are modest compared to the requirements of modern LLMs, which typically demand much higher computational power and memory. To address this gap, several strategies must be employed to adapt LLMs for constrained environments while gaining acceptable performance and usability.
Due to the limited processing power of the i.MX7 CPU, we opted for a hybrid processing approach. More computationally intensive tasks, such as generating initial context embeddings or processing longer inputs, can be offloaded to an external server (cloud) or companion device (fog). Meanwhile, the reMarkable 2 is capable of handling lighter tasks, such as applying pre-generated suggestions and performing fine-grained local optimizations. A seamless communication protocol will ensure that these tasks are offloaded and retrieved with minimal latency, thereby preserving the device's responsiveness.
This architecture involves hosting the Large Language Model Meta AI (LLAMA) server on a cloud or local network node while deploying a lightweight native client on reMarkable 2.
- For enterprise clients, this could be a shared internal server instance or cloud.
- For personal clients, this could be an embedded plugin in reMarkable desktop app.
We chose LLAMA because it delivers state-of-the-art performance while optimizing resource usage [2]. LLAMA models come in various parameter sizes, from smaller models suitable for edge deployment to larger, high-performance versions. The model uses attention mechanisms to process sequences of text, making it ideal for applications such as text generation, grammar correction, and summarization. Its modular design facilitates efficient scaling, and with techniques like quantization and distillation, LLAMA models can be optimized for constrained environments, making them a good fit for this client-server setup.
To set up the server, we will use TinyLLM. To run an LLM, we need an inference server for the model. For this purpose, we will use llama-cpp-server, which is a Python wrapper around llama.cpp. This is an efficient C++ implementation of Meta's LLAMA models, designed to run on CPUs.
We deployed the server with the following parameters and commands mentioned below. Since we do not have CUDA support in our deployment environment, we have disabled all GPU-related optimizations in this deployment.
git cone https://github.com/jasonacox/TinyLLM.git
cd TinyLLM
CMAKE_ARGS="-DLLAMA_CUBLAS=off" FORCE_CMAKE=1 pip3 install llama-cpp-python==0.2.27 --no-cache-dir
CMAKE_ARGS="-DLLAMA_CUBLAS=off" FORCE_CMAKE=1 pip3 install llama-cpp-python[server]==0.2.27 --no-cache-dir
For the initial deployment of the LLM powered server, we are using Meta's LLaMA-2 7B GGUF Q5_0 model obtained from Hugging Face.
This 7B model contains around 7 billion parameters, making it the smallest version in the LLaMA-2 family. It is designed for efficient inference while preserving strong natural language understanding and generation capabilities [3].
The Q5_0 quantization scheme uses a 5-bit format for weights, effectively balancing compression with inference quality. This approach is suitable for applications that demand both high accuracy and lower resource consumption [3][4].
To download the model:
cd llmserver/models
wget https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF/resolve/main/llama-2-7b-chat.Q5_K_M.gguf
To run the model:
python3 -m llama_cpp.server --model ./models/llama-2-7b-chat.Q5_K_M.gguf --host localhost --n_gpu_layers 99 --n_ctx 2048 --chat_format llama-2
The reMarkable device at 99x comes with reMarkable OS version 3.3.2.1666. The appropriate toolchain can be found at the https://remarkable.guide/devel/toolchains.html#official-toolchain.
To develop the client application for the reMarkable 2, we set up a cross-compilation environment using the SDK's GCC toolchain and sysroot. The sysroot contains the necessary libraries, headers, and runtime environment for the device, ensuring binary compatibility. Development takes place on a host machine, where the GCC toolchain compiles the code specifically for the ARM architecture of the reMarkable 2.
arm-remarkable-linux-gnueabi-gcc toolchain is used to compile C/C++ code for the ARM Cortex-A7 architecture with appropriate compiler flags:
arm-remarkable-linux-gnueabi-gcc -mfpu=neon -mfloat-abi=hard -mcpu=cortex-a7 --sysroot=$SDKTARGETSYSROOT
Initially, we considered using liboai, a modern C++ library designed for integration with OpenAI. However, this library relies on advanced features from C++17 and C++20, which are not supported by the version of GCC included with the reMarkable SDK. To address this limitation, we decided to develop the client application from scratch, ensuring full compatibility with the available toolchain. Despite this, our implementation was significantly influenced by the architecture and design principles of liboai, including its use of asynchronous HTTP handling and structured API wrappers.
Core functionalities such as HTTP request handling, JSON parsing, and API endpoint interaction have been reimplemented in C. A custom HTTP client was developed using cURL, ensuring efficient request handling and secure connections through OpenSSL.
To cross compile cURL:
. /opt/codex/rm11x/3.1.2/environment-setup-cortexa7hf-neon-remarkable-linux-gnueabi
git clone https://github.com/curl/curl.git
cd curl/
./buildconf
./configure --host=arm-linux --without-libpsl --with-openssl --prefix=/opt/codex/rm11x/3.1.2/sysroots/cortexa7hf-neon-remarkable-linux-gnueabi
make -j8
make install
JSON parsing was performed using nlohmann/json, compiled for the target environment and statically linked with the client application.
git clone https://github.com/nlohmann/json.git
cd json
mkdir build
cd build
cmake -DCMAKE_INSTALL_PREFIX:PATH=/opt/codex/rm11x/3.1.2/sysroots/cortexa7hf-neon-remarkable-linux-gnueabi ..
make -j8
make install
After completing the previous steps, the build environment is prepared to compile the client application. Follow the steps below to compile the client application:
git clone [email protected]:99x-incubator/remarkable-2-llm.git
cd remarkable-2-llm/rm2-client/
make
After the compilation, the resulting binary at /remarkable-2-llm/rm2-client/bin was transferred to the reMarkable 2 using SCP via the emulated network interface over USB.
(Questions are obtained from https://www.kaggle.com/datasets/satishgunjal/grammar-correction).
[Case 499] - Spelling Mistakes:

[Case 175] - Subject-Verb Agreement:

[Case 61] - Verb Tense Errors:

[Case 236] - Article Usage:

[Case 319] - Preposition Usage:

[Case 803] - Sentence Fragments:

[Case 748] - Run-on Sentences:

[Case 410] - Sentence Structure Errors:

During testing, we observed that the LLaMA-2 7B GGUF Q5_0 model occasionally experienced higher latency when handling complex or lengthy queries. To address this issue, we evaluated the LLaMA-3.2-3B, a newer and smaller model [6] with 3 billion parameters, which is optimized for both inference speed and accuracy. This alternative model showed a significant improvement in response times while maintaining or even enhancing the quality of outputs for typical use cases, such as text completion and grammar correction.
Performance results with LLAMA2 for 4 queries:
Performance results with LLAMA3 for same 4 queries:
The LLaMA-3.2-3B model was deployed into our existing server infrastructure with minimal modifications. The GUFF formatted model was obtained from Hugging Face.
wget https://huggingface.co/jayakody2000lk/Llama-3.2-3B-Q5_K_M-GGUF/resolve/main/llama-3.2-3b-q5_k_m.gguf
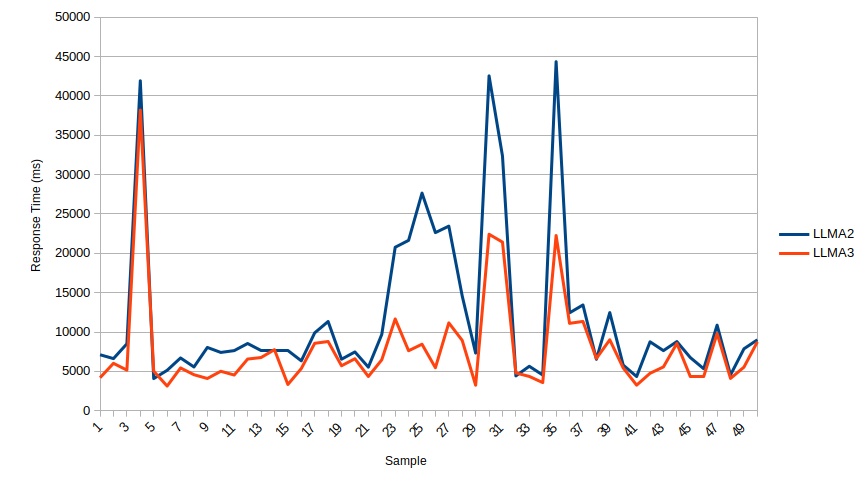
The table below displays the response times for the LLAMA2 and LLAMA3 models when performing grammar correction and summarization tasks. This test was conducted on a system equipped with an 11th Generation Intel® Core™ i7 Processor (1185G7) and 16GB of RAM, without any hardware acceleration.
To improve output quality and contextual relevance for reMarkable 2, we have integrated SummLlama3, a specialized version of the LLaMA-3 series that is fine-tuned for summarization, concise completions, and content refinement tasks [7].
SummLlama3 is optimized for generating structured and precise responses, making it ideal for summarizing handwritten notes, refining user inputs, or creating concise and accurate text completions. By leveraging its fine-tuning capabilities, the model produces outputs that closely align with the reMarkable 2's emphasis on productivity and note-taking.
wget https://huggingface.co/jayakody2000lk/SummLlama3.2-3B-Q5_K_M-GGUF/resolve/main/summllama3.2-3b-q5_k_m.gguf
Sample results of SummLlama3 with the few datasets available in Hugging Face:
[Case 955] - Pronoun Errors:

[Case 998] - Conjunction Misuse:

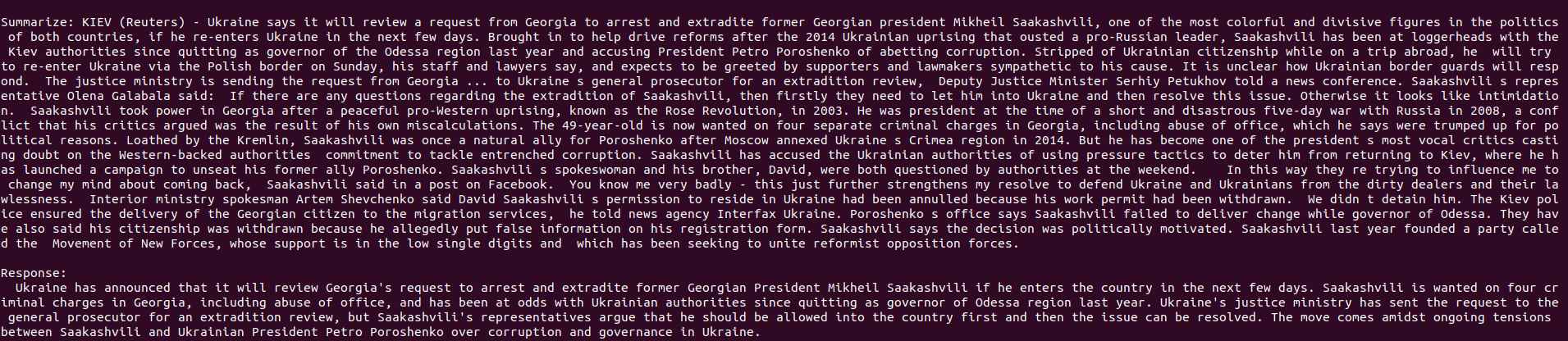
Summarize input strings:

Summarize input strings:
One of the first steps in adapting an LLM for the reMarkable 2 or other small-scale embedded devices is model quantization. This process reduces the precision of the model weights from 32-bit floating-point numbers to lower precisions, such as 8-bit or even 4-bit integers [5]. This change significantly decreases memory usage and computational overhead [4]. Additionally, pruning can eliminate less critical parameters, further reducing the model's size without a substantial loss in accuracy. These optimizations can make the model small enough to fit within the device's 1GB RAM while still maintaining essential functionalities like auto-completion and grammar correction.
As part of our further research, we plan to test smaller, edge-optimized LLMs, including distilled versions of popular architectures, such as DistilBERT or GPT-NeoX-tiny. Distillation compresses larger models by training a smaller model to emulate the behavior of a larger one [8]. These smaller architectures are specifically designed to balance performance and efficiency, allowing them to operate on resource-constrained devices like the reMarkable 2.
[1] ReMarkable. (2023). "reMarkable 2: The Paper Tablet." ReMarkable Official Website. Retrieved from [https://remarkable.com]
[2] Meta AI. (2023). "LLaMA: Open and Efficient Foundation Language Models." Meta AI Research. Retrieved from [https://arxiv.org/abs/2302.13971]
[3] LLaMA-2 Model Documentation. (2023). Hugging Face. Retrieved from [https://huggingface.co/docs/transformers/en/model_doc/llama2]
[4] Gerganov, G. (2023). "Optimizing LLaMA Models for Efficiency.” GitHub. Retrieved from https://github.com/ggerganov/llama.cpp
[5] Mengzhao Chen, Wenqi Shao, Peng Xu, Jiahao Wang, Peng Gao, Kaipeng Zhang, Ping Luo. (2024). " EfficientQAT: Efficient Quantization-Aware Training for Large Language Models." arxiv. Retrieved from [https://arxiv.org/pdf/2407.11062]
[6] Meta AI. (2024). "Introducing LLaMA-3: Advancements in Scalable Language Models." Meta AI Research. Retrieved from [https://ai.meta.com/blog/meta-llama-3/]
[7] Hwanjun Song, Taewon Yun, Yuho Lee, Gihun Lee, Jason Cai, Hang Su. (2024). “Learning to Summarize from LLM-generated Feedback.” arxiv. Retrieved from [https://arxiv.org/pdf/2410.13116]
[8] Victor Sanh, Lysandre Debut, Julien Chaumond, Thomas Wolf. (2019). “DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.” arxiv. Retrieved from [https://arxiv.org/pdf/1910.01108]